
Product
Introducing Reachability for PHP
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.
By Benjamin Barslev - Apr 24, 2026
SQLDataModel
Advanced tools
SQLDataModel is a lightweight dataframe library designed for efficient data extraction, transformation, and loading (ETL) across various sources and destinations, providing an efficient alternative to common setups like pandas, numpy, and sqlalchemy while also providing additional features without the overhead of external dependencies.



SQLDataModel is a fast & lightweight data model with no additional dependencies for quickly fetching and storing your tabular data to and from the most commonly used databases & data sources in a couple lines of code. It's as easy as ETL:
import sqldatamodel as sdm
# Extract your data:
df = sdm.from_html('https://antet.github.io/planets')
# Transform it:
df['Flyable?'] = df['Gravity'].apply(lambda x: str(x < 1.0))
# Filter it
df = df[df['Flyable?']=='True']
# Load it wherever you need! Let's make a Markdown file
df.to_markdown('Planets.MD')
Now we have a planetary bucket list in Planets.MD:
| Planet | Gravity | Moons | Flyable? |
|:--------|--------:|------:|:---------|
| Mercury | 0.38 | 0 | True |
| Venus | 0.91 | 0 | True |
| Mars | 0.38 | 2 | True |
| Saturn | 0.92 | 146 | True |
| Uranus | 0.89 | 27 | True |
Made for those times when you just want to use raw SQL on your dataframe, or need to move data around but the full Pandas, Numpy, SQLAlchemy installation is just overkill. SQLDataModel includes all the most commonly used features, including additional ones like using plain SQL on your DataFrame and pretty printing your table, at 1/1000 the size, 0.03MB vs 30MB
Use the package manager pip to install SQLDataModel.
$ pip install SQLDataModel
Then import the main class SQLDataModel into your local project, see usage below or go straight to the project docs.
A SQLDataModel can be created from any number of sources, as a quick demo lets create one using a Wikipedia page:
>>> import sqldatamodel as sdm
>>>
>>> url = 'https://en.wikipedia.org/wiki/1998_FIFA_World_Cup'
>>>
>>> df = sdm.from_html(url, table_identifier=95)
>>>
>>> df[:4, ['R', 'Team', 'W', 'Pts.']]
┌──────┬─────────────┬──────┬──────┐
│ R │ Team │ W │ Pts. │
├──────┼─────────────┼──────┼──────┤
│ 1 │ France │ 6 │ 19 │
│ 2 │ Brazil │ 4 │ 13 │
│ 3 │ Croatia │ 5 │ 15 │
│ 4 │ Netherlands │ 3 │ 12 │
└──────┴─────────────┴──────┴──────┘
[4 rows x 4 columns]
SQLDataModel provides a quick and easy way to import, view, transform and export your data in multiple formats and sources, providing the full power of executing raw SQL against your model in the process.
SQLDataModel is a versatile data model leveraging the mighty power of in-memory sqlite3 to perform fast and light-weight transformations allowing you to easily move and manipulate data from source to destination regardless of where, or in what format, the data is. If you need to extract, transform, or simply transfer data across various formats, SQLDataModel can make your life easier. Here's a few examples how:
Say we find some cool data online, perhaps some planetary data, and we want to go and get it for our own purposes:
import sqldatamodel as sdm
# Target url with some planetary data we can extract
url = 'https://antet.github.io/sdm-planets'
# Create a model from the first table element found on the web page
df = sdm.from_html(url, table_identifier=1)
# Add some color to it
df.set_display_color('#A6D7E8')
# Lets see!
print(df)
SQLDataModel's default output is pretty printed and formatted to fit within the current terminal's width and height, since we added some color here's the result:

Now that we have our data as a SQLDataModel, we can do any number of things with it using the provided methods or using your own SQL and returning the query results as a new model! Lets find out, all extreme temperatures and pressure aside, if it would be easier to fly given the planet's gravity relative to Earth:
# Extract: Slice by rows and columns
df = df[:,['Planet','Gravity']] # or df[:,:2]
# Transform: Create a new column based on existing values
df['Flyable?'] = df['Gravity'].apply(lambda x: str(x < 1.0))
# Filter: Keep only the 'Flyable' planets
df = df[df['Flyable?'] == 'True']
# Load: Let's turn our data into markdown!
df.to_markdown('Planet-Flying.MD')
Here's the raw markdown of the new file we created Planet-Flying.MD:
| Planet | Gravity | Flyable? |
|:--------|--------:|:---------|
| Mercury | 0.38 | True |
| Venus | 0.91 | True |
| Mars | 0.38 | True |
| Saturn | 0.92 | True |
| Uranus | 0.89 | True |
Notice that the output from the to_markdown() method also aligned our columns based on the data type, and padded the values so that even the raw markdown is pretty printed! While we used the from_html() and to_markdown() methods for this demo, we could just as easily have created the same table in any number of formats. Once we have our data as a SQLDataModel, it would've been just as easy to have the data in LaTeX:
# Let's convert it to a LaTeX table instead
df_latex = df.to_latex()
# Here's the output
print(df_latex)
As with our markdown output, the columns are correctly aligned and pretty printed:
\begin{tabular}{|l|r|l|}
\hline
Planet & Gravity & Flyable? \\
\hline
Mercury & 0.38 & True \\
Venus & 0.91 & True \\
Mars & 0.38 & True \\
Saturn & 0.92 & True \\
Uranus & 0.89 & True \\
\hline
\end{tabular}
In fact, using the to_html() method is how the table from the beginning of this demo was created! Click here for an example of how the styling and formatting applied to SQLDataModel gets exported along with it when using to_html().
I can't tell you how many times I've found myself searching for information on how to do this or that operation in pandas and wished I could just quickly do it in SQL instead. Enter SQLDataModel:
import pandas as pd
import sqldatamodel as sdm
# Titanic dataset
df = pd.read_csv('titanic.csv')
# Transformations you don't want to do in pandas if you already know SQL
sql_query = """
select
Pclass, Sex, count(*) as 'Survived'
from sdm where
Survived = 1
group by
Pclass, Sex
order by
count(*) desc
"""
# Extract: Create SQLDataModel from the df
df_sdm = sdm.from_pandas(df_pd)
# Transform: Do them in SQLDataModel
df_sdm = df_sdm.execute_fetch(sql_query)
# Load: Then hand it back to pandas!
df_pd = df_sdm.to_pandas()
Here we're using SQLDataModel to avoid performing the complex pandas operations required for aggregation if we already know SQL. Here's the output of the df_sdm we used to do the operations in and the df_pd:
SQLDataModel: pandas:
┌───┬────────┬────────┬──────────┐
│ │ Pclass │ Sex │ Survived │ Pclass Sex Survived
├───┼────────┼────────┼──────────┤ 0 1 female 91
│ 0 │ 1 │ female │ 91 │ 1 3 female 72
│ 1 │ 3 │ female │ 72 │ 2 2 female 70
│ 2 │ 2 │ female │ 70 │ 3 3 male 47
│ 3 │ 3 │ male │ 47 │ 4 1 male 45
│ 4 │ 1 │ male │ 45 │ 5 2 male 17
│ 5 │ 2 │ male │ 17 │
└───┴────────┴────────┴──────────┘
[6 rows x 3 columns]
In this example our source and destination formats were both pd.DataFrame objects, however pandas is not required to use, nor is it a dependency of, SQLDataModel. It is only required if you're using the from_pandas() or to_pandas() methods.
Say we have a table located on a remote PostgreSQL server that we want to put on our website, normally we could pip install SQLAlchemy, psycopg2, pandas including whatever dependencies they come with, like numpy. This time all we need is psycopg2 for the PostgreSQL driver:
import psycopg2
import datetime
import sqldatamodel as sdm
# Setup the connection
psql_conn = psycopg2.connect(...)
# Grab a table with missions to Saturn
df = sdm.from_sql('saturn_missions', psql_conn) # or SQL statement
# Filter to only 'Future' missions
df = df[df['Status'] == 'Future']
# Create new column with today's date so it ages better!
df['Updated'] = datetime.date.today()
# Create a new html file with our table
df.to_html('Future-Saturn.html', index=False)
Here's a snippet from the Future-Saturn.html file generated by the to_html() method:
<!-- Metadata Removed -->
<table>
<tr>
<th>Mission</th>
<th>Status</th>
<th>Launch</th>
<th>Destination</th>
<th>Updated</th>
</tr>
<tr>
<td>New Frontiers 4</td>
<td>Future</td>
<td>2028</td>
<td>Surface of Titan</td>
<td>2024-03-21</td>
</tr>
<tr>
<td>Enceladus Orbilander</td>
<td>Future</td>
<td>2038</td>
<td>Surface of Enceladus</td>
<td>2024-03-21</td>
</tr>
</table>
<!-- SQLDataModel css styles removed -->
The Surface of Titan in 2028, how cool is that!
Let's say we're training a pytorch model and we want to keep the results from training. If you've ever trained one or followed a tutorial, I'm sure you'll be familiar with this pattern:
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
# Train the model and get the metrics
train_loss, train_acc = train(model, criterion, optimizer, train_loader, device)
val_loss, val_acc = validate(model, criterion, val_loader, device)
# Print training results to terminal
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
This ubiquitous setup, where results from each epoch are output to the terminal, has become the Hello, World! of ML training loops. While this is great for monitoring the progress of training, it's miserable for actually keeping and analyzing the data afterwards. Here's how we can use SQLDataModel to help:
import sqldatamodel as sdm
# Initialize an empty model with headers for the data we want to store
df = sdm.SQLDataModel(headers=['Epoch', 'Train Loss', 'Train Acc', 'Val Loss', 'Val Acc'])
# ... Training code ...
We create an empty SQLDataModel that we can use with headers corresponding to the metrics we want to store. Now in our training loop we can fill it with our results:
# Initialize an empty model for training
df = sdm.SQLDataModel(headers=['Epoch', 'Train Loss', 'Train Acc', 'Val Loss', 'Val Acc'])
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
# Train the model and get the metrics
train_loss, train_acc = train(model, criterion, optimizer, train_loader, device)
val_loss, val_acc = validate(model, criterion, val_loader, device)
# Let's store the results first
df.append_row([epoch+1, train_loss, train_acc, val_loss, val_acc])
# Print training results to terminal
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
We use the append_row() method to store the results from training, inserting a new row for each epoch. Now that we're storing the data instead of just printing it to the terminal, we can track our results and easily export them into whichever format we need. For this example, let's store them as a .json file. All we need is to add one more line at the end of our training loop:
# ... Training loop ...
df.to_json('Training-Metrics.json')
This will export all the training data stored in our model to a new JSON file Training-Metrics.json, trimmed for brevity:
[
{
"Epoch": 1,
"Train Loss": 0.6504,
"Train Acc": 0.6576,
"Val Loss": 0.6126,
"Val Acc": 0.6608
},
{
"Epoch": 2,
"Train Loss": 0.5733,
"Train Acc": 0.6989,
"Val Loss": 0.5484,
"Val Acc": 0.7268
},
{
"Epoch": 3,
"Train Loss": 0.5222,
"Train Acc": 0.7239,
"Val Loss": 0.5294,
"Val Acc": 0.7332
}
]
In this example we kept the original print statements intact during training, but we could've removed them altogether and done something like this instead:
# Initialize an empty model for training
df = sdm.SQLDataModel(headers=['Epoch', 'Train Loss', 'Train Acc', 'Val Loss', 'Val Acc'])
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
# Train the model and get the metrics
train_loss, train_acc = train(model, criterion, optimizer, train_loader, device)
val_loss, val_acc = validate(model, criterion, val_loader, device)
# Let's store the results first
df.append_row([epoch+1, train_loss, train_acc, val_loss, val_acc])
# Pretty print last row of training results to terminal
print(df[-1])
# Print all results when training finishes
print(df)
# Export them as a json file
df.to_json('Training-Metrics.json')
Here we've removed the previous and rather verbose print statement and replaced it with a simple print(df[-1]), this will print the last row of data in the model. This results in the following terminal output for each epoch during training:
┌───────┬────────────┬───────────┬──────────┬─────────┐
│ Epoch │ Train Loss │ Train Acc │ Val Loss │ Val Acc │
├───────┼────────────┼───────────┼──────────┼─────────┤
│ 10 │ 0.2586 │ 0.8063 │ 0.5391 │ 0.7728 │
└───────┴────────────┴───────────┴──────────┴─────────┘
Which, besides having the added benefit of storing our data, is far less code than the prior print statement, and is in my humble opinion much nicer to look at while we wait for training to complete. We've also added one more line, a final print(df) to output all the training results before saving them to Training-Metrics.json. That way, for those of us who still like to see them all in one place, we can have our saved json cake and pretty print it too:
┌───────┬────────────┬───────────┬──────────┬─────────┐
│ Epoch │ Train Loss │ Train Acc │ Val Loss │ Val Acc │
├───────┼────────────┼───────────┼──────────┼─────────┤
│ 1 │ 0.6504 │ 0.6576 │ 0.6126 │ 0.6608 │
│ 2 │ 0.5733 │ 0.6989 │ 0.5484 │ 0.7268 │
│ 3 │ 0.5222 │ 0.7239 │ 0.5294 │ 0.7332 │
│ 4 │ 0.4749 │ 0.7288 │ 0.5461 │ 0.7238 │
│ 5 │ 0.4417 │ 0.7301 │ 0.5862 │ 0.7148 │
│ 6 │ 0.4065 │ 0.7544 │ 0.4882 │ 0.7674 │
│ 7 │ 0.3635 │ 0.7679 │ 0.4793 │ 0.7690 │
│ 8 │ 0.3229 │ 0.7884 │ 0.4833 │ 0.7732 │
│ 9 │ 0.2860 │ 0.7921 │ 0.5041 │ 0.7746 │
│ 10 │ 0.2586 │ 0.8063 │ 0.5391 │ 0.7728 │
└───────┴────────────┴───────────┴──────────┴─────────┘
[10 rows x 5 columns]
Whelp, clearly it's overfitting...
This example will showcase one of the original motivations of this package, moving data from one SQL database to another. It'll be a short one, just as SQLDataModel was designed to be! Let's say we need to move data from a PostgreSQL server into a local SQLite connection:
import sqlite3
import psycopg2
import sqldatamodel as sdm
# Setup our postgresql connection
pg_conn = psycopg2.connect(...)
# Setup our local sqlite3 connection
sqlite_conn = sqlite3.connect(...)
# Create our model from a query on our postgresql connection
df = sdm.from_sql("SELECT * FROM pg_table", pg_conn)
# Import it into our sqlite3 connection, appending to existing data
df.to_sql("local_table", sqlite_conn, if_exists='append')
Thats it! What once required installing packages like pandas, numpy, and SQLAlchemy, plus all of their dependencies, just to able to use a nice DataFrame API when interacting with SQL data, is now just a single package, SQLDataModel. While I love all three of those packages, 99% of what I consistently use them for can be done with far less "package baggage".
Perhaps one of the most novel use-cases I've come across for SQLDataModel is the ability to embed a table just about anywhere you can type. For example, let's say you want to include a table in a slide show but are struggling with the disparate and confusing application specific rules and constraints, which has been my personal experience for every table formatting interface put out by Microsoft, especially Outlook and PowerPoint. Instead of settling for the application specific sandbox you've been forced into, try SQLDataModel instead!
import sqldatamodel as sdm
# Using the Markdown file created in the very first example
df = sdm.from_markdown('Planets.MD')
# Mercury and Venus are too hot, let's change their 'Flyable?' status
df[:2, 'Flyable?'] = 'False'
# Lets use a different table styling, like the one used by polars
df.set_table_style('polars')
# Send the table to a text file to copy it from
df.to_text('Planets.txt')
This will write the table and any styling we applied to Planets.txt where we can copy it from. We could just as easily copy it right from the terminal as well. Now that we have the table in our clipboard, we can paste and embed it anywhere we can input text! For example, here's the result of pasting it into a PowerPoint slide, along with a comparison using PowerPoint's native table feature:

While its true you'll have more control using the application-specific table feature, you'll have to first figure out how to do it in their sandbox. It takes me an embarrassingly long time to create a table in PowerPoint, not to mention styling it and how to import data without typing it in cell by cell. On the other hand, it only took a second to copy & paste the table from Planets.txt that we generated from SQLDataModel. This applies to anywhere you can input text and use a monospace font! To view a detailed summary of available styles, jump to the table styles portion of the docs.
For all the SQLDataModel examples, the same basic workflow and pattern is present:
import sqldatamodel as sdm
# Extract: Create the model from a source
df = sdm.from_data(...)
# Transform: Manipulate the data if needed
df['New Column'] = df['Column A'].apply(func)
# Load: Move it to a destination format
df.to_text('table.txt') # to_csv, to_json, to_latex, to_markdown, to_html, ..., etc.
We can take a step back and illustrate the broader source, transform, destination flow with SQLDataModel like this:

Regardless of where the data originated or where it ends up, SQLDataModel's best use-case is to be the light-weight intermediary that's agnostic to the original source, or the final destination, of the data.
SQLDataModel seamlessly interacts with a wide range of data formats providing a versatile platform for data extraction, conversion, and writing. Supported formats include:
pyarrow required..csv, files..xlsx files, openpyxl required..html files including formatted string literals..json files, JSON-like objects, or JSON formatted sring literals..tex files, LaTeX formatted string literals..MD files, Markdown formatted string literals.numpy.ndarray objects, numpy required.pandas.DataFrame objects, pandas required..parquet files, pyarrow required..pkl files, package uses .sdm extension when pickling for SQLDataModel metadata.polars.DataFrame objects, polars required.sqlite3 module.psycopg2 package.pyodbc package.cx_Oracle package.teradatasql package..txt files including other SQLDataModel string representations.\t: Tab separated values or .tsv files.\s: Single space or whitespace separated values.;: Semicolon separated values.|: Pipe separated values.:: Colon separated values.,: Comma separated values or .csv files..xml files including XML formatted string literals.dict objects.list objects.tuple objects.namedtuples objects.Note that SQLDataModel does not install any additional dependencies by default. This is done to keep the package as light-weight and small as possible. This means that to use package dependent methods like to_parquet() or the inverse from_parquet() the pyarrow package is required. The same goes for other package dependent methods like those converting to and from pandas and numpy objects.
SQLDataModel's documentation can be found at https://sqldatamodel.readthedocs.io containing detailed descriptions for the key modules in the package. These are listed below as links to their respective sections in the docs:
ANSIColor for terminal styling.HTMLParser for parsing tabular data from the web.JSONEncoder for type casting and encoding JSON data.SQLDataModel for wrapping it all up.However, to skip over the less relevant modules and jump straight to the meat of the package, the SQLDataModel module, click here.
While there are packages/dependencies out there that can accomplish some of the same tasks as SQLDataModel, they're either missing key features or end up being overkill for common tasks like grabbing and converting tables from source A to destination B, or they don't quite handle the full process and require additional dependencies to make it all work. When you find yourself doing the same thing over and over again, eventually you sit down and write a package to do it for you.
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
Thank you!
Ante Tonkovic-Capin
FAQs
SQLDataModel is a lightweight dataframe library designed for efficient data extraction, transformation, and loading (ETL) across various sources and destinations, providing an efficient alternative to common setups like pandas, numpy, and sqlalchemy while also providing additional features without the overhead of external dependencies.
We found that SQLDataModel demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.

Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
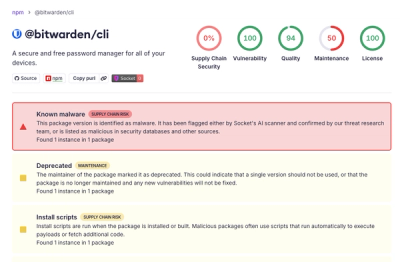
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.