aws-lambda-multipart-parser
Introduction
Support of multipart/form-data requests is a relatively new feature for AWS Lambdas.
Although, there is such feature, majority of libraries for parsing multipart/form-data requests is based on server technology, which can't be used in case of AWS Lambdas. That's why, AWS Lambda specific multipart/form-data parser was created.
Steps for integrating multipart/form-data to your lambda
1.Create project with serverless framework.
You can find all necessary information there:
2. Add configuration for your AWS Lambda.
Go to serverless.yml file and add configurations for your AWS Lambda:
method: POST
integration: LAMBDA
method: POST - because of we are receiving multipart/form-data request.
integration: LAMBDA - without that I constanly got 502 Error: Bad Gateway, but I don't know why.
3. Deploy a draft of your function
Execute command sls deploy in AWS Lambda folder. (for more information look for sources at step 1)
4. Configure API Gateway at AWS Console.
- Go to API Gateway.
- Select your API in API Gateway interface
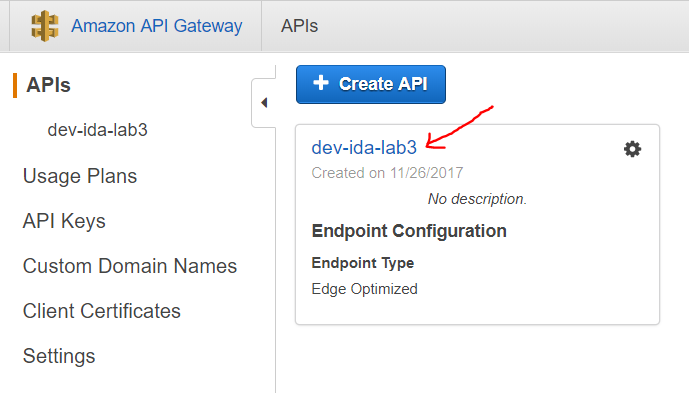
- Go to Settings
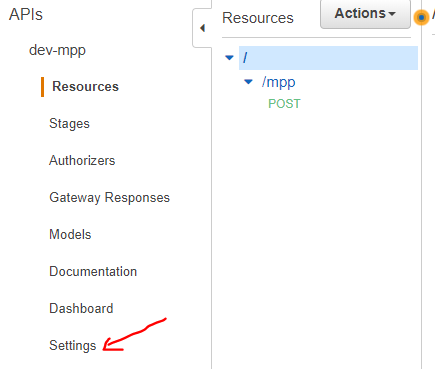
- Add multipart/form-data binary media type

- Go to Resources -> POST method of your API -> Integration Request
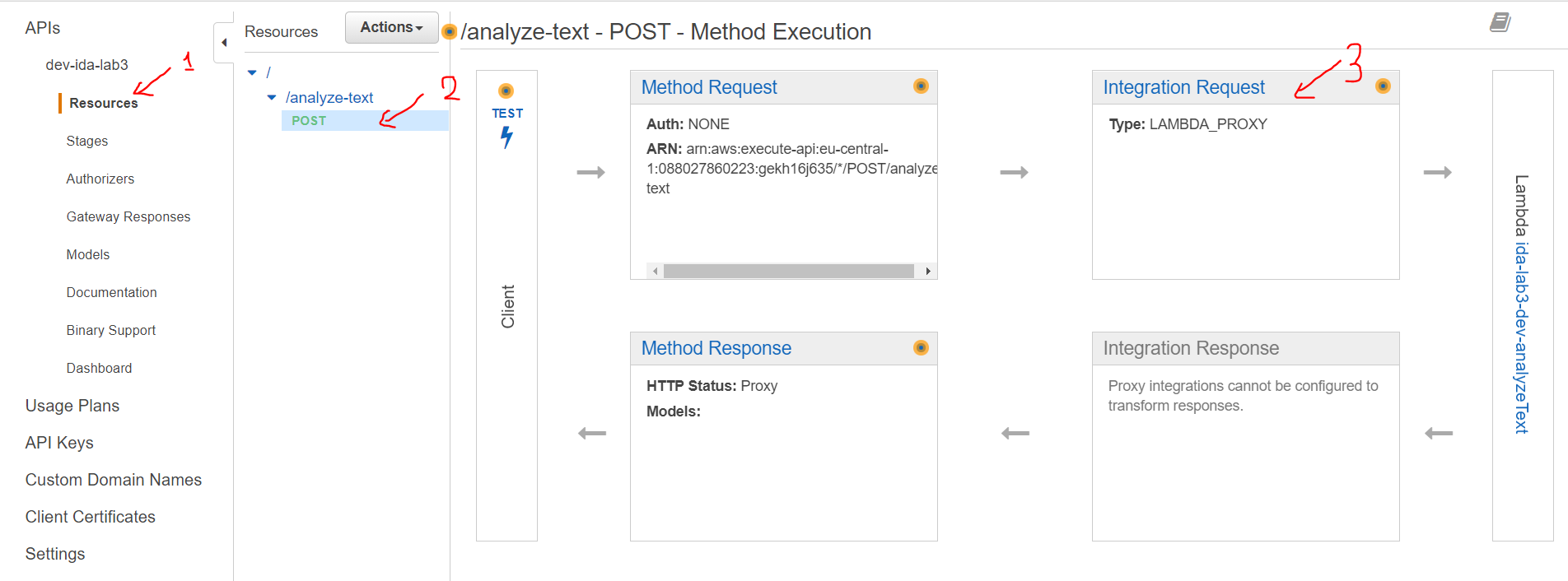
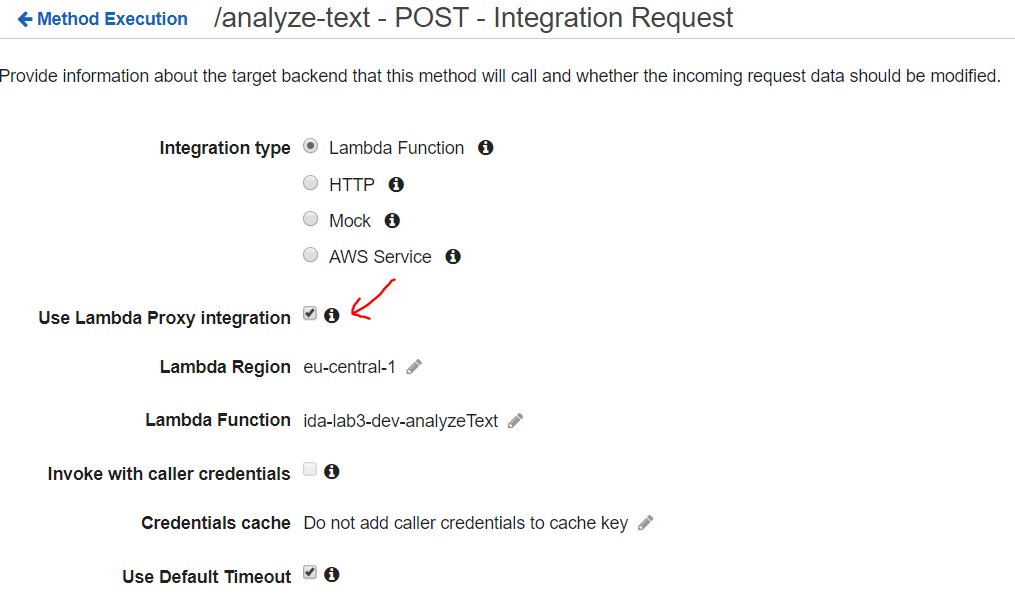
- Check Use Lambda Proxy Integration
- Deploy your API changes
5. Enabling CORS
In majority of cases, while working with AWS Lambda, you will need to enable CORS. Unfortunately, standard way of doing it with AWS UI in API Gateway doesn't work in our case. To solve the problem, you need to send Access-Control-Allow-Origin header as a part of response from your lambda. For example:
const response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*"
},
body: JSON.stringify(parse(event, true)),
};
callback(null, response);
6. You're ready to use the library.
- Import aws-lambda-multipart-parser with
npm install --save aws-lambda-multipart-parser command.
- Require it in file
const multipart = require('aws-lambda-multipart-parser');.
- Pass your event object to parse function like that
multipart.parse(event, spotText), where event is a event object you get from lambda invocation, spotText - if it's true all text files are present in text for after parsing, if it's false all text files are represented as regular files with Buffer. Parse function will return object representing the request body.
7. Response body object
{
"file": {
"type": "file",
"filename": "lorem.txt",
"contentType": "text/plain",
"content": {
"type": "Buffer",
"data": [ ... byte array ... ]
} or String
},
"field": "value"
}
All fields are represented in request body object as a key-value pair.
All files are represented as an object with these fields:
- type - indicates that it's a file
- filename - name of uploaded file (the first one)
- contentType - mime-type of file
- content - content of file in form of Buffer (it's planned in future to give a choise between Buffer and text)
8. Issue with malformed media files uploaded to S3.
Unfortunately, there is an issue with malformed media files uploaded to S3. Let me explain on example,
I send an image, which is 50Kb. I get a buffer, which is 50Kb. That fact indicates buffer is formed well,
but some encoding issue happens with s3.upload and s3.putObject functions. If you have a solution or a hint, contact me
myshenin.contact@gmail.com.



