Product
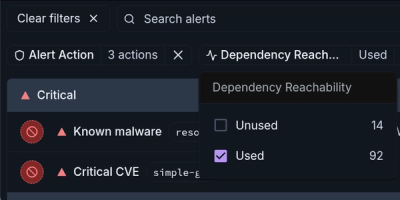
Introducing Module Reachability: Focus on the Vulnerabilities That Matter
Module Reachability filters out unreachable CVEs so you can focus on vulnerabilities that actually matter to your application.
By Trevor Norris - Apr 23, 2025
This fetches full text from Library of Congress OCR files for LOC items. It
returns the text, when found, and None otherwise.
It can take as input either a result item from a JSON API response or the URL of an item:
from locr import Fetcher
# From item or resource URL
Fetcher.full_text_from_url('https://www.loc.gov/resource/mss85943.001811/')
# From search result
# See https://libraryofcongress.github.io/data-exploration/requests.html
url = 'https://www.loc.gov/search/?fo=json&fa=subject:cats'
response = requests.get(url)
Fetcher(response['results'][0]).full_text()
Note that the above example is not guaranteed to work. In particular, not all objects have online text available.
Fetcher may raise the following exceptions:
ObjectNotOnline: when the object does not have any online formats.AmbiguousText: when multiple fulltext options are found.UnknownFormat: when locr is not sure how to handle the fulltext link's filetype.If you encounter these exceptions, kindly file an issue or open a PR about the newly discovered edge case. Thanks.
The Library of Congress has put OCRed full text online for many of its items. However:
While full text is easy to retrieve via the web site for a single item, perhaps you, like me, would like to fetch it programmatically.
This package has a humiliating lack of tests, and I have done nothing to verify appropriate versions for dependencies. It really can use your help. PRs welcome.
FAQs
Tools for fetching OCRed text of Library of Congress items.
We found that locr demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Module Reachability filters out unreachable CVEs so you can focus on vulnerabilities that actually matter to your application.

Company News
Socket is bringing best-in-class reachability analysis into the platform — cutting false positives, accelerating triage, and cementing our place as the leader in software supply chain security.
Product
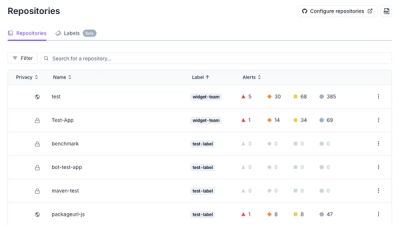
Socket is introducing a new way to organize repositories and apply repository-specific security policies.