
Research
PyPI Package Disguised as Instagram Growth Tool Harvests User Credentials
A deceptive PyPI package posing as an Instagram growth tool collects user credentials and sends them to third-party bot services.
By Kush Pandya - Jun 06, 2025
Main objective is to secure fast deployment of crawler system that will help you setup all that you need to get started with data mining interactively over cmd/terminal. Concept is based on long working experience and mistakes that have been learned over the years in data mining and database arhitecture. It could save you a lot of time and effort using this framework. Currently works on Win OS.
Most important thing is that you have python 3 installed on your machine.
With virtual environment (recommended)
To be able to make virtual environment you will need to pip3.7 install virtualenv
Location of your virtual environment on WinOS shoud be C:\Users\YourUsername\Envs
Then create virtual environment py -3.7 -m virtualenv Envs/crawler_framework
By default now your virtual environment should be active if it isn't activate your virtual
environment by writing workon crawler_framework
Now you can install library pip install crawler_framework
Without virtual environment
Just open cmd and write pip3.7 install crawler_framework. This option is ok if you have only one version
of python installed on your system. But if you have more python version installed and you decide to go with this
option you will have to finish some additional question's during configuration of crawler framework.
Like that it will be ensured that everything works ether way.
Before we can deploy anything we must setup connection strings for one or more database servers that we are going to use. Currently supported are PostgreSQL, Oracle and Microsoft SQL Server.
It is recommended to create database on your server that will only be used by framework.
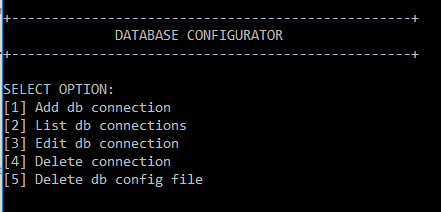
Open cmd/terminal and write config.py. If everything goes well you should see this options below.
It is possible that program asks for some additional information if you have more than one python interpreter
installed on your machine and you did not use virtual environment. But it will be required only once.

Create all database connection's that you think you will use, from database where you will deploy crawler_framework to database where you will store data etc. by selecting option number 1 and then database option number one.
Microsoft SQL Server
If you are using default option be sure to define in ODBC Data sources administrator dsn name that will have
default database that will be used for framework. If you are using pymssql you will define server_ip, port and database
during database configuration stage.
Open cmd/terminal and write config.py. Select option 2 (Deploy framework) and then select option from
the list of connections you created that is going to be used for deployment. This will deploy table structure in selected database
on selected server connection. In our case we will deploy it on PostgreSQL localhost server.
You can skip this if you are not planing to use tor as your proxy provider but only public proxies.
Open cmd/terminal and write config.py. Select option 4 (Tor setup). Then from to setup option select option 1(Install),
this will automatically install tor expert bundle with all necessary directories and subdirectories.
If you have already have installed and then changed default options then this will reset those options back to default just like some kind of reinstall.
Setup option 2 (Tor options) allows you to change some of defaults when constructing our tor network such as how many tor instances should run in same time or how long time must pass before changing and identity of tor instance.
Proxy server is multifunctional program that acquires new proxies(crawlers), test proxies, creates tor network etc.
Open cmd/terminal and write config.py. Select option 3 (Run proxy server).
From suboptions you can select suboption 0 to run all both public proxy and tor service or suboption 1 to run only public proxy gatherer or
suboption 2 to run only tor service.
Suboption 2 is great if you want to run tor service on another pc inside your network.
By doing so you can increase number of tor that will run but it will not hog your local CPU and RAM.
All data will be saved in database where you have deployed crawler_framewok.
If you didn't made deployment then this will probably end with exceptions.
FAQs
Framework for crawling
We found that crawler-framework demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
A deceptive PyPI package posing as an Instagram growth tool collects user credentials and sends them to third-party bot services.

Product
Socket now supports pylock.toml, enabling secure, reproducible Python builds with advanced scanning and full alignment with PEP 751's new standard.

Security News
Research
Socket uncovered two npm packages that register hidden HTTP endpoints to delete all files on command.