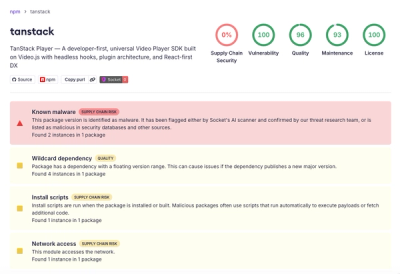
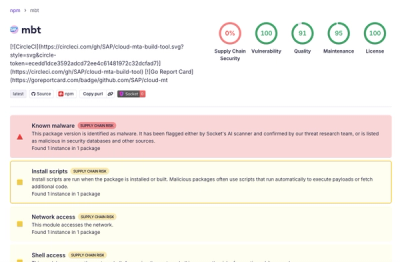
node-sitemap-stream-parser
A streaming parser for sitemap files. It is able to deal with GBs of deeply nested sitemaps with hundreds of URLs in them. Maximum memory usage is just over 100Mb at any time.
Usage
The main method to extract URLs for a site is with the parseSitemaps(urls, url_cb, done) method. You can call it with both a single URL or an Array of URLs. The url_cb is called for every URL that is found. The done callback is passed an error and/or a list of all the sitemaps that were checked.
Examples:
var sitemaps = require('sitemap-stream-parser');
sitemaps.parseSitemaps('http://example.com/sitemap.xml', console.log, function(err, sitemaps) {
console.log('All done!');
});
or
var sitemaps = require('sitemap-stream-parser');
var urls = ['http://example.com/sitemap-posts.xml', 'http://example.com/sitemap-pages.xml'];
all_urls = [];
sitemaps.parseSitemaps(urls, function(url) { all_urls.push(url); }, function(err, sitemaps) {
console.log(all_urls);
console.log('All done!');
});
Sometimes sites advertise their sitemaps in their robots.txt file. To parse this file to see if that is the case use the method sitemapsInRobots(url, cb). You can easily combine those 2 methods.
var sitemaps = require('sitemap-stream-parser');
sitemaps.sitemapsInRobots('http://example.com/robots.txt', function(err, urls) {
if(err || !urls || urls.length == 0)
return;
sitemaps.parseSitemaps(urls, console.log, function(err, sitemaps) {
console.log(sitemaps);
});
});