TokenLens




Typed model metadata and context/cost utilities that help AI apps answer: Does this fit? What will it cost? Should we compact now? How much budget is left for the next turn?
Works great with the Vercel AI SDK out of the box, and remains SDK‑agnostic.
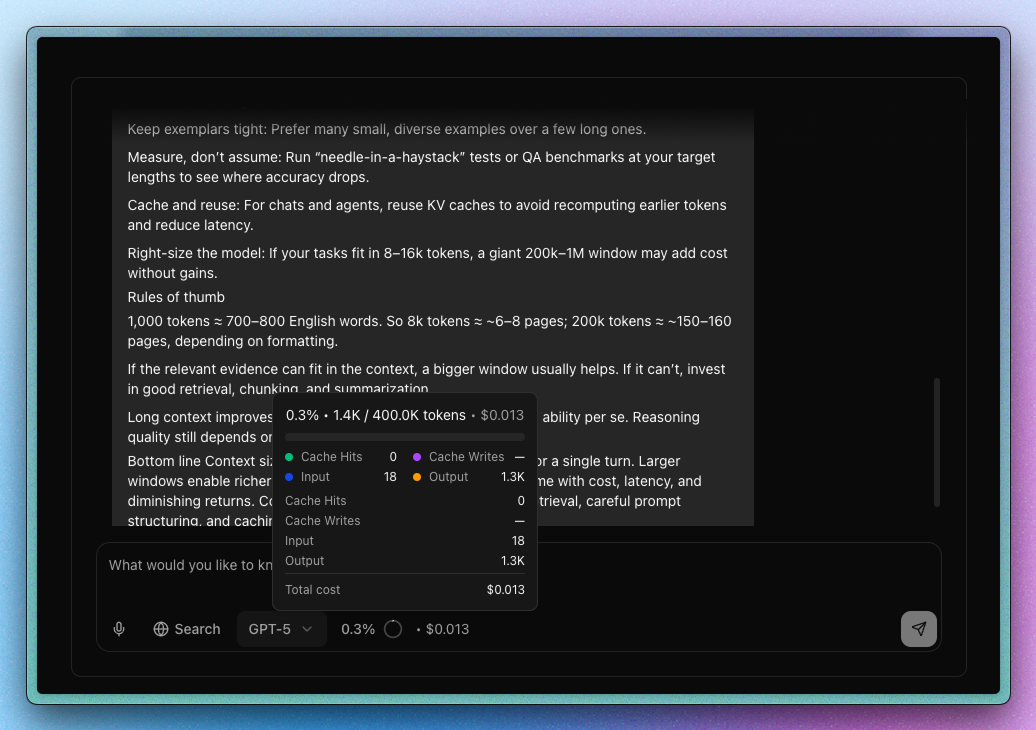
Highlights
- Canonical model registry with alias resolution and minimal metadata you can trust.
- Strong TypeScript surface:
ModelId autocomplete and safe helpers.
- Usage normalization across providers and SDKs (incl. Vercel AI SDK fields).
- Context budgeting: remaining tokens, percent used, and next-turn budget.
- Compaction helpers: when to compact and how many tokens to remove.
- Cost estimation: fast, rough USD costs using source‑linked pricing when available.
- Conversation utilities: sum usage, estimate conversation cost, measure context rot.
Install
- npm:
npm i tokenlens
- pnpm:
pnpm add tokenlens
- yarn:
yarn add tokenlens
Quick Start
import {
type ModelId,
modelMeta,
percentOfContextUsed,
tokensRemaining,
costFromUsage,
} from 'tokenlens';
const id: ModelId = 'openai:gpt-4.1';
const usage = { prompt_tokens: 3200, completion_tokens: 400 };
const meta = modelMeta(id);
const used = percentOfContextUsed({ id, usage, reserveOutput: 256 });
const remaining = tokensRemaining({ id, usage, reserveOutput: 256 });
const costUSD = costFromUsage({ id, usage });
console.log({ meta, used, remaining, costUSD });
Core Helpers
- Registry:
resolveModel, listModels, MODEL_IDS, isModelId, assertModelId
- Usage:
normalizeUsage, breakdownTokens, consumedTokens
- Context:
getContextWindow, remainingContext, percentRemaining, fitsContext, pickModelFor
- Cost:
estimateCost
- Compaction:
shouldCompact, contextHealth, tokensToCompact
- Conversation:
sumUsage, estimateConversationCost, computeContextRot, nextTurnBudget
- Sugar:
modelMeta, percentOfContextUsed, tokensRemaining, costFromUsage
Provider‑Agnostic Usage
import { normalizeUsage, breakdownTokens } from 'tokenlens';
const u1 = normalizeUsage({ prompt_tokens: 1000, completion_tokens: 150 });
const u2 = normalizeUsage({ inputTokens: 900, outputTokens: 200, totalTokens: 1100 });
const b = breakdownTokens({ inputTokens: 900, cachedInputTokens: 300, reasoningTokens: 120 });
Async Fetch (models.dev)
import {
fetchModels,
FetchModelsError,
type ModelCatalog,
type ProviderInfo,
type ProviderModel,
} from 'tokenlens';
const catalog: ModelCatalog = await fetchModels();
const openai: ProviderInfo | undefined = await fetchModels({ provider: 'openai' });
const gpto: ProviderModel | undefined = await fetchModels({ provider: 'openai', model: 'gpt-4o' });
const matches: Array<{ provider: string; model: ProviderModel }> = await fetchModels({ model: 'gpt-4.1' });
try {
await fetchModels();
} catch (err) {
if (err instanceof FetchModelsError) {
console.error('Fetch failed:', err.code, err.status, err.message);
} else {
throw err;
}
}
Picking Model Metadata
import { getModels, getModelMeta } from 'tokenlens';
const providers = getModels();
const openai = getModelMeta({ providers, provider: 'openai' });
const gpto = getModelMeta({ providers, provider: 'openai', model: 'gpt-4o' });
const picks = getModelMeta({ providers, provider: 'openai', models: ['gpt-4o', 'o3-mini'] });
const viaId = getModelMeta({ providers, id: 'openai:gpt-4o' });
Context Budgeting & Compaction
import { remainingContext, shouldCompact, tokensToCompact, contextHealth } from 'tokenlens';
const rc = remainingContext({ modelId: 'anthropic:claude-3-5-sonnet-20240620', usage: u1, reserveOutput: 256 });
if (shouldCompact({ modelId: 'anthropic:claude-3-5-sonnet-20240620', usage: u1 })) {
const n = tokensToCompact({ modelId: 'anthropic:claude-3-5-sonnet-20240620', usage: u1 });
}
const badge = contextHealth({ modelId: 'openai:gpt-4.1', usage: u2 });
Advanced
- Caps strategy:
remainingContext supports strategy: 'provider-default' | 'combined' | 'input-only'.
provider-default (default): prefers combinedMax when available; otherwise uses inputMax.combined: always uses combinedMax (falls back to inputMax if missing).input-only: uses only inputMax for remaining/percent calculations.
- Defaults:
shouldCompact defaults to threshold: 0.85; contextHealth defaults to warnAt: 0.75, compactAt: 0.85.
Conversation Utilities
import { sumUsage, estimateConversationCost, computeContextRot, nextTurnBudget } from 'tokenlens';
const totals = sumUsage([turn1.usage, turn2.usage, turn3.usage]);
const cost = estimateConversationCost({ modelId: 'openai:gpt-4.1', usages: [turn1.usage, turn2.usage] });
const rot = computeContextRot({ messageTokens: [800, 600, 400, 300, 200], keepRecentTurns: 2, modelId: 'openai:gpt-4.1' });
const nextBudget = nextTurnBudget({ modelId: 'openai:gpt-4.1', usage: totals, reserveOutput: 256 });
Listing Models
import { listModels } from 'tokenlens';
const stableOpenAI = listModels({ provider: 'openai', status: 'stable' });
Data Source & Sync
- Primary source: models.dev (https://github.com/sst/models.dev). We periodically sync our registry from their dataset.
- Official provider pages are used where applicable; if numbers aren’t explicit, fields remain undefined.
- Sync locally:
pnpm -C packages/tokenlens sync:models
Acknowlegements
License
MIT



