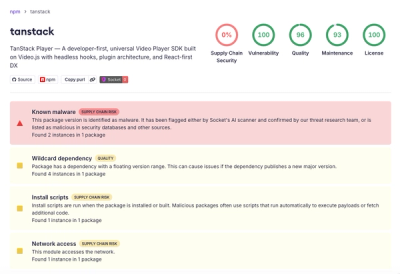
imgutils




















A convenient and user-friendly anime-style image data processing library that integrates various advanced anime-style
image processing models.
Installation
You can simply install it with pip command line from the official PyPI site.
pip install dghs-imgutils
If your operating environment includes a available GPU, you can use the following installation command to achieve higher
performance:
pip install dghs-imgutils[gpu]
For more information about installation, you can refer
to Installation.
Supported or Developing Features
imgutils also includes many other features besides that. For detailed descriptions and examples, please refer to
the official documentation. Here, we won't go into each of them
individually.
Tachie(差分) Detection and Clustering
For the dataset, we need to filter the differences between the tachie(差分). As shown in the following picture

We can use lpips_clustering to cluster such situations as shown below
from imgutils.metrics import lpips_clustering
images = [f'lpips/{i}.jpg' for i in range(1, 10)]
print(images)
print(lpips_clustering(images))
Contrastive Character Image Pretraining
We can use imgutils to extract features from anime character images (containing only a single character), calculate
the visual dissimilarity between two characters, and determine whether two images depict the same character. We can also
perform clustering operations based on this metric, as shown below

from imgutils.metrics import ccip_difference, ccip_clustering
print(ccip_difference('ccip/1.jpg', 'ccip/2.jpg'))
print(ccip_difference('ccip/1.jpg', 'ccip/6.jpg'))
print(ccip_difference('ccip/1.jpg', 'ccip/7.jpg'))
print(ccip_difference('ccip/2.jpg', 'ccip/6.jpg'))
print(ccip_difference('ccip/2.jpg', 'ccip/7.jpg'))
print(ccip_difference('ccip/6.jpg', 'ccip/7.jpg'))
images = [f'ccip/{i}.jpg' for i in range(1, 13)]
print(images)
print(ccip_clustering(images, min_samples=2))
For more usage, please refer
to official documentation of CCIP.
Object Detection
Currently, object detection is supported for anime heads and person, as shown below



Based on practical tests, head detection currently has a very stable performance and can be used for automation tasks.
However, person detection is still being further iterated and will focus on enhancing detection capabilities for
artistic illustrations in the future.
Edge Detection / Lineart Generation
Anime images can be converted to line drawings using the model provided
by patrickvonplaten/controlnet_aux, as shown below.

It is worth noting that the lineart model may consume more computational resources, while canny is the fastest but
has average effect. Therefore, lineart_anime may be the most balanced choice in most cases.
Monochrome Image Detection
When filtering the crawled images, we need to remove monochrome images. However, monochrome images are often not simply
composed of grayscale colors and may still contain colors, as shown by the first two rows of six images in the figure
below

We can use is_monochrome to determine whether an image is monochrome, as shown below:
from imgutils.validate import is_monochrome
print(is_monochrome('mono/1.jpg'))
print(is_monochrome('mono/2.jpg'))
print(is_monochrome('mono/3.jpg'))
print(is_monochrome('mono/4.jpg'))
print(is_monochrome('mono/5.jpg'))
print(is_monochrome('mono/6.jpg'))
print(is_monochrome('colored/7.jpg'))
print(is_monochrome('colored/8.jpg'))
print(is_monochrome('colored/9.jpg'))
print(is_monochrome('colored/10.jpg'))
print(is_monochrome('colored/11.jpg'))
print(is_monochrome('colored/12.jpg'))
For more details, please refer to
the official documentation
.
Truncated Image Check
The following code can be used to detect incomplete image files (such as images interrupted during the download
process):
from imgutils.validate import is_truncated_file
if __name__ == '__main__':
filename = 'test_jpg.jpg'
if is_truncated_file(filename):
print('This image is truncated, you\'d better '
'remove this shit from your dataset.')
else:
print('This image is okay!')
Image Tagging
The imgutils library integrates various anime-style image tagging models, allowing for results similar to the
following:

The ratings, features, and characters in the image can be detected, like this:
import os
from imgutils.tagging import get_wd14_tags
rating, features, chars = get_wd14_tags('skadi.jpg')
print(rating)
print(features)
print(chars)
rating, features, chars = get_wd14_tags('hutao.jpg')
print(rating)
print(features)
print(chars)
We currently integrate the following tagging models:
In addition, if you need to convert the dict-formatted data mentioned above into the text format required for image
training and tagging, you can also use the tags_to_text function (see the
link here) for formatting, as shown
below:
from imgutils.tagging import tags_to_text
tags = {
'panty_pull': 0.6826801300048828,
'panties': 0.958938717842102,
'drinking_glass': 0.9340789318084717,
'areola_slip': 0.41196826100349426,
'1girl': 0.9988248348236084
}
print(tags_to_text(tags))
print(tags_to_text(tags, use_spaces=True))
print(tags_to_text(tags, include_score=True))
When we need to extract the character parts from anime images, we can use
the segment-rgba-with-isnetis
function for extraction and obtain an RGBA format image (with the background part being transparent), just like the
example shown below.

from imgutils.segment import segment_rgba_with_isnetis
mask_, image_ = segment_rgba_with_isnetis('hutao.png')
image_.save('hutao_seg.png')
mask_, image_ = segment_rgba_with_isnetis('skadi.jpg')
image_.save('skadi_seg.png')
This model can be found at https://huggingface.co/skytnt/anime-seg .