
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025
This package contains the LangChain integrations for Upstage through their APIs.
pip install -U langchain-upstage
UPSTAGE_API_KEY)This package contains the ChatUpstage class, which is the recommended way to interface with Upstage models.
See a usage example
See a usage example
Use solar-embedding-1-large model for embeddings. Do not add suffixes such as -query or -passage to the model name.
UpstageEmbeddings will automatically add the suffixes based on the method called.
See a usage example
The use_ocr option determines whether OCR will be used for text extraction from documents. If this option is not specified, the default policy of the Upstage Document Parse API service will be applied. When use_ocr is set to True, OCR is utilized to extract text. In the case of PDF documents, this involves converting the PDF into images before performing OCR. Conversely, if use_ocr is set to False for PDF documents, the text information embedded within the PDF is used directly. However, if the input document is not a PDF, such as an image, setting use_ocr to False will result in an error.
from langchain_upstage import UpstageDocumentParseLoader
file_path = "/PATH/TO/YOUR/FILE.image"
layzer = UpstageDocumentParseLoader(file_path, split="page")
# For improved memory efficiency, consider using the lazy_load method to load documents page by page.
docs = layzer.load() # or layzer.lazy_load()
for doc in docs[:3]:
print(doc)
If you are a Windows user, please ensure that the Visual C++ Redistributable is installed before using the loader.
FAQs
An integration package connecting Upstage and LangChain
We found that langchain-upstage demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 2 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
Product
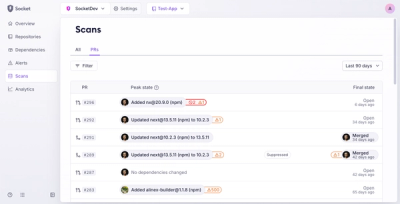
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
Research
/Security News
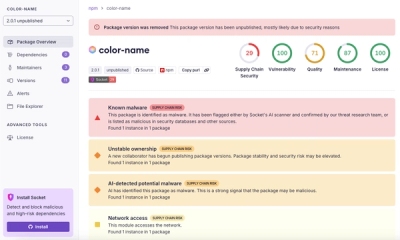
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.