
Product
Introducing Data Exports
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
By Ola Adekola - Apr 23, 2026
async-scrape
Advanced tools
A package designed to scrape webpages using aiohttp and asyncio. Has some error handling to overcome common issues such as sites blocking you after n requests over a short period.

Async-scrape is a package which uses asyncio and aiohttp to scrape websites and has useful features built in.
Async-scrape requires C++ Build tools v15+ to run.
pip install async-scrape
Key inpur parameters:
post_process_func - the callable used to process the returned responsepost_process_kwargs - and kwargs to be passed to the callableuse_proxy - should a proxy be used (if this is true then either provide a proxy or pac_url variable)attempt_limit - how manay attempts should each request be given before it is marked as failedrest_wait - how long should the programme pause between loopscall_rate_limit - limits the rate of requests (useful to stop getting blocked from websites)randomise_headers - if set to True a new set of headers will be generated between each request# Create an instance
from async_scrape import AsyncScrape
def post_process(html, resp, **kwargs):
"""Function to process the gathered response from the request"""
if resp.status == 200:
return "Request worked"
else:
return "Request failed"
async_Scrape = AsyncScrape(
post_process_func=post_process,
post_process_kwargs={},
fetch_error_handler=None,
use_proxy=False,
proxy=None,
pac_url=None,
acceptable_error_limit=100,
attempt_limit=5,
rest_between_attempts=True,
rest_wait=60,
call_rate_limit=None,
randomise_headers=True
)
urls = [
"https://www.google.com",
"https://www.bing.com",
]
resps = async_Scrape.scrape_all(urls)
# Create an instance
from async_scrape import AsyncScrape
def post_process(html, resp, **kwargs):
"""Function to process the gathered response from the request"""
if resp.status == 200:
return "Request worked"
else:
return "Request failed"
async_Scrape = AsyncScrape(
post_process_func=post_process,
post_process_kwargs={},
fetch_error_handler=None,
use_proxy=False,
proxy=None,
pac_url=None,
acceptable_error_limit=100,
attempt_limit=5,
rest_between_attempts=True,
rest_wait=60,
call_rate_limit=None,
randomise_headers=True
)
urls = [
"https://eos1jv6curljagq.m.pipedream.net",
"https://eos1jv6curljagq.m.pipedream.net",
]
payloads = [
{"value": 0},
{"value": 1}
]
resps = async_Scrape.scrape_all(urls, payloads=payloads)
Response object is a list of dicts in the format:
{
"url":url, # url of request
"req":req, # combination of url and params
"func_resp":func_resp, # response from post processing function
"status":resp.status, # http status
"error":None # any error encountered
}
MIT
Free Software, Hell Yeah!
FAQs
A package designed to scrape webpages using aiohttp and asyncio. Has some error handling to overcome common issues such as sites blocking you after n requests over a short period.
We found that async-scrape demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
Research
/Security News
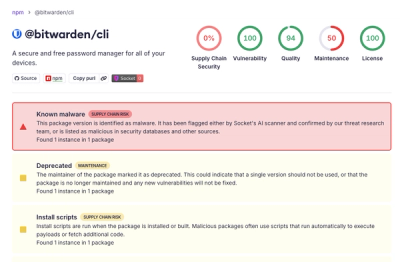
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.

Research
/Security News
Docker and Socket have uncovered malicious Checkmarx KICS images and suspicious code extension releases in a broader supply chain compromise.