
Product
Introducing Data Exports
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
By Ola Adekola - Apr 23, 2026
detect-file-type
Advanced tools

Detect file type by signatures. file-type inspired
jpg, png, gif, webp, flif, cr2, tif, bmp, jxr, psd, zip, epub, xpi, tar, rar, gz, bz2, 7z, dmg, mov, mp4, m4v, m4a, 3g2, 3gp, avi, wav, qcp, mid, mkv, webm, wasm, asf, wmv, wma, mpg, mp3, opus, ogg, ogv, oga, ogm, ogx, spx, flac, ape, wv, amr, pdf, exe, swf, rtf, woff, woff2, eot, ttf, otf, ico, cur, flv, ps, xz, sqlite, nes, dex, crx, elf, cab, deb, ar, rpm, Z, lz, msi, mxf, mts, blend, bpg, jp2, jpx, jpm, mj2, aif, xml, svg, mobi, heic, ktx, dcm, mpc, ics, glb, pcap, html
npm i --save detect-file-type
var detect = require('detect-file-type');
detect.fromFile('./image.jpg', function(err, result) {
if (err) {
return console.log(err);
}
console.log(result); // { ext: 'jpg', mime: 'image/jpeg' }
});
Detect file type from hard disk
filePath - path to filebufferLength - (optional) Buffer size (in bytes) starting from the start of file. By default 500. If size of file less than 500 bytes then param the same as size of the filecallbackDetect file type from buffer
buffer - uint8array/BuffercallbackDetect file type from buffer
fd - file descriptorbufferLength - (optional) Buffer size (in bytes) starting from the start of fd. By default 500. If size of file less than 500 bytes then param the same as size of the filecallbackAdd new signature for file type detecting
signature - a signature. See section about it belowAdd custom function which receive buffer and trying to detect file type.
fn - function which receive bufferThis method needed for more complicated cases like html or xml for example. Truly uncomfortable to detect html via signatures because html format has a lot of "magic numbers" in the different places. So you can install is-html package for example and use its functionality.
const detect = require('detect-file-type');
const isHtml = require('is-html');
detect.addCustomFunction((buffer) => {
const str = buffer.toString();
if (isHtml(str)) {
return {
ext: 'html',
mime: 'text/html'
}
}
return false;
});
detect.fromFile('./some.html', (err, result) => {
if (err) {
return console.log(err);
}
console.log(result); // { ext: 'html', mime: 'text/html' }
});
Note: custom function should be pure (without any async operations)
Detecting of file type work via signatures. The simplest signature in JSON format looks like:
{
"type": "jpg",
"ext": "jpg",
"mime": "image/jpeg",
"rules": [
{ "type": "equal", "start": 0, "end": 2, "bytes": "ffd8" }
]
}
params:
type - signature type, mostly it's the same as param 'ext'ext - file extensioniana - optional iana registered mime type - will be added when actual used mime differs from iana, or when the old mime type we used was wrongmime - mime type of filerules - list of rules for detectingMore details about param rules:
This param have to be array of objects
type - a rule type. There are available a few types: equal, notEqual, contains, notContains, or, and, defaultsearch - a searching rule, that keeps the offset of the searched bytes in a special id.search_ref - a reference to a previously performed search, start and end will be offset by it.equal - here is required field bytes. We get a dump of buffer from start (equals 0 by default) to end (equals buffer.length by default). After that we compare the dump with value in param bytes. If values are equal then this rule is correct.notEqual - here is required field bytes. We get a dump of buffer from start (equals 0 by default) to end (equals buffer.length by default). After that we compare the dump with value in param bytes. If values aren't equal then this rule is correct.contains - here is required field bytes. We get a dump of buffer from start (equals 0 by default) to end (equals buffer.length by default). After that we try to find the sequence from bytes in this dump. If the dump contains bytes then rules is correct.notContains - here is required field bytes. We get a dump of buffer from start (equals 0 by default) to end (equals buffer.length by default). After that we try to find the sequence from bytes in this dump. If the dump contains bytes then rules is incorrect.or and andActually, these types are necessary when you work with complicated signatures. For example, when file contains few sequences of bytes in different parts of file. Here is required field 'rules', where you should define set of another rules. See example:
{
"type": "tif",
"ext": "tif",
"mime": "image/tiff",
"rules": [
{ "type": "and", "rules":
[
{ "type": "notEqual", "start": 8, "end": 10, "bytes": "4352" },
{ "type": "or", "rules":
[
{ "type": "equal", "start": 0, "end": 4, "bytes": "49492a00" },
{ "type": "equal", "start": 0, "end": 4, "bytes": "4d4d002a" }
]
}
]
}
]
}
Explanation: If dump starts from 8th byte and ends to 10th byte isn't equal "4352", and dump starts from 0 and ends to 4th byte is equal "49492a00" or is equal "4d4d002a" then data looks like file with 'tif' format.
or - means that any rules from rules should be correct. If at least 1 rule is correct then list are correct too.and - means that each rule from rules should be correct. If all rules are correct then list is correct. When at least 1 rule fail then all list is incorrect.The rules or and and can be nested without restrictions.
The default type is special and is used as a fallback when a set of or rules did not match, inside a larger tree with multiple mime detections.
search objectid - id to assign to the result (reference later with search_ref)start/end - range to search inbytes - bytes to search forWTFPL © Dmitry Pavlovsky
FAQs
Detect file type by signature
The npm package detect-file-type receives a total of 3,802 weekly downloads. As such, detect-file-type popularity was classified as popular.
We found that detect-file-type demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
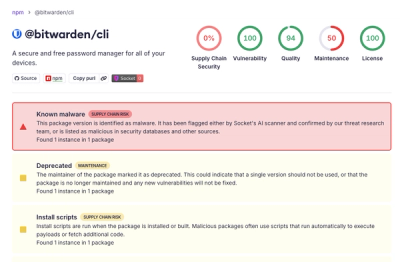
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.

Research
/Security News
Docker and Socket have uncovered malicious Checkmarx KICS images and suspicious code extension releases in a broader supply chain compromise.