Product
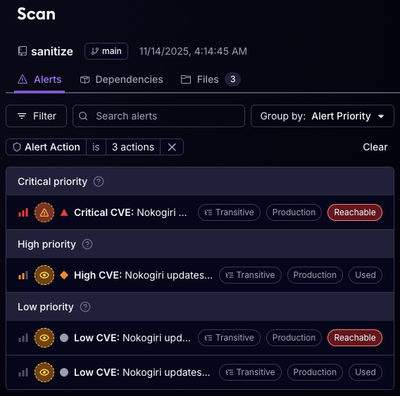
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
Continous Time-Series Clustering And Merging towards Sentiments (CT-SCAMS) is a Python package ddesigned to ensure robust generalization across time stamps for sentiment analysis in policy-related texts.
Continous Time-Series Clustering and Merging towards Sentiments (CT-SCaMS) is a Python package ddesigned to ensure robust generalization across time stamps for sentiment analysis in policy-related texts.
It accounts for the temporal dynamics of evolving policy discourse and evaluates sentiment models under realistic settings that mimic actual policy analysis scenarios.
Key features include:
Continuous time-series clustering to prioritize data points for annotation based on temporal trends.
Advanced model merging techniques to unify multiple models fine-tuned on distinct temporal slices.
Methods:
Continous time series is performed using Ruptures
It supports the following merging techniques:
Uniform Souping
Greedy Souping
Task Arithmetic
TIES
DARE
Fisher Merging
RegMean Merging
The following Python packages are required:
matplotlib
ruptures
pandas
tqdm
torch
transformers
datasets
scikit-learn
numpy
These will be installed automatically when using pip install.
Alternatively, you could directly install them
pip install matplotlib ruptures pandas tqdm torch transformers datasets scikit-learn numpy
You require at least one GPU to use ctscams.
VRAM requirements depend on factors like batch size, model size, etc.
However, at least 12GB of VRAM is recommended
To install in python, simply do the following:
pip install ctscams
To learn how we used it in our experiments, go to demo.ipynb. Alternatively, refer to this quick guide here:
from ctscams import greedy_souping, ties
from ctscams import finetune
from ctscams import cluster_sampling, continous_time_series_clustering
df_climate=continous_time_series_clustering(df=df,time_col="timestamp_col",level="M", plot=False, penalty=0.1) # note that level "M" stands for Month
# perform continous time series clustering and selecting based on the clusters
df=cluster_sampling(df=df,sample_size=10000,stratified_col="cluster"):
df_annotated=df[df["selected"]==1].reset_index(drop=True)
# finetuning
finetune(df=df_annotated, model_name="microsoft/deberta-v3-large",cluster_col_name=None,
folder_name="naive_finetuning/continous_clustering_by_month/climate_change", # note folder name to save our models
text_col='message', label_col="sentiment", label2id={"Anti":0,"Neutral":1,"Pro":2,"News":3},
learning_rate=1e-5, warmup_ratio=0.05, weight_decay=0.001,
epochs=3, batch_size=6, early_stopping_patience=2, return_val_data=False)
# finetuning
df_val=finetune(df=df_annotated, model_name="microsoft/deberta-v3-large",
cluster_col_name="cluster", # the difference is here --> we use "cluster" instead of None
folder_name="batch_finetuning/continous_clustering_by_month/climate_change", # note folder name to save our models
text_col='message',
label_col="sentiment",
label2id={"Anti":0,"Neutral":1,"Pro":2,"News":3},
learning_rate=1e-5,
warmup_ratio=0.05,
weight_decay=0.001,
epochs=8,
batch_size=6,
early_stopping_patience=2,
return_val_data=True) # note TRUE if we want to return validation data.
# Now we perform greedy souping
greedy_souping(
models_folder="models/batch_finetuning/continous_clustering_by_month/climate_change/deberta-v3-large", # where the individual models are saved
save_path="models/merged_models/continous_clustering_by_month/climate_change/greedy_soup/deberta-v3-large", # the merged model will be saved here
df_val=df_val, # validation data.
col_label="sentiment",
text_col='message',
num_labels=4,
label2id={"Anti":0,"Neutral":1,"Pro":2,"News":3})
# the model will be saved under `save_path="models/merged_models/continous_clustering_by_month/climate_change/greedy_soup/deberta-v3-large"`
Alba C, Warner BC, Saxena A, Huang J, An R. Towards Robust Sentiment Analysis of Temporally-Sensitive Policy-Related Online Text. Accepted In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Volume 4: Student Research Workshop. Association for Computational Linguistics; July 26-August 1, 2025; Vienna, Austria.
FAQs
Continous Time-Series Clustering And Merging towards Sentiments (CT-SCAMS) is a Python package ddesigned to ensure robust generalization across time stamps for sentiment analysis in policy-related texts.
We found that ctscams demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.