
Product
Introducing Socket Fix for Safe, Automated Dependency Upgrades
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.
By John-David Dalton - Apr 25, 2025
![]()
![]()
This is a collection of morphological 3D image operations that are tuned for working with dense 3D labeled images.
We provide the following multithreaded (except where noted) operations:
Highlights compared to other libraries:
Disadvantages versus other libraries:
import fastmorph
# may be binary or unsigned integer 2D or 3D image
labels = np.load("my_labels.npy")
# multi-label capable morphological operators
# they use a 3x3x3 all on structuring element
# dilate picks the mode of surrounding labels
# by default only background (0) labels are filled
morphed = fastmorph.dilate(labels, parallel=2)
# processes every voxel
morphed = fastmorph.dilate(labels, background_only=False, parallel=2)
morphed = fastmorph.erode(labels)
morphed = fastmorph.opening(labels, parallel=2)
morphed = fastmorph.closing(labels, parallel=2)
# You can select grayscale dilation, erosion, opening, and
# closing by passing in a different Mode enum.
# The options are Mode.grey and Mode.multilabel
morphed = fastmorph.dilate(labels, mode=fastmorph.Mode.grey)
morphed = fastmorph.erode(labels, mode=fastmorph.Mode.grey)
# Dilate only supports binary images at this time.
# Radius is specified in physical units, but
# by default anisotropy = (1,1,1) so it is the
# same as voxels.
morphed = fastmorph.spherical_dilate(labels, radius=1, parallel=2, anisotropy=(1,1,1))
# open and close require dialate to work and so are binary only for now
morphed = fastmorph.spherical_open(labels, radius=1, parallel=2, anisotropy=(1,1,1))
morphed = fastmorph.spherical_close(labels, radius=1, parallel=2, anisotropy=(1,1,1))
# The rest support multilabel images.
morphed = fastmorph.spherical_erode(labels, radius=1, parallel=2, anisotropy=(1,1,1))
# Note: for boolean images, this function will directly call fill_voids
# and return a scalar for ct
# For integer images, more processing will be done to deal with multiple labels.
# A dict of { label: num_voxels_filled } for integer images will be returned.
# Note that for multilabel images, by default, if a label is totally enclosed by another,
# a FillError will be raised. If remove_enclosed is True, the label will be overwritten.
filled_labels, ct = fastmorph.fill_holes(labels, return_fill_count=True, remove_enclosed=False)
# If the holes in your segmentation are imperfectly sealed, consider
# using the following options.
filled_labels = fastmorph.fill_holes(
labels,
# runs 2d fill on the sides of the cube for each binary image
fix_borders=True,
# does a dilate and then an erode after filling holes
morphological_closing=True,
)
A test run on an M1 Macbook Pro on connectomics.npy.ckl, a 5123 volume with over 2000 dense labels had the following results for multilabel processing.
erode / 1 thread: 1.553 sec
erode / 2 threads: 0.885 sec
erode / 4 threads: 0.651 sec
dilate / background_only=True / 1 thread: 1.100 sec
dilate / background_only=True / 2 threads: 0.632 sec
dilate / background_only=True / 4 threads: 0.441 sec
dilate / background_only=False / 1 thread: 11.783 sec
dilate / background_only=False / 2 threads: 5.944 sec
dilate / background_only=False / 4 threads: 4.291 sec
dilate / background_only=False / 8 threads: 3.298 sec
scipy grey_dilation / 1 thread 14.648 sec
scipy grey_erode / 1 thread: 14.412 sec
skimage expand_labels / 1 thread: 62.248 sec
Test run on an M1 Macbook Pro with ws.npy.ckl a 5123 volume with tens of thousands of components for multilabel processing.
erode / 1 thread: 2.380 sec
erode / 2 threads: 1.479 sec
erode / 4 threads: 1.164 sec
dilate / background_only=True / 1 thread: 1.598 sec
dilate / background_only=True / 2 threads: 1.011 sec
dilate / background_only=True / 4 threads: 0.805 sec
dilate / background_only=False / 1 thread: 25.182 sec
dilate / background_only=False / 2 threads: 13.513 sec
dilate / background_only=False / 4 threads: 8.749 sec
dilate / background_only=False / 8 threads: 6.640 sec
scipy grey_dilation / 1 thread 21.109 sec
scipy grey_erode / 1 thread: 20.305 sec
skimage expand_labels / 1 thread: 63.247 sec
Here is the performance on a completely zeroed 5123 volume for multilabel processing.
erode / 1 thread: 0.462 sec
erode / 2 threads: 0.289 sec
erode / 4 threads: 0.229 sec
dilate / background_only=True / 1 thread: 2.337 sec
dilate / background_only=True / 2 threads: 1.344 sec
dilate / background_only=True / 4 threads: 1.021 sec
dilate / background_only=False / 1 thread: 2.267 sec
dilate / background_only=False / 2 threads: 1.251 sec
dilate / background_only=False / 4 threads: 0.944 sec
dilate / background_only=False / 8 threads: 0.718 sec
scipy grey_dilation / 1 thread 13.516 sec
scipy grey_erode / 1 thread: 13.326 sec
skimage expand_labels / 1 thread: 35.243 sec



FAQs
Morphological image processing for 3D multi-label images.
We found that fastmorph demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.

Security News
CISA denies CVE funding issues amid backlash over a new CVE foundation formed by board members, raising concerns about transparency and program governance.
Product
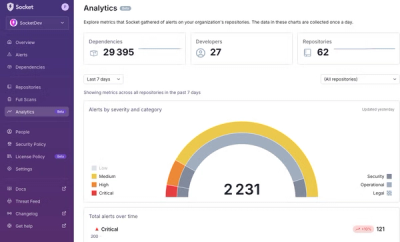
We’re excited to announce a powerful new capability in Socket: historical data and enhanced analytics.