Product
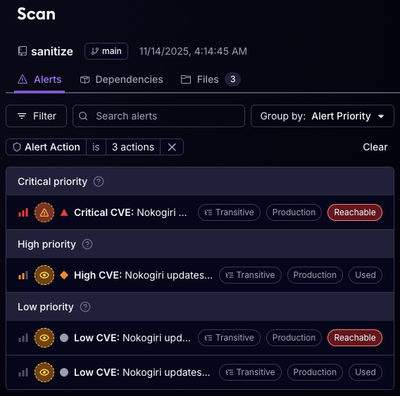
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
arcosparse
Advanced tools
Helper to download and subset sparse data that has been Arcoified and are available through STAC and sqlite formated data
[!WARNING] This library is still in development. Breaking changes might be introduced from version
0.y.zto0.y+1.z.
arcosparse.subset_and_return_dataframeSubset the data based on the input and return a dataframe.
arcosparse.subset_and_saveSubset the data based on the input and return data as a partitioned parquet file.
It means that the data is saved in one folder and in this folder there are many small parquet files. Though, you can open all the data at once.
To open the data into a dataframe, use this snippet:
import glob
output_path = "some_folder"
# Get all partitioned Parquet files
parquet_files = glob.glob(f"{output_path}/*.parquet")
# # Read all files into a single dataframe
df = pd.concat(pd.read_parquet(file) for file in parquet_files)
arcosparse.get_entitiesA function to get the metadata about the entities that are available in the dataset. Since all the information is retrieved from the metadata, the argument is the url_metadata, the same used for the subset.
Returns a list of arcosparse.Entity. It contains information about the entities available in the dataset:
entity_id: same as the entity_id column in the result of a subset.entity_type: same as the entity_type column in the result of a subset.doi: the DOI of the entity.institution: the institution associated with the entity.arcosparse.get_dataset_metadataA function to get the metadata about the dataset. Since all the information is retrieved from the metadata, the argument is the url_metadata, the same used for the subset.
Returns an object arcosparse.Dataset. It contains information about the dataset:
dataset_id: the ID of the dataset.variables: a list of the names of the variables available in the dataset.assets: a list of the names of the assets available in the dataset.coordinates: a list of arcosparse.DatasetCoordinate objects. Each object contains the following information:
coordinate_id: the ID of the coordinate.unit: the unit of the coordinate.minimum: the minimum value of the coordinate.maximum: the maximum value of the coordinate.step: the step of the coordinate.values: the values of the coordinate.dateutil.parser to parse the date strings correctly.get_dataset_metadata. It returns an arcosparse.Dataset object.get_entities_ids. Use get_entities as a replacement. Example:# old code
my_entities = get_entities_ids(url_metadata)
# new code
my_entities = [entity.entity_id for entity in get_entities(url_metadata)]
get_entities. It returns a list of Entity objects.columns_rename argument. Now, it deepcopy it to modify it after that.get_platforms_names functiondatetime.to_timestamp does not support dates before 1970-1-1 (i.e. negative values for timestamps).columns_rename argument to subset_and_return_dataframe and subset_and_save to be able to choose the names of the columns in the output.FAQs
Helper to download and subset sparse data that has been Arcoified and are available through STAC and sqlite formated data
We found that arcosparse demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.