llama-core


This is a solo llama connector also; being able to work independently.
install via (pip/pip3):
pip install llama-core
run it by (python/python3):
python -m llama_core
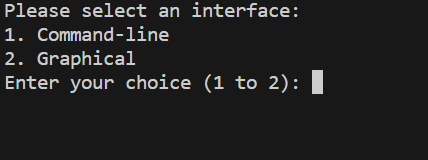
Prompt to user interface selection menu above; while chosen, GGUF file(s) in the current directory will be searched and detected (if any) as below.
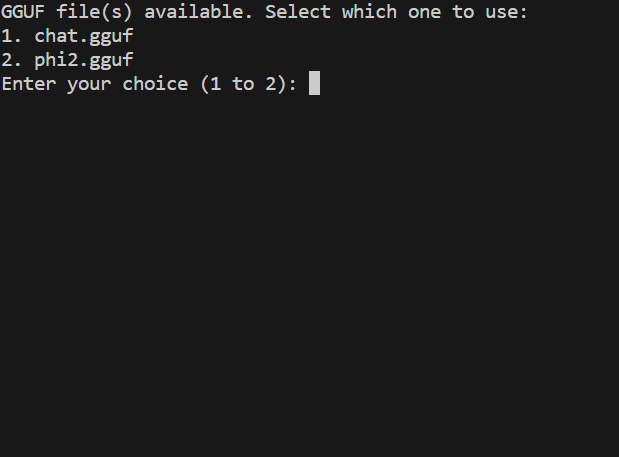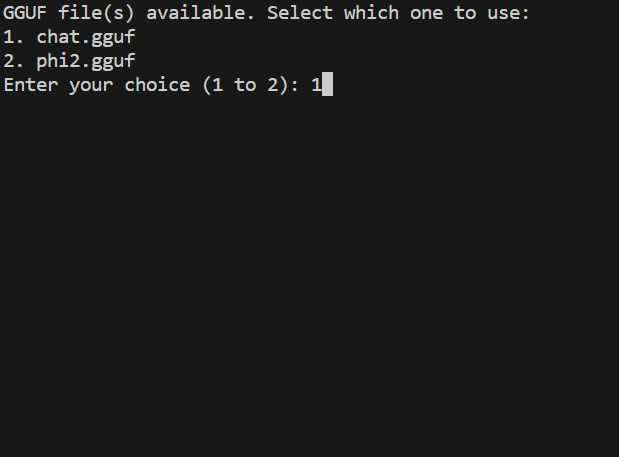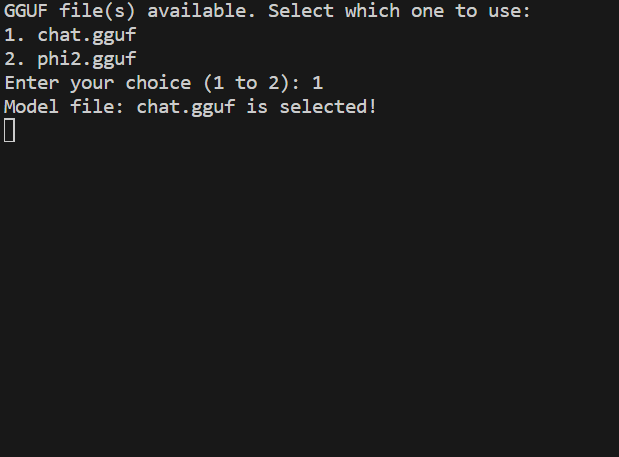

include interface selector to your code by adding:
from llama_core import menu
include gguf reader to your code by adding:
from llama_core import reader
include gguf writer to your code by adding:
from llama_core import writer
OOther functions are same as llama-cpp-python; for CUDA(GPU, Nvida) and Metal(M1/M2/M3, Apple) supported settings, please specify CMAKE_ARGS following Abetlen's repo below; if you want to install it by source file (under releases), you should opt to do it by .tar.gz file (then build your machine-customized installable package) rather than .whl (wheel; a pre-built binary package) with an appropriate cmake tag(s).
references
repo llama-cpp-python
llama.cpp
page gguf.us
build from llama_core-(version).tar.gz (examples for CPU setup below)
According to the latest note inside vs code, msys64 was recommended by Microsoft; or you could opt w64devkit or etc. as source/location of your gcc and g++ compilers.
for windows user(s):
$env:CMAKE_GENERATOR = "MinGW Makefiles"
$env:CMAKE_ARGS = "-DCMAKE_C_COMPILER=C:/msys64/mingw64/bin/gcc.exe -DCMAKE_CXX_COMPILER=C:/msys64/mingw64/bin/g++.exe"
pip install llama_core-(version).tar.gz
In mac, xcode command line tools were recommended by Apple for dealing all coding related issue(s); or you could bypass it for your own good/preference.
for mac user(s):
pip3 install llama_core-(version).tar.gz
for high (just a little bit better) performance seeker(s):
example setup for metal (M1/M2/M3 - Apple) - faster
CMAKE_ARGS="-DGGML_METAL=on" pip3 install llama_core-(version).tar.gz
example setup for cuda (GPU - Nvida) - faster x2; depends on your model (how rich you are)
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama_core-(version).tar.gz
make sure your gcc and g++ are >=11; you can check it by: gcc --version and g++ --version; other setting(s) include: cmake>=3.21, etc.; however, if you opt to install it by the pre-built wheel (.whl) file then you don't need to worry about that.






