AFS2-DataSource SDK
The AFS2-DataSource SDK package allows developers to easily access PostgreSQL, MongoDB, InfluxDB, S3 and APM.
Installation
Support Python version 3.6 or later
pip install afs2-datasource
Development
pip install -e .
Notice
AFS2-DataSource SDK uses asyncio package, and Jupyter kernel is also using asyncio and running an event loop, but these loops can't be nested.
(https://github.com/jupyter/notebook/issues/3397)
If using AFS2-DataSource SDK in Jupyter Notebook, please add the following codes to resolve this issue:
!pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()
API
DBManager
Init DBManager
With Database Config
Import database config via Python.
from afs2datasource import DBManager, constant
manager = DBManager(db_type=constant.DB_TYPE['MYSQL'],
username=username,
password=password,
host=host,
port=port,
database=database,
querySql="select {field} from {table}"
)
manager = DBManager(db_type=constant.DB_TYPE['SQLSERVER'],
username=username,
password=password,
host=host,
port=port,
database=database,
querySql="select {field} from {table}"
)
manager = DBManager(db_type=constant.DB_TYPE['POSTGRES'],
username=username,
password=password,
host=host,
port=port,
database=database,
querySql="select {field} from {schema}.{table}"
)
manager = DBManager(db_type=constant.DB_TYPE['MONGODB'],
username=username,
password=password,
host=host,
port=port,
database=database,
collection=collection,
querySql="{}"
)
manager = DBManager(db_type=constant.DB_TYPE['INFLUXDB'],
username=username,
password=password,
host=host,
port=port,
database=database,
querySql="select {field_key} from {measurement_name}"
)
manager = DBManagerdb_type=constant.DB_TYPE['ORACLEDB'],
username=username,
password=password,
host=host,
port=port,
database=database,
querySql="select {field_key} from {measurement_name}"
)
manager = DBManager(db_type=constant.DB_TYPE['S3'],
endpoint=endpoint,
access_key=access_key,
secret_key=secret_key,
is_verify=False,
buckets=[{
'bucket': 'bucket_name',
'blobs': {
'files': ['file_name'],
'folders': ['folder_name']
}
}]
)
manager = DBManager(db_type=constant.DB_TYPE['AWS'],
access_key=access_key,
secret_key=secret_key,
buckets=[{
'bucket': 'bucket_name',
'blobs': {
'files': ['file_name'],
'folders': ['folder_name']
}
}]
)
manager = DBManager(db_type=constant.DB_TYPE['APM'],
username=username,
password=password,
apmUrl=apmUrl,
apm_config=[{
'name': name
'machines': [{
'id': machine_id
}],
'parameters': [
parameter1,
parameter2
]
}],
mongouri=mongouri,
timeRange=[{'start': start_ts, 'end': end_ts}],
timeLast={'lastDays': lastDay, 'lastHours': lastHour, 'lastMins': lastMin}
)
manager = DBManager(db_type=constant.DB_TYPE['AZUREBLOB'],
account_name=account_name,
account_key=account_key,
containers=[{
'container': container_name,
'blobs': {
'files': ['file_name']
'folders': ['folder_name']
}
}]
)
manager = DBManager(db_type=constant.DB_TYPE['DATAHUB'],
username=username,
password=password,
datahub_url=datahub_url,
datahub_config=[{
"name": "string",
"project_id": "project_id",
"node_id": "node_id",
"device_id": "device_id",
"tags": [
"tag_name"
]
}],
uri=mongouri,
timeRange=[{'start': start_ts, 'end': end_ts}],
timeLast={'lastDays': lastDay, 'lastHours': lastHour, 'lastMins': lastMin}
)
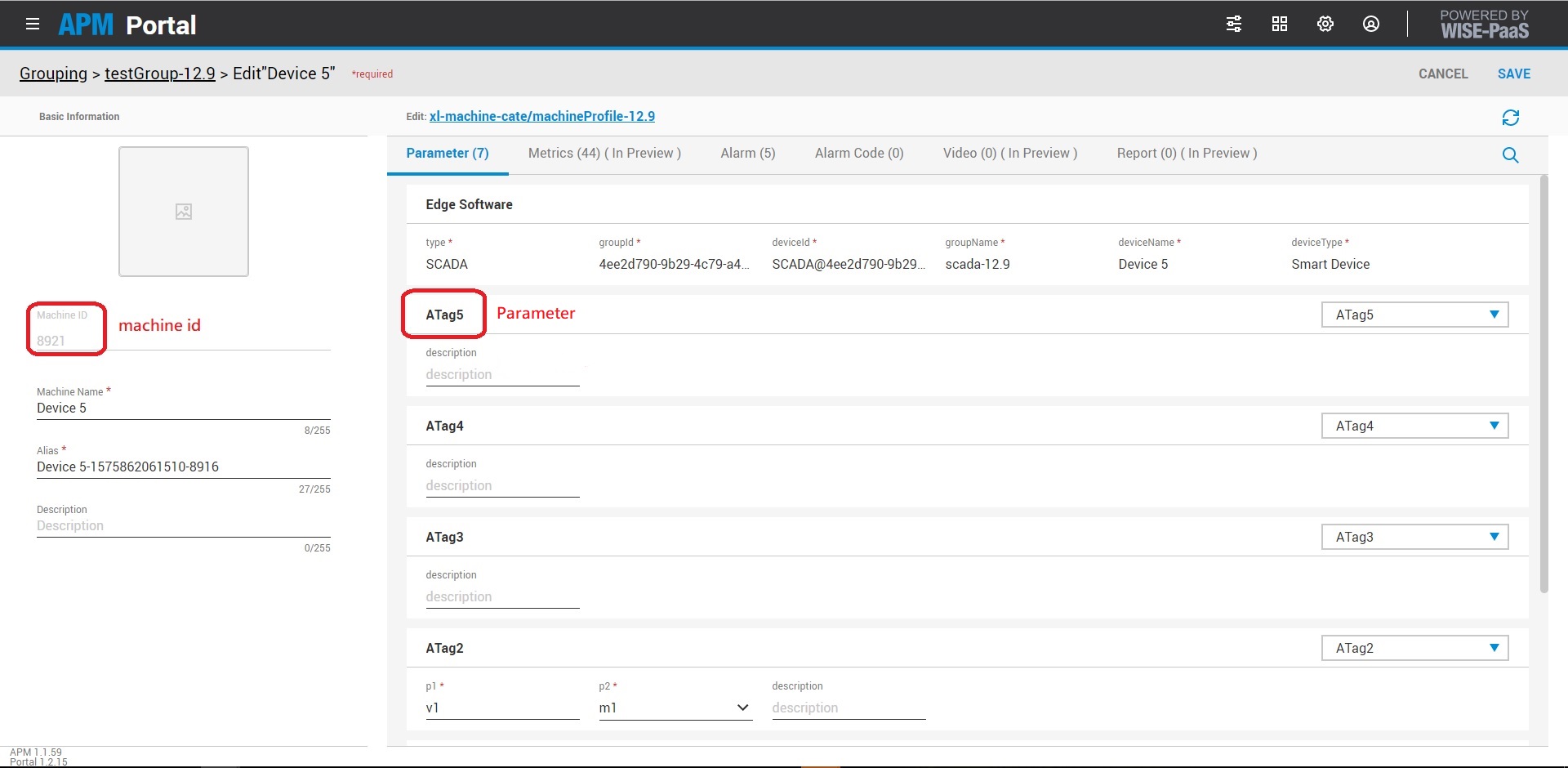
How to get APM machine id and parameters
How to get DataHub project id, node id, device id and tag

DBManager.connect()
Connect to MySQL, PostgreSQL, MongoDB, InfluxDB, S3, APM with specified by the given config.
manager.connect()
DBManager.disconnect()
Close the connection.
Note S3 datasource not support this function.
manager.disconnect()
DBManager.is_connected()
Return if the connection is connected.
manager.is_connected()
DBManager.is_connecting()
Return if the connection is connecting.
manager.is_connecting()
DBManager.get_dbtype()
Return database type of the connection.
manager.get_dbtype()
DBManager.get_query()
Return query in the config.
manager.get_query()
"""
select {field} from {table} {condition}
"""
"""
select {field} from {schema}.{table}
"""
"""
{"{key}": {value}}
"""
"""
select {field_key} from {measurement_name}
"""
"""
[{
'bucket': 'bucket_name',
'blobs': {
'files': ['file_name'],
'folders': ['folder_name']
}
}]
"""
"""
[{
'container': container_name,
'blobs': {
'files': ['file_name']
'folders': ['folder_name']
}
}]
"""
"""
{
'apm_config': [{
'name': name # dataset name
'machines': [{
'id': machine_id # node_id in APM
}],
'parameters': [
parameter1, # parameter in APM
parameter2
]
}],
'time_range': [{'start': start_ts, 'end': end_ts}],
'time_last': {'lastDays': lastDay, 'lastHours': lastHour, 'lastMins': lastMin}
}
"""
"""
{
'config': [{
"name": "string", # dataset name
"project_id": "project_id",
"node_id": "node_id",
"device_id": "device_id",
"tags": [
"tag_name"
]
}],
'time_range': [{'start': start_ts, 'end': end_ts}],
'time_last': {'lastDays': lastDay, 'lastHours': lastHour, 'lastMins': lastMin}
}
"""
DBManager.execute_query(querySql=None)
Return the result in MySQL, PostgreSQL, MongoDB or InfluxDB after executing the querySql in config or querySql parameter.
Download files which are specified in buckets in S3 config or containers in Azure Blob config, and return buckets and containers name of the array.
If only download one csv file, then return dataframe.
Return dataframe of list which of Machine and Parameter in timeRange or timeLast from APM.
Return dataframe of list which of Tag in timeRange or timeLast from DataHub.
df = manager.execute_query()
"""
Age Cabin Embarked Fare ... Sex Survived Ticket_info Title2
0 22.0 7.0 2.0 7.2500 ... 1.0 0.0 2.0 2.0
1 38.0 2.0 0.0 71.2833 ... 0.0 1.0 14.0 3.0
2 26.0 7.0 2.0 7.9250 ... 0.0 1.0 31.0 1.0
3 35.0 2.0 2.0 53.1000 ... 0.0 1.0 36.0 3.0
4 35.0 7.0 2.0 8.0500 ... 1.0 0.0 36.0 2.0
...
"""
container_names = manager.execute_query()
"""
['container1', 'container2']
"""
"""
Age Cabin Embarked Fare ... Sex Survived Ticket_info Title2
0 22.0 7.0 2.0 7.2500 ... 1.0 0.0 2.0 2.0
1 38.0 2.0 0.0 71.2833 ... 0.0 1.0 14.0 3.0
2 26.0 7.0 2.0 7.9250 ... 0.0 1.0 31.0 1.0
3 35.0 2.0 2.0 53.1000 ... 0.0 1.0 36.0 3.0
4 35.0 7.0 2.0 8.0500 ... 1.0 0.0 36.0 2.0
...
"""
bucket_names = manager.execute_query()
"""
['bucket1', 'bucket2']
"""
"""
Age Cabin Embarked Fare ... Sex Survived Ticket_info Title2
0 22.0 7.0 2.0 7.2500 ... 1.0 0.0 2.0 2.0
1 38.0 2.0 0.0 71.2833 ... 0.0 1.0 14.0 3.0
2 26.0 7.0 2.0 7.9250 ... 0.0 1.0 31.0 1.0
3 35.0 2.0 2.0 53.1000 ... 0.0 1.0 36.0 3.0
4 35.0 7.0 2.0 8.0500 ... 1.0 0.0 36.0 2.0
...
"""
DBManager.create_table(table_name, columns=[])
Create table in database for MySQL, Postgres, MongoDB and InfluxDB.
Noted, to create a new measurement in influxdb simply insert data into the measurement.
Create Bucket/Container in S3/Azure Blob.
Note: PostgreSQL table_name format schema.table
table_name = 'titanic'
columns = [
{'name': 'index', 'type': 'INTEGER', 'is_primary': True},
{'name': 'survived', 'type': 'FLOAT', 'is_not_null': True},
{'name': 'age', 'type': 'FLOAT'},
{'name': 'embarked', 'type': 'INTEGER'}
]
manager.create_table(table_name=table_name, columns=columns)
bucket_name = 'bucket'
manager.create_table(table_name=bucket_name)
container_name = 'container'
manager.create_table(table_name=container_name)
DBManager.is_table_exist(table_name)
Return if the table exists in MySQL, Postgres, MongoDB or Influxdb.
Return if the bucket exists in S3.
Return if the container exists in Azure Blob.
table_name = 'titanic'
manager.is_table_exist(table_name=table_name)
bucket_name = 'bucket'
manager.is_table_exist(table_name=bucket_name)
container_name = 'container'
manager.is_table_exist(table_name=container_name)
DBManager.is_file_exist(table_name, file_name)
Return if the file exists in the bucket in S3 & AWS S3.
Note this function only support S3 and AWS S3.
bucket_name = 'bucket'
file_name = 'test.csv
manager.is_file_exist(table_name=bucket_name, file_name=file_name)
# Return: Boolean
DBManager.insert(table_name, columns=[], records=[], source='', destination='')
Insert records into table in MySQL, Postgres, MongoDB or InfluxDB.
Upload file to S3 and Azure Blob.
table_name = 'titanic'
columns = ['index', 'survived', 'age', 'embarked']
records = [
[0, 1, 22.0, 7.0],
[1, 1, 2.0, 0.0],
[2, 0, 26.0, 7.0]
]
manager.insert(table_name=table_name, columns=columns, records=records)
bucket_name = 'bucket'
source='test.csv'
destination='test_s3.csv'
manager.insert(table_name=bucket_name, source=source, destination=destination)
container_name = 'container'
source='test.csv'
destination='test_s3.csv'
manager.insert(table_name=container_name, source=source, destination=destination)
Use APM data source
- Get Hist Raw data from SCADA Mongo data base
- Required
- username: APM SSO username
- password: APM SSO password
- mongouri: mongo data base uri
- apmurl: APM api url
- apm_config: APM config (type:Array)
- name: dataset name
- machines: APM machine list (type:Array)
- parameters: APM parameter name list (type:Array)
- time range: Training date range
[{'start':'2019-05-01', 'end':'2019-05-31'}]
- time last: Training date range
{'lastDays:' 1, 'lastHours': 2, 'lastMins': 3}
DBManager.delete_table(table_name)
Delete table in MySQL, Postgres, MongoDB or InfluxDB, and return if the table is deleted successfully.
Delete the bucket in S3 and return if the table is deleted successfully.
Delete the container in Azure Blob and return if the table is deleted successfully.
table_name = 'titanic'
is_success = manager.delete_table(table_name=table_name)
bucket_name = 'bucket'
is_success = manager.delete_table(table_name=bucket_name)
container_name = 'container'
is_success = manager.delete_table(table_name=container_name)
DBManager.delete_record(table_name, file_name, condition)
Delete record with condition in table_name in MySQL, Postgres and MongoDB, and return if delete successfully.
Delete file in bucket in S3 and in container in Azure Blob, and return if the file is deleted successfully.
Note Influx not support this function.
table_name = 'titanic'
condition = 'passenger_id = 1'
is_success = manager.delete_record(table_name=table_name, condition=condition)
table_name = 'titanic'
condition = {'passanger_id': 1}
is_success = manager.delete_record(table_name=table_name, condition=condition)
bucket_name = 'bucket'
file_name = 'data/titanic.csv'
is_success = manager.delete_record(table_name=bucket_name, file_name=file_name)
container_name = 'container'
file_name = 'data/titanic.csv'
is_success = manager.delete_record(table_name=container_name,file_name=file_name)
Example
MongoDB Example
from afs2datasource import DBManager, constant
manager = DBManager(
db_type=constant.DB_TYPE['MONGODB'],
username={USERNAME},
password={PASSWORD},
host={HOST},
port={PORT},
database={DATABASE},
collection={COLLECTION},
querySql={QUERYSQL}
)
QUERYSQL = "{\"ts\": {\"$lte\": ISODate(\"2020-09-26T02:53:00Z\")}}"
QUERYSQL = {'ts': {'$lte': datetime.datetime(2020,9,26,2,53,0)}}
manager.connect()
is_connected = manager.is_connected()
table_name = 'titanic'
manager.is_table_exist(table_name)
columns = [
{'name': 'index', 'type': 'INTEGER', 'is_not_null': True},
{'name': 'survived', 'type': 'INTEGER'},
{'name': 'age', 'type': 'FLOAT'},
{'name': 'embarked', 'type': 'INTEGER'}
]
manager.create_table(table_name=table_name, columns=columns)
columns = ['index', 'survived', 'age', 'embarked']
records = [
[0, 1, 22.0, 7.0],
[1, 1, 2.0, 0.0],
[2, 0, 26.0, 7.0]
]
manager.insert(table_name=table_name, columns=columns, records=records)
data = manager.execute_query()
"""
index survived age embarked
0 0 1 22.0 7.0
1 1 1 2.0 0.0
2 2 0 26.0 7.0
...
"""
condition = {'survived': 0}
is_success = db.delete_record(table_name=table_name, condition=condition)
is_success = db.delete_table(table_name=table_name)
manager.disconnect()
S3 Example
from afs2datasource import DBManager, constant
manager = DBManager(
db_type = constant.DB_TYPE['S3'],
endpoint={ENDPOINT},
access_key={ACCESSKEY},
secret_key={SECRETKEY},
buckets=[{
'bucket': {BUCKET_NAME},
'blobs': {
'files': ['titanic.csv'],
'folders': ['models/']
}
}]
)
manager.connect()
bucket_name = 'titanic'
manager.is_table_exist(table_name=bucket_name)
manager.create_table(table_name=bucket_name)
local_file = '../titanic.csv'
s3_file = 'titanic.csv'
manager.insert(table_name=bucket_name, source=local_file, destination=s3_file)
bucket_names = manager.execute_query()
is_exist = manager.is_file_exist(table_name=bucket_name, file_name=s3_file)
is_success = manager.delete_record(table_name=bucket_name, file_name=s3_file)
is_success = manager.delete_table(table_name=bucket_name)
APM Data source example
APMDSHelper(
username,
password,
apmurl,
machineIdList,
parameterList,
mongouri,
timeRange)
APMDSHelper.execute()
Azure Blob Example
from afs2datasource import DBManager, constant
manager = DBManager(
db_type=constant.DB_TYPE['AZUREBLOB'],
account_key={ACCESS_KEY},
account_name={ACCESS_NAME}
containers=[{
'container': {CONTAINER_NAME},
'blobs': {
'files': ['titanic.csv'],
'folders': ['test/']
}
}]
)
manager.connect()
container_name = 'container'
manager.is_table_exist(table_name=container_name)
manager.create_table(table_name=container_name)
local_file = '../titanic.csv'
azure_file = 'titanic.csv'
manager.insert(table_name=container_name, source=local_file, destination=azure_file)
container_names = manager.execute_query()
is_exist = manager.is_file_exist(table_name=container_name, file_name=azure_file)
is_success = manager.delete_record(table_name=container_name,
file_file=azure_file)
is_success = manager.delete_table(table_name=container_name)
Oracle Example
Notice
- Install OracleDB client Documents
from afs2datasource import DBManager, constant
manager = DBManager(
db_type=constant.DB_TYPE['ORACLEDB'],
username=username,
password=password,
host=host,
port=port,
dsn=dsb,
querySql="select {field_key} from {measurement_name}"
)
manager.connect()
table_name = 'table'
manager.is_table_exist(table_name=table_name)
data = manager.execute_query()
"""
index survived age embarked
0 0 1 22.0 7.0
1 1 1 2.0 0.0
2 2 0 26.0 7.0
...
"""



