
Product
Introducing Socket Fix for Safe, Automated Dependency Upgrades
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.
By John-David Dalton - Apr 25, 2025
a-pandas-ex-regex-enhancements
Advanced tools
Get repeated capture groups, search without having to fear Exceptions in any df/Series, convert results to appropriate dtypes, use fast Trie regex
###Installation
pip install a-pandas-ex-regex-enhancements
###Usage
from a_pandas_ex_regex_enhancements import pd_add_regex_enhancements
pd_add_regex_enhancements()
import pandas as pd
pandas.DataFrame.ds_trie_regex_search / pandas.Series.ds_trie_regex_search
pandas.DataFrame.ds_trie_regex_sub / pandas.Series.ds_trie_regex_sub
pandas.DataFrame.ds_trie_regex_find_all / pandas.Series.ds_trie_regex_find_all
pandas.DataFrame.ds_regex_find_all / pandas.Series.ds_regex_find_all
pandas.DataFrame.ds_regex_find_all_special / pandas.Series.ds_regex_find_all_special
pandas.DataFrame.ds_regex_search / pandas.Series.ds_regex_search
pandas.DataFrame.ds_regex_sub / pandas.Series.ds_regex_sub
###How to use the new methods
#Using this method, you can get each match from REPEATED CAPTURE GROUPS! (A very rare feature in regex engines)
#Besides that, you will see the exact position of each group/match.
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
special=df.ds_regex_find_all_special(r'\b(Ma(\w)+)(\w+)\b', dtype_string=False)
aa_start_0 ... aa_match_6
aa_index aa_column aa_whole_match aa_whole_start aa_whole_end aa_group ...
7 Name Master 9 15 0 9 ... NaN
1 9 ... NaN
2 11 ... NaN
3 14 ... NaN
10 Name Marguerite 17 27 0 17 ... NaN
... ... ...
885 Name Margaret 20 28 3 27 ... NaN
887 Name Margaret 14 22 0 14 ... NaN
1 14 ... NaN
2 16 ... NaN
3 21 ... NaN
#If you use any common regex engine, you can't get the repeated capture groups, since every new result overwrites the old one:
import re
re.findall('(Ma(\w)+)', 'Margaret')
Out[11]: [('Margaret', 't')]
#Using this method you will get all repeated capture groups, they won't be overwritten!
#Results for index 887
aa_start_0 aa_start_1 aa_start_2 aa_start_3 aa_start_4 aa_start_5 aa_start_6 aa_stop_0 aa_stop_1 aa_stop_2 aa_stop_3 aa_stop_4 aa_stop_5 aa_stop_6 aa_match_0 aa_match_1 aa_match_2 aa_match_3 aa_match_4 aa_match_5 aa_match_6
aa_column aa_whole_match aa_whole_start aa_whole_end aa_group
Name Margaret 14 22 0 14 <NA> <NA> <NA> <NA> <NA> <NA> 22 <NA> <NA> <NA> <NA> <NA> <NA> Margaret <NA> <NA> <NA> <NA> <NA> <NA>
1 14 <NA> <NA> <NA> <NA> <NA> <NA> 21 <NA> <NA> <NA> <NA> <NA> <NA> Margare <NA> <NA> <NA> <NA> <NA> <NA>
2 16 17 18 19 20 <NA> <NA> 17 18 19 20 21 <NA> <NA> r g a r e <NA> <NA>
3 21 <NA> <NA> <NA> <NA> <NA> <NA> 22 <NA> <NA> <NA> <NA> <NA> <NA> t <NA> <NA> <NA> <NA> <NA> <NA>
If you want to convert the results to the best available dtype, use:
df.ds_regex_find_all_special(r'\b(Ma(\w)+)(\w+)\b', dtype_string=False)
Out[3]:
aa_start_0 ... aa_match_6
#aa_index aa_column aa_whole_match aa_whole_start aa_whole_end aa_group ...
7 Name Master 9 15 0 9 ... <NA>
1 9 ... <NA>
2 11 ... <NA>
3 14 ... <NA>
10 Name Marguerite 17 27 0 17 ... <NA>
... ... ...
885 Name Margaret 20 28 3 27 ... <NA>
887 Name Margaret 14 22 0 14 ... <NA>
1 14 ... <NA>
2 16 ... <NA>
3 21 ... <NA>
[764 rows x 21 columns]
aa_start_0 uint8
aa_start_1 Int64
aa_start_2 Int64
aa_start_3 Int64
aa_start_4 Int64
aa_start_5 Int64
aa_start_6 Int64
aa_stop_0 uint8
aa_stop_1 Int64
aa_stop_2 Int64
aa_stop_3 Int64
aa_stop_4 Int64
aa_stop_5 Int64
aa_stop_6 Int64
aa_match_0 category
aa_match_1 category
aa_match_2 category
aa_match_3 category
aa_match_4 category
aa_match_5 category
aa_match_6 category
Parameters:
df: Union[pd.DataFrame, pd.Series]
regular_expression: str
Syntax from https://pypi.org/project/regex/
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
Returns:
Union[pd.Series, pd.DataFrame]
#Use regex.findall against a DataFrame/Series without having to fear any exception! You can get
#the results as strings (dtype_string=True) or even as float, int, category (dtype_string=False) - Whatever
#fits best!
#Some examples
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
df.Name.ds_regex_find_all(regular_expression=r'(\bM\w+\b)\s+(\bW\w+\b)')
result_0 result_1
426 Name Maria Winfield
472 Name Mary Worth
862 Name Margaret Welles
multilinetest=df.Name.map(lambda x: f'{x}\n' * 3) #Every name 3x in each cell
multilinetest.ds_regex_find_all(regular_expression=r'^.*(\bM\w+\b)\s+(\bW\w+\b)', line_by_line=False)
Out[3]:
result_0 result_1
58 Name Mirium West
426 Name Maria Winfield
472 Name Mary Worth
862 Name Margaret Welles
multilinetest.ds_regex_find_all(regular_expression=r'^.*(\bM\w+\b)\s+(\bW\w+\b)', line_by_line=True)
Out[7]:
result_0 result_1
426 Name Maria Winfield
Name Maria Winfield
Name Maria Winfield
472 Name Mary Worth
Name Mary Worth
Name Mary Worth
862 Name Margaret Welles
Name Margaret Welles
Name Margaret Welles
#By using line_by_line=True you can be sure that the regex engine will check every single line!
Parameters:
df: Union[pd.DataFrame, pd.Series]
regular_expression: str
Syntax from https://pypi.org/project/regex/
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
#If you have a huge list of words you want to search/sub/find_all on this list, you can try to use the Trie regex methods to get the job done faster
#It is worth trying if:
#1) your DataFrame/Series has a lot of text in each cell
#2) you want to search for a lot of words in each cell
#
#The more words you have, and the more text is in each cell, the faster it gets.
#If you want to know more about, I recommend: https://stackoverflow.com/a/42789508/15096247
Example:
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
allstrings=pd.DataFrame([[df.Name.to_string() *2] *2,[df.Name.to_string() *2] *2]) #lets create a little dataframe with a lot of text in each cell
hugeregexlist=df.Name.str.extract(r'^\s*(\w+)').drop_duplicates()[0].to_list() #lets get all names (first word) in the titanic DataFrame
#it should look like that: ['Braund', 'Cumings', 'Heikkinen', 'Futrelle', 'Allen', 'Moran', 'McCarthy', 'Palsson', 'Johnson', 'Nasser' ... ]
%timeit allstrings.ds_trie_regex_find_all(hugeregexlist,add_left_to_regex=r'\b',add_right_to_regex=r'\b')
776 ms ± 2.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
allstrings.ds_trie_regex_find_all(hugeregexlist, add_left_to_regex=r'\b', add_right_to_regex=r'\b')
Out[6]:
result_0 result_1 result_2 ... result_2133 result_2134 result_2135
0 0 Braund Harris Cumings ... Johnston Behr Dooley
1 Braund Harris Cumings ... Johnston Behr Dooley
1 0 Braund Harris Cumings ... Johnston Behr Dooley
1 Braund Harris Cumings ... Johnston Behr Dooley
Let's compare with a regular regex search
hugeregex=r"\b(?:" + "|".join([f'(?:{y})' for y in df.Name.str.extract(r'^\s*(\w+)').drop_duplicates()[0].to_list()]) + r")\b" #let's create a regex from all names
#it should look like this: '\\b(?:(?:Braund)|(?:Cumings)|(?:Heikkinen)|(?:Futrelle)|(?:Allen)|(?:Moran)|(?:McCarthy)|(?:Palsson)|(?:Johnson)|(?:Na...
%timeit allstrings.ds_regex_find_all(hugeregex)
945 ms ± 3.14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
#Not bad, right? But it still can a lot better! Try it yourself!
#Another good thing is that you can search in every cell, no matter what dtype it is.
#There won't be thrown any exception, because everything is converted to string before performing any action.
#If you pass "dtype_string=False", each column will be converted to the best available dtype after the actions have been completed
Parameters:
df: Union[pd.DataFrame, pd.Series]
wordlist: list[str]
All strings you are looking for
add_left_to_regex: str
if you want to add something before the generated Trie regex -> \b for example
allstrings.ds_trie_regex_find_all(hugeregexlist,add_left_to_regex=r'\b',add_right_to_regex=r'\b')
(default = "")
add_right_to_regex: str
if you want to add something after the generated Trie regex -> \b for example
allstrings.ds_trie_regex_find_all(hugeregexlist,add_left_to_regex=r'\b',add_right_to_regex=r'\b')
(default = "")
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
#Use regex.sub against a DataFrame/Series without having to fear any exception! You can get
#the results as strings (dtype_string=True) or even as float, int, category (dtype_string=False) - Whatever
#fits best!
#
#Some examples:
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
subst=df.ds_regex_sub(regular_expression=r'^\b8\d(\d)\b', replace=r'\g<1>00000',dtype_string=False)
Out[5]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 <NA> S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 <NA> S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 <NA> S
.. ... ... ... ... ... ... ...
886 700000 0 2 ... 13.0000 <NA> S
887 800000 1 1 ... 30.0000 B42 S
888 900000 0 3 ... 23.4500 <NA> S
889 0 1 1 ... 30.0000 C148 C
890 100000 0 3 ... 7.7500 <NA> Q
[891 rows x 12 columns]
subst.dtypes
Out[8]:
PassengerId uint32
Survived uint8
Pclass uint8
Name string
Sex category
Age object
SibSp uint8
Parch uint8
Ticket object
Fare float64
Cabin category
Embarked category
#As you can see, the numbers that we have substituted have been converted to int
#Let's do something like math.floor in a very unconventional way :)
df.Fare
Out[16]:
0 7.2500
1 71.2833
2 7.9250
3 53.1000
4 8.0500
...
886 13.0000
887 30.0000
888 23.4500
889 30.0000
890 7.7500
Name: Fare, Length: 891, dtype: float64
Fareint=df.Fare.ds_regex_sub(r'(\d+)\.\d+$', r'\g<1>',dtype_string=False)
0 7
1 71
2 7
3 53
4 8
.. ...
886 13
887 30
888 23
889 30
890 7
Fareint.dtypes
Out[18]:
Fare uint16
#You should not use this method if there are other ways to convert float to int.
#It serves best for data cleaning, at least that's what I am using it for.
Parameters:
df: Union[pd.DataFrame, pd.Series]
regular_expression: str
Syntax from https://pypi.org/project/regex/
replace: str
the replacement you want to use (groups are allowed)
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
#Check out the docs of df.trie_regex_find_all() for detailed information
#Some examples with DataFrames / Series
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
#hugeregexlist = ['Braund', 'Cumings', 'Heikkinen', 'Futrelle', 'Allen', 'Moran', 'McCarthy', 'Palsson', 'Johnson', 'Nasser' ... ]
df.Name.ds_trie_regex_sub(hugeregexlist, 'HANS',add_left_to_regex=r'^\b',add_right_to_regex=r'\b')
Out[16]:
Name
0 HANS, Mr. Owen Harris
1 HANS, Mrs. John Bradley (Florence Briggs Thayer)
2 HANS, Miss. Laina
3 HANS, Mrs. Jacques Heath (Lily May Peel)
4 HANS, Mr. William Henry
.. ...
886 HANS, Rev. Juozas
887 HANS, Miss. Margaret Edith
888 HANS, Miss. Catherine Helen "Carrie"
889 HANS, Mr. Karl Howell
890 HANS, Mr. Patrick
[891 rows x 1 columns]
allstrings.ds_trie_regex_search(hugeregexlist,line_by_line=True)
Out[25]:
result_0
0 0 Braund
0 Cumings
0 Heikkinen
0 Futrelle
0 Allen
.. ...
1 1 Montvila
1 Graham
1 Johnston
1 Behr
1 Dooley
[7124 rows x 1 columns]
Parameters:
df: Union[pd.DataFrame, pd.Series]
wordlist: list[str]
All strings you are looking for
replace: str
the replacement you want to use (groups are allowed)
add_left_to_regex: str
if you want to add something before the generated Trie regex -> \b for example
allstrings.ds_trie_regex_find_all(hugeregexlist,add_left_to_regex=r'\b',add_right_to_regex=r'\b')
(default = "")
add_right_to_regex: str
if you want to add something after the generated Trie regex -> \b for example
allstrings.ds_trie_regex_find_all(hugeregexlist,add_left_to_regex=r'\b',add_right_to_regex=r'\b')
(default = "")
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
#Use regex.search against a DataFrame/Series without having to fear any exception! You can get
#the results as strings (dtype_string=True) or even as float, int, category (dtype_string=False) - Whatever
#fits best!
#
#Some examples
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
multilinetest=df.Name.map(lambda x: f'{x}\n' * 3) #Every name 3x in each cell to test line_by_line
#using line_by_line=False
multilinetest.ds_regex_search(regular_expression=r'^.*(\bM\w+\b)\s+(\bW\w+\b)', line_by_line=False, flags=re.IGNORECASE)
Out[13]:
result_0
58 Name West, Miss. Constance Mirium\nWest
Name Mirium
Name West
426 Name Clarke, Mrs. Charles V (Ada Maria Winfield
Name Maria
Name Winfield
472 Name West, Mrs. Edwy Arthur (Ada Mary Worth
Name Mary
Name Worth
862 Name Swift, Mrs. Frederick Joel (Margaret Welles
Name Margaret
Name Welles
#using line_by_line=True
multilinetest.ds_regex_search(regular_expression=r'^.*(\bM\w+\b)\s+(\bW\w+\b)', line_by_line=True, flags=re.IGNORECASE)
Out[19]:
result_0
426 Name Clarke, Mrs. Charles V (Ada Maria Winfield
Name Maria
Name Winfield
Name Clarke, Mrs. Charles V (Ada Maria Winfield
Name Maria
Name Winfield
Name Clarke, Mrs. Charles V (Ada Maria Winfield
Name Maria
Name Winfield
472 Name West, Mrs. Edwy Arthur (Ada Mary Worth
Name Mary
Name Worth
Name West, Mrs. Edwy Arthur (Ada Mary Worth
Name Mary
Name Worth
Name West, Mrs. Edwy Arthur (Ada Mary Worth
Name Mary
Name Worth
862 Name Swift, Mrs. Frederick Joel (Margaret Welles
Name Margaret
Name Welles
Name Swift, Mrs. Frederick Joel (Margaret Welles
Name Margaret
Name Welles
Name Swift, Mrs. Frederick Joel (Margaret Welles
Name Margaret
Name Welles
#Now, we get a match for each line!
Parameters:
df: Union[pd.DataFrame, pd.Series]
regular_expression: str
Syntax from https://pypi.org/project/regex/
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
#Use regex.sub against a DataFrame/Series without having to fear any exception! You can get
#the results as strings (dtype_string=True) or even as float, int, category (dtype_string=False) - Whatever
#fits best!
#
#Some examples
df=pd.read_csv( "https://github.com/pandas-dev/pandas/raw/main/doc/data/titanic.csv")
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
subst=df.ds_regex_sub(regular_expression=r'^\b8\d(\d)\b', replace=r'\g<1>00000',dtype_string=False)
Out[5]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 <NA> S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 <NA> S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 <NA> S
.. ... ... ... ... ... ... ...
886 700000 0 2 ... 13.0000 <NA> S
887 800000 1 1 ... 30.0000 B42 S
888 900000 0 3 ... 23.4500 <NA> S
889 0 1 1 ... 30.0000 C148 C
890 100000 0 3 ... 7.7500 <NA> Q
[891 rows x 12 columns]
subst.dtypes
Out[8]:
PassengerId uint32
Survived uint8
Pclass uint8
Name string
Sex category
Age object
SibSp uint8
Parch uint8
Ticket object
Fare float64
Cabin category
Embarked category
#As you can see, the numbers that we have substituted have been converted to int
#Let's do something like math.floor in a very unconventional way :)
df.Fare
Out[16]:
0 7.2500
1 71.2833
2 7.9250
3 53.1000
4 8.0500
...
886 13.0000
887 30.0000
888 23.4500
889 30.0000
890 7.7500
Name: Fare, Length: 891, dtype: float64
Fareint=df.Fare.ds_regex_sub(r'(\d+)\.\d+$', r'\g<1>',dtype_string=False)
0 7
1 71
2 7
3 53
4 8
.. ...
886 13
887 30
888 23
889 30
890 7
Fareint.dtypes
Out[18]:
Fare uint16
#You should not use this method if there are other ways to convert float to int.
#It serves best for data cleaning, at least that's what I am using it for.
Parameters:
df: Union[pd.DataFrame, pd.Series]
regular_expression: str
Syntax from https://pypi.org/project/regex/
replace: str
the replacement you want to use (groups are allowed)
flags:int
You can use any flag that is available here: https://pypi.org/project/regex/
(default =regex.UNICODE)
dtype_string:bool
If True, it returns all results as a string
If False, data types are converted to the best available
(default =True)
line_by_line:bool
If you want to split the line before searching. Useful, if you want to use ^....$ more than once.
(default =False)
Returns:
Union[pd.Series, pd.DataFrame]
FAQs
Get repeated capture groups, search without having to fear Exceptions in any df/Series, convert results to appropriate dtypes, use fast Trie regex
We found that a-pandas-ex-regex-enhancements demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.

Security News
CISA denies CVE funding issues amid backlash over a new CVE foundation formed by board members, raising concerns about transparency and program governance.
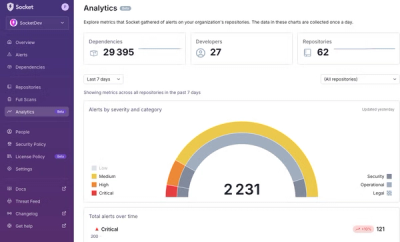
Product
We’re excited to announce a powerful new capability in Socket: historical data and enhanced analytics.