{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Research
2025 Report: Destructive Malware in Open Source Packages
Destructive malware is rising across open source registries, using delays and kill switches to wipe code, break builds, and disrupt CI/CD.
By Kush Pandya - Dec 24, 2025
autofit
Advanced tools
.. |binder| image:: https://mybinder.org/badge_logo.svg :target: https://mybinder.org/v2/gh/Jammy2211/autofit_workspace/HEAD
.. |RTD| image:: https://readthedocs.org/projects/pyautofit/badge/?version=latest :target: https://pyautofit.readthedocs.io/en/latest/?badge=latest :alt: Documentation Status
.. |Tests| image:: https://github.com/rhayes777/PyAutoFit/actions/workflows/main.yml/badge.svg :target: https://github.com/rhayes777/PyAutoFit/actions
.. |Build| image:: https://github.com/rhayes777/PyAutoBuild/actions/workflows/release.yml/badge.svg :target: https://github.com/rhayes777/PyAutoBuild/actions
.. |JOSS| image:: https://joss.theoj.org/papers/10.21105/joss.02550/status.svg :target: https://doi.org/10.21105/joss.02550
.. image:: https://www.repostatus.org/badges/latest/active.svg :target: https://www.repostatus.org/#active :alt: Project Status: Active
.. image:: https://img.shields.io/pypi/pyversions/autofit :target: https://pypi.org/project/autofit/ :alt: Python Versions
.. image:: https://img.shields.io/pypi/v/autofit.svg :target: https://pypi.org/project/autofit/ :alt: PyPI Version
|binder| |Tests| |Build| |RTD| |JOSS|
Installation Guide <https://pyautofit.readthedocs.io/en/latest/installation/overview.html>_ |
readthedocs <https://pyautofit.readthedocs.io/en/latest/index.html>_ |
Introduction on Binder <https://mybinder.org/v2/gh/Jammy2211/autofit_workspace/release?filepath=notebooks/overview/overview_1_the_basics.ipynb>_ |
HowToFit <https://pyautofit.readthedocs.io/en/latest/howtofit/howtofit.html>_
PyAutoFit is a Python based probabilistic programming language for model fitting and Bayesian inference of large datasets.
The basic PyAutoFit API allows us a user to quickly compose a probabilistic model and fit it to data via a log likelihood function, using a range of non-linear search algorithms (e.g. MCMC, nested sampling).
Users can then set up PyAutoFit scientific workflow, which enables streamlined modeling of small datasets with tools to scale up to large datasets.
PyAutoFit supports advanced statistical methods, most
notably a big data framework for Bayesian hierarchical analysis <https://pyautofit.readthedocs.io/en/latest/features/graphical.html>_.
The following links are useful for new starters:
The PyAutoFit readthedocs <https://pyautofit.readthedocs.io/en/latest>, which includes an installation guide <https://pyautofit.readthedocs.io/en/latest/installation/overview.html> and an overview of PyAutoFit's core features.
The introduction Jupyter Notebook on Binder <https://mybinder.org/v2/gh/Jammy2211/autofit_workspace/release?filepath=notebooks/overview/overview_1_the_basics.ipynb>_, where you can try PyAutoFit in a web browser (without installation).
The autofit_workspace GitHub repository <https://github.com/Jammy2211/autofit_workspace>, which includes example scripts and the HowToFit Jupyter notebook lectures <https://github.com/Jammy2211/autofit_workspace/tree/main/notebooks/howtofit> which give new users a step-by-step introduction to PyAutoFit.
Support for installation issues, help with Fit modeling and using PyAutoFit is available by
raising an issue on the GitHub issues page <https://github.com/rhayes777/PyAutoFit/issues>_.
We also offer support on the PyAutoFit Slack channel <https://pyautoFit.slack.com/>, where we also provide the
latest updates on PyAutoFit. Slack is invitation-only, so if you'd like to join send
an email <https://github.com/Jammy2211> requesting an invite.
For users less familiar with Bayesian inference and scientific analysis you may wish to read through the HowToFits lectures. These teach you the basic principles of Bayesian inference, with the content pitched at undergraduate level and above.
A complete overview of the lectures is provided on the HowToFit readthedocs page <https://pyautofit.readthedocs.io/en/latest/howtofit/howtofit.htmll>_
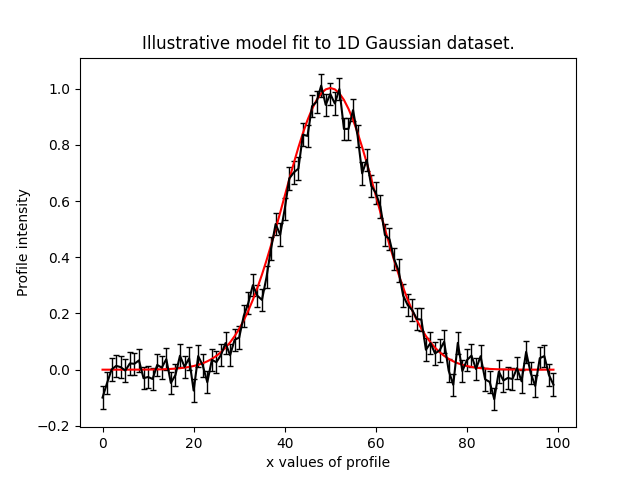
To illustrate the PyAutoFit API, we use an illustrative toy model of fitting a one-dimensional Gaussian to
noisy 1D data. Here's the data (black) and the model (red) we'll fit:
.. image:: https://raw.githubusercontent.com/rhayes777/PyAutoFit/main/files/toy_model_fit.png :width: 400
We define our model, a 1D Gaussian by writing a Python class using the format below:
.. code-block:: python
class Gaussian:
def __init__(
self,
centre=0.0, # <- PyAutoFit recognises these
normalization=0.1, # <- constructor arguments are
sigma=0.01, # <- the Gaussian's parameters.
):
self.centre = centre
self.normalization = normalization
self.sigma = sigma
"""
An instance of the Gaussian class will be available during model fitting.
This method will be used to fit the model to data and compute a likelihood.
"""
def model_data_from(self, xvalues):
transformed_xvalues = xvalues - self.centre
return (self.normalization / (self.sigma * (2.0 * np.pi) ** 0.5)) * \
np.exp(-0.5 * (transformed_xvalues / self.sigma) ** 2.0)
PyAutoFit recognises that this Gaussian may be treated as a model component whose parameters can be fitted for via
a non-linear search like emcee <https://github.com/dfm/emcee>_.
To fit this Gaussian to the data we create an Analysis object, which gives PyAutoFit the data and a
log_likelihood_function describing how to fit the data with the model:
.. code-block:: python
class Analysis(af.Analysis):
def __init__(self, data, noise_map):
self.data = data
self.noise_map = noise_map
def log_likelihood_function(self, instance):
"""
The 'instance' that comes into this method is an instance of the Gaussian class
above, with the parameters set to values chosen by the non-linear search.
"""
print("Gaussian Instance:")
print("Centre = ", instance.centre)
print("normalization = ", instance.normalization)
print("Sigma = ", instance.sigma)
"""
We fit the ``data`` with the Gaussian instance, using its
"model_data_from" function to create the model data.
"""
xvalues = np.arange(self.data.shape[0])
model_data = instance.model_data_from(xvalues=xvalues)
residual_map = self.data - model_data
chi_squared_map = (residual_map / self.noise_map) ** 2.0
log_likelihood = -0.5 * sum(chi_squared_map)
return log_likelihood
We can now fit our model to the data using a non-linear search:
.. code-block:: python
model = af.Model(Gaussian)
analysis = Analysis(data=data, noise_map=noise_map)
emcee = af.Emcee(nwalkers=50, nsteps=2000)
result = emcee.fit(model=model, analysis=analysis)
The result contains information on the model-fit, for example the parameter samples, maximum log likelihood
model and marginalized probability density functions.
FAQs
Classy Probabilistic Programming
We found that autofit demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
Destructive malware is rising across open source registries, using delays and kill switches to wipe code, break builds, and disrupt CI/CD.

Security News
Socket CTO Ahmad Nassri shares practical AI coding techniques, tools, and team workflows, plus what still feels noisy and why shipping remains human-led.

Research
/Security News
A five-month operation turned 27 npm packages into durable hosting for browser-run lures that mimic document-sharing portals and Microsoft sign-in, targeting 25 organizations across manufacturing, industrial automation, plastics, and healthcare for credential theft.