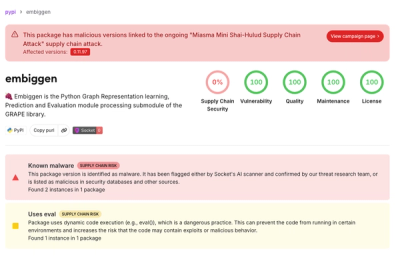
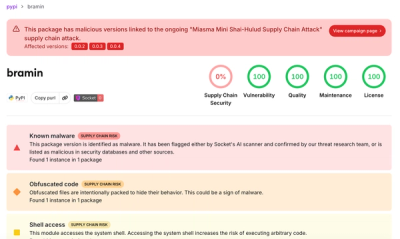
@llmist/cli



Command-line interface for llmist - run LLM agents from the terminal.
Installation
npm install -g @llmist/cli
npx @llmist/cli
Quick Start
export OPENAI_API_KEY="sk-..."
llmist complete "Explain TypeScript generics in one paragraph"
llmist agent "Search for files" --gadgets ./my-gadgets/
llmist chat
Commands
complete <prompt> | One-shot LLM completion |
agent <prompt> | Run agent with gadgets |
chat | Interactive chat session |
tui | Launch terminal UI |
Using Gadgets
Load gadgets from various sources:
llmist agent "Do something" --gadgets ./gadgets/
llmist agent "Search the web" --gadgets dhalsim/BrowseWeb
llmist agent "Process files" --gadgets github:user/repo
Configuration
Create a llmist.toml file for reusable configurations:
[agent]
model = "sonnet"
system = "You are a helpful assistant"
[gadgets]
paths = ["./gadgets"]
external = ["dhalsim/BrowseWeb"]
[display]
markdown = true
colors = true
Use with:
llmist agent "Do something" --config ./llmist.toml
Rate Limiting
llmist CLI enables conservative rate limiting by default to prevent hitting provider API limits and avoid agent crashes.
Default Behavior
Rate limits are automatically configured based on your model's provider:
| Anthropic | 50 | 40,000 | - |
| OpenAI | 3 | 40,000 | - |
| Gemini | 15 | 1,000,000 | 1,500,000 |
These defaults are conservative (protecting free tier users). Paid tier users should configure higher limits.
Configuration
TOML Config (~/.llmist/cli.toml or project llmist.toml):
[rate-limits]
enabled = true
requests-per-minute = 100
tokens-per-minute = 200_000
safety-margin = 0.8
[profile-gemini]
model = "gemini:flash"
[profile-gemini.rate-limits]
requests-per-minute = 15
tokens-per-day = 1_500_000
[profile-fast]
model = "gpt4o"
[profile-fast.rate-limits]
enabled = false
CLI Flags (override all config):
llmist agent --rate-limit-rpm 100 --rate-limit-tpm 200000 "your prompt"
llmist agent --no-rate-limit "your prompt"
llmist agent --max-retries 5 --retry-min-timeout 2000 "your prompt"
llmist agent --no-retry "your prompt"
TUI Feedback
The Terminal UI provides real-time feedback when rate limiting is active:
- Status Bar: Shows
⏸ Throttled Xs when waiting for rate limits
- Status Bar: Shows
🔄 Retry 2/3 during retry attempts
- Conversation Log: Persistent entries like:
⏸ Rate limit approaching (45 RPM, 85K TPM), waiting 5s...
🔄 Request failed (attempt 1/3), retrying...
Finding Your Tier Limits
To configure optimal limits for your API tier:
Check your provider dashboard for current tier limits, then update your llmist.toml accordingly.
Terminal UI
The TUI provides an interactive interface to browse execution history, inspect raw payloads, and debug agent runs:
llmist tui
Documentation
Full documentation at llmist.dev/cli
Related Packages
License
MIT