
Data transformation for AI
Ultra performant data transformation framework for AI, with core engine written in Rust. Support incremental processing and data lineage out-of-box. Exceptional developer velocity. Production-ready at day 0.
⭐ Drop a star to help us grow!

CocoIndex makes it super easy to transform data with AI workloads, and keep source data and target in sync effortlessly.
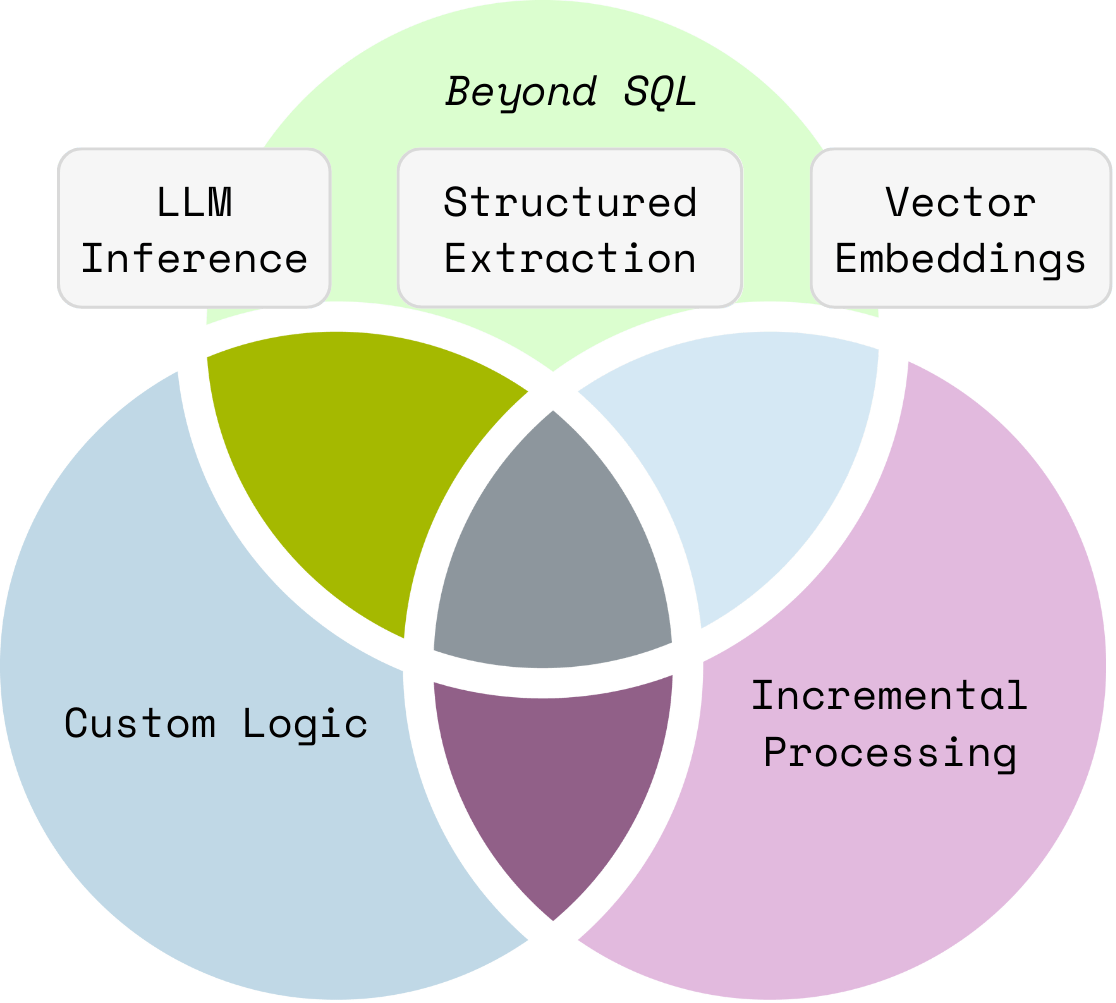
Either creating embedding, building knowledge graphs, or any data transformations - beyond traditional SQL.
Exceptional velocity
Just declare transformation in dataflow with ~100 lines of python
data['content'] = flow_builder.add_source(...)
data['out'] = data['content']
.transform(...)
.transform(...)
collector.collect(...)
collector.export(...)
CocoIndex follows the idea of Dataflow programming model. Each transformation creates a new field solely based on input fields, without hidden states and value mutation. All data before/after each transformation is observable, with lineage out of the box.
Particularly, developers don't explicitly mutate data by creating, updating and deleting. They just need to define transformation/formula for a set of source data.
Build like LEGO
Native builtins for different source, targets and transformations. Standardize interface, make it 1-line code switch between different components.

Data Freshness
CocoIndex keep source data and target in sync effortlessly.

It has out-of-box support for incremental indexing:
- minimal recomputation on source or logic change.
- (re-)processing necessary portions; reuse cache when possible
Quick Start:
If you're new to CocoIndex, we recommend checking out
Setup
- Install CocoIndex Python library
pip install -U cocoindex
- Install Postgres if you don't have one. CocoIndex uses it for incremental processing.
Define data flow
Follow Quick Start Guide to define your first indexing flow. An example flow looks like:
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
data_scope["documents"] = flow_builder.add_source(cocoindex.sources.LocalFile(path="markdown_files"))
doc_embeddings = data_scope.add_collector()
with data_scope["documents"].row() as doc:
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)
with doc["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
doc_embeddings.collect(filename=doc["filename"], location=chunk["location"],
text=chunk["text"], embedding=chunk["embedding"])
doc_embeddings.export(
"doc_embeddings",
cocoindex.targets.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])
It defines an index flow like this:

🚀 Examples and demo
More coming and stay tuned 👀!
📖 Documentation
For detailed documentation, visit CocoIndex Documentation, including a Quickstart guide.
🤝 Contributing
We love contributions from our community ❤️. For details on contributing or running the project for development, check out our contributing guide.
Welcome with a huge coconut hug 🥥⋆。˚🤗. We are super excited for community contributions of all kinds - whether it's code improvements, documentation updates, issue reports, feature requests, and discussions in our Discord.
Join our community here:
Support us:
We are constantly improving, and more features and examples are coming soon. If you love this project, please drop us a star ⭐ at GitHub repo  to stay tuned and help us grow.
to stay tuned and help us grow.
License
CocoIndex is Apache 2.0 licensed.






