Qwen Tokenizer
Introduction
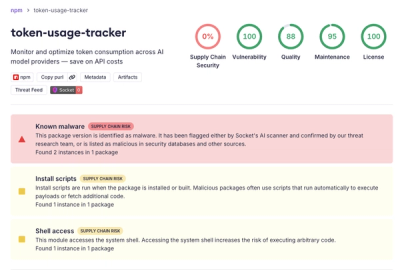
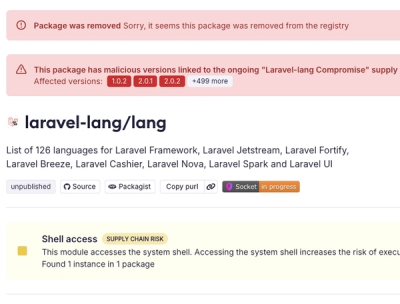
Qwen Tokenizer is an efficient and lightweight tokenization libraries which doesn't require heavy dependencies like the transformers library, Qwen Tokenizer solely relies on the tokenizers and regex library, making it a more streamlined and efficient choice for tokenization tasks.
Installation
To install Qwen Tokenizer, use the following command:
pip install qwen_tokenizer
Basic Usage
Below is a simple example demonstrating how to use Qwen Tokenizer to encode text:
from qwen_tokenizer import qwen_tokenizer
text = "Hello! 毕老师!1 + 1 = 2 ĠÑĤвÑĬÑĢ"
result = qwen_tokenizer.encode(text)
print(result)
Output
[9707, 0, 6567, 107, 243, 101049, 6313, 16, 488, 220, 16, 284, 220, 17, 9843, 254, 71354, 147667, 95199, 29456, 71354, 149472, 71354, 144806]
License
This project is licensed under the MIT License.