| Albert Word Embeddings with NLU | albert, sentiment pos albert emotion |  | Albert-Paper, Albert on Github, Albert on TensorFlow, T-SNE, T-SNE-Albert, Albert_Embedding |
| Bert Word Embeddings with NLU | bert, pos sentiment emotion bert | | Bert-Paper, Bert Github, T-SNE, T-SNE-Bert, Bert_Embedding |
| BIOBERT Word Embeddings with NLU | biobert , sentiment pos biobert emotion | | BioBert-Paper, Bert Github , BERT: Deep Bidirectional Transformers, Bert Github, T-SNE, T-SNE-Biobert, Biobert_Embedding |
| COVIDBERT Word Embeddings with NLU | covidbert, sentiment covidbert pos | | CovidBert-Paper, Bert Github, T-SNE, T-SNE-CovidBert, Covidbert_Embedding |
| ELECTRA Word Embeddings with NLU | electra, sentiment pos en.embed.electra emotion | | Electra-Paper, T-SNE, T-SNE-Electra, Electra_Embedding |
| ELMO Word Embeddings with NLU | elmo, sentiment pos elmo emotion | | ELMO-Paper, Elmo-TensorFlow, T-SNE, T-SNE-Elmo, Elmo-Embedding |
| GLOVE Word Embeddings with NLU | glove, sentiment pos glove emotion | | Glove-Paper, T-SNE, T-SNE-Glove , Glove_Embedding |
| XLNET Word Embeddings with NLU | xlnet, sentiment pos xlnet emotion | | XLNet-Paper, Bert Github, T-SNE, T-SNE-XLNet, Xlnet_Embedding |
| Multiple Word-Embeddings and Part of Speech in 1 Line of code | bert electra elmo glove xlnet albert pos | | Bert-Paper, Albert-Paper, ELMO-Paper, Electra-Paper, XLNet-Paper, Glove-Paper |
| Normalzing with NLU | norm | | - |
| Detect sentences with NLU | sentence_detector.deep, sentence_detector.pragmatic, xx.sentence_detector | | Sentence Detector |
| Spellchecking with NLU | n.a. | n.a. | - |
| Stemming with NLU | en.stem, de.stem | | - |
| Stopwords removal with NLU | stopwords | | Stopwords |
| Tokenization with NLU | tokenize | | - |
| Normalization of Documents | norm_document | | - |
| Open and Closed book question answering with Google's T5 | en.t5 , answer_question | | T5-Paper, T5-Model |
| Overview of every task available with T5 | en.t5.base | | T5-Paper, T5-Model |
| Translate between more than 200 Languages in 1 line of code with Marian Models | tr.translate_to.fr, en.translate_to.fr ,fr.translate_to.he , en.translate_to.de | | Marian-Papers, Translation-Pipeline (En to Fr), Translation-Pipeline (En to Ger) |
| BERT Sentence Embeddings with NLU | embed_sentence.bert, pos sentiment embed_sentence.bert | | Bert-Paper, Bert Github, Bert-Sentence_Embedding |
| ELECTRA Sentence Embeddings with NLU | embed_sentence.electra, pos sentiment embed_sentence.electra | | Electra Paper, Sentence-Electra-Embedding |
| USE Sentence Embeddings with NLU | use, pos sentiment use emotion | | Universal Sentence Encoder, USE-TensorFlow, Sentence-USE-Embedding |
| Sentence similarity with NLU using BERT embeddings | embed_sentence.bert, use en.embed_sentence.electra embed_sentence.bert | | Bert-Paper, Bert Github, Bert-Sentence_Embedding |
| Part of Speech tagging with NLU | pos | | Part of Speech |
| NER Aspect Airline ATIS | en.ner.aspect.airline | | NER Airline Model, Atis intent Dataset |
| NLU-NER_CONLL_2003_5class_example | ner | | NER-Piple |
| Named-entity recognition with Deep Learning ONTO NOTES | ner.onto | | NER_Onto |
| Aspect based NER-Sentiment-Restaurants | en.ner.aspect_sentiment | | - |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Chinese | zh.segment_words, zh.pos, zh.ner, zh.translate_to.en | | Translation-Pipeline (Zh to En) |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Japanese | ja.segment_words, ja.pos, ja.ner, ja.translate_to.en | | Translation-Pipeline (Ja to En) |
| Detect Named Entities (NER), Part of Speech Tags (POS) and Tokenize in Korean | ko.segment_words, ko.pos, ko.ner.kmou.glove_840B_300d, ko.translate_to.en | | - |
| Date Matching | match.datetime | | - |
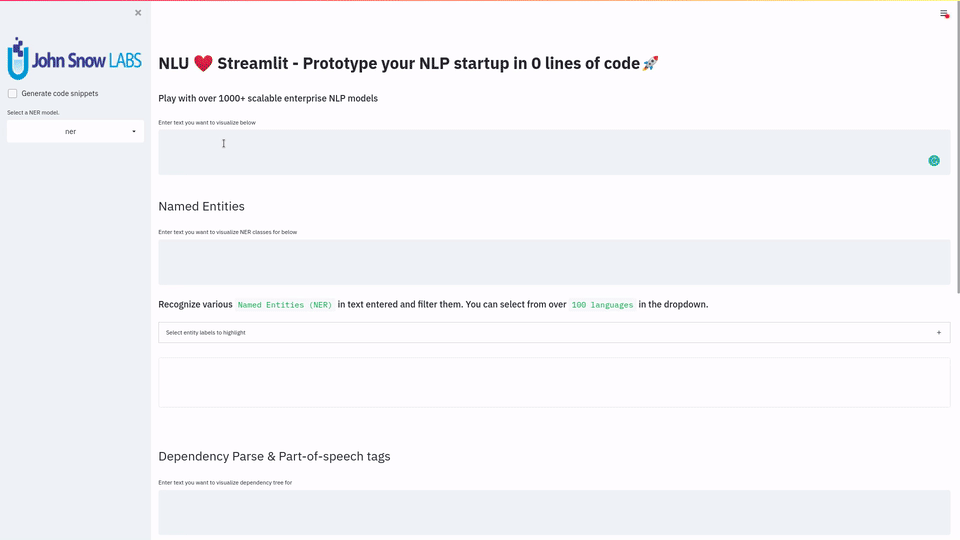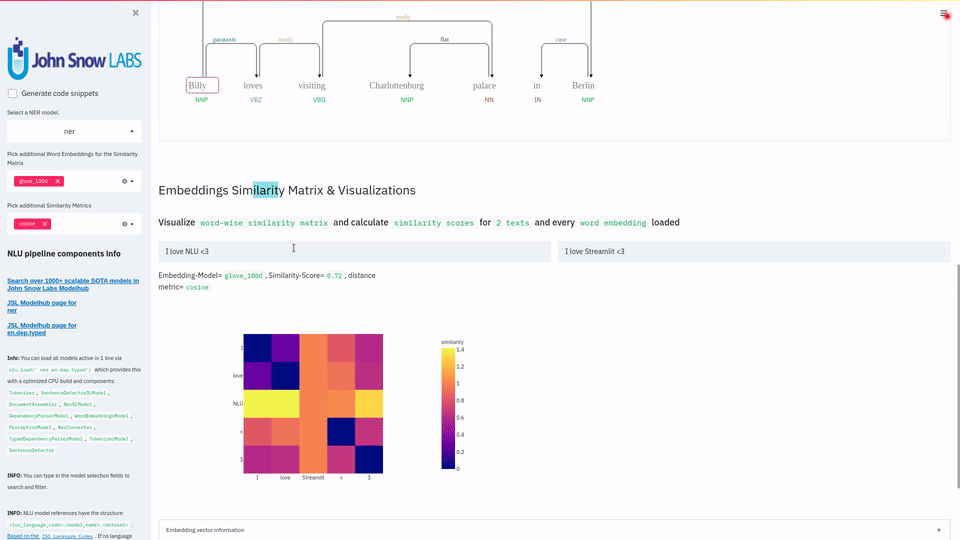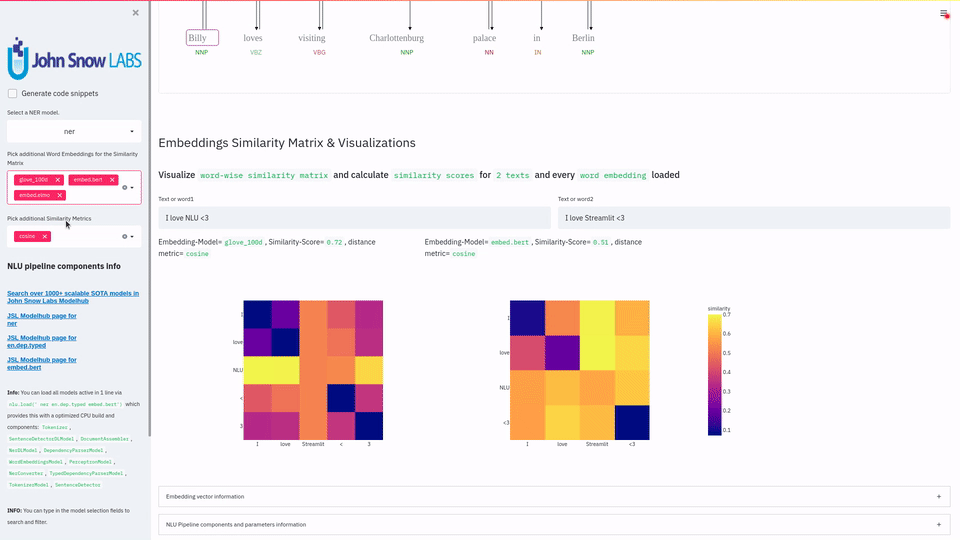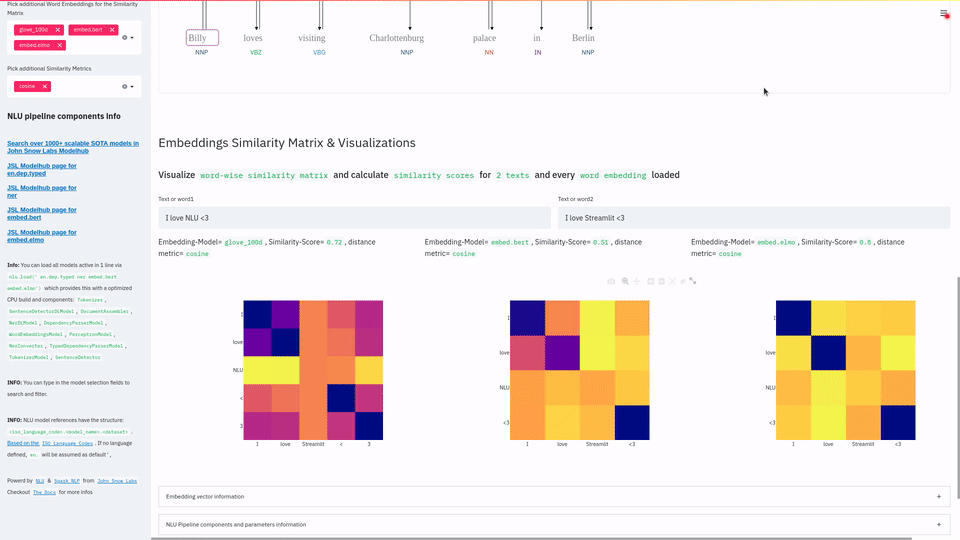
| Typed Dependency Parsing with NLU | dep | | Dependency Parsing |
| Untyped Dependency Parsing with NLU | dep.untyped | | - |
| E2E Classification with NLU | e2e | | e2e-Model |
| Language Classification with NLU | lang | | - |
| Cyberbullying Classification with NLU | classify.cyberbullying | | Cyberbullying-Classifier |
| Sentiment Classification with NLU for Twitter | emotion | | Emotion detection |
| Fake News Classification with NLU | en.classify.fakenews | | Fakenews-Classifier |
| Intent Classification with NLU | en.classify.intent.airline | | Airline-Intention classifier, Atis-Dataset |
| Question classification based on the TREC dataset | en.classify.questions | | Question-Classifier |
| Sarcasm Classification with NLU | en.classify.sarcasm | | Sarcasm-Classifier |
| Sentiment Classification with NLU for Twitter | en.sentiment.twitter | | Sentiment_Twitter-Classifier |
| Sentiment Classification with NLU for Movies | en.sentiment.imdb | | Sentiment_imdb-Classifier |
| Spam Classification with NLU | en.classify.spam | | Spam-Classifier |
| Toxic text classification with NLU | en.classify.toxic | | Toxic-Classifier |
| Unsupervised keyword extraction with NLU using the YAKE algorithm | yake | | - |
| Grammatical Chunk Matching with NLU | match.chunks | | - |
| Getting n-Grams with NLU | ngram | | - |
| Assertion | en.med_ner.clinical en.assert, en.med_ner.clinical.biobert en.assert.biobert, ... | | Healthcare-NER, NER_Clinical-Classifier, Toxic-Classifier |
| De-Identification Model overview | med_ner.jsl.wip.clinical en.de_identify, med_ner.jsl.wip.clinical en.de_identify.clinical, ... | | NER-Clinical |
| Drug Normalization | norm_drugs | | - |
| Entity Resolution | med_ner.jsl.wip.clinical en.resolve_chunk.cpt_clinical, med_ner.jsl.wip.clinical en.resolve.icd10cm, ... | | NER-Clinical, Entity-Resolver clinical |
| Medical Named Entity Recognition | en.med_ner.ade.clinical, en.med_ner.ade.clinical_bert, en.med_ner.anatomy,en.med_ner.anatomy.biobert, ... | | - |
| Relation Extraction | en.med_ner.jsl.wip.clinical.greedy en.relation, en.med_ner.jsl.wip.clinical.greedy en.relation.bodypart.problem, ... | | - |
| Visualization of NLP-Models with Spark-NLP and NLU | ner, dep.typed, med_ner.jsl.wip.clinical resolve_chunk.rxnorm.in, med_ner.jsl.wip.clinical resolve.icd10cm | | NER-Piple, Dependency Parsing, NER-Clinical, Entity-Resolver (Chunks) clinical |
| NLU Covid-19 Emotion Showcase | emotion | ![Open In GitHub]() | Emotion detection |
| NLU Covid-19 Sentiment Showcase | sentiment | ![Open In GitHub]() | Sentiment classification |
| NLU Airline Emotion Demo | emotion | ![Open In GitHub]() | Emotion detection |
| NLU Airline Sentiment Demo | sentiment | ![Open In GitHub]() | Sentiment classification |
| Bengali NER Hindi Embeddings for 30 Models | bn.ner, bn.lemma, ja.lemma, am.lemma, bh.lemma, en.ner.onto.bert.small_l2_128,.. | | Bengali-NER, Bengali-Lemmatizer, Japanese-Lemmatizer, Amharic-Lemmatizer |
| Entity Resolution | med_ner.jsl.wip.clinical en.resolve.umls, med_ner.jsl.wip.clinical en.resolve.loinc, med_ner.jsl.wip.clinical en.resolve.loinc.biobert | | - |
| NLU 20 Minutes Crashcourse - the fast Data Science route | spell, sentiment, pos, ner, yake, en.t5, emotion, answer_question, en.t5.base ... | | T5-Model, Part of Speech, NER-Piple, Emotion detection , Spellchecker, Sentiment classification |
| Chapter 0: Intro: 1-liners | sentiment, pos, ner, bert, elmo, embed_sentence.bert | | Part of Speech, NER-Piple, Sentiment classification, Elmo-Embedding, Bert-Sentence_Embedding |
| Chapter 1: NLU base-features with some classifiers on testdata | emotion, yake, stem | | Emotion detection |
| Chapter 2: Translation between 300+ languages with Marian | tr.translate_to.en, en.translate_to.fr, en.translate_to.he | | Translation-Pipeline (En to Fr), Translation (En to He) |
| Chapter 3: Answer questions and summarize Texts with T5 | answer_question, en.t5, en.t5.base | | T5-Model |
| Chapter 4: Overview of T5-Tasks | en.t5.base | | T5-Model |
| Graph NLU 20 Minutes Crashcourse - State of the Art Text Mining for Graphs | spell, sentiment, pos, ner, yake, emotion, med_ner.jsl.wip.clinical, ... | | Part of Speech, NER-Piple, Emotion detection, Spellchecker, Sentiment classification |
| Healthcare with NLU | med_ner.human_phenotype.gene_biobert, med_ner.ade_biobert, med_ner.anatomy, med_ner.bacterial_species,... | | - |
| Part 0: Intro: 1-liners | spell, sentiment, pos, ner, bert, elmo, embed_sentence.bert | | Bert-Paper, Bert Github, T-SNE, T-SNE-Bert , Part of Speech, NER-Piple, Spellchecker, Sentiment classification, Elmo-Embedding , Bert-Sentence_Embedding |
| Part 1: NLU base-features with some classifiers on Testdata | yake, stem, ner, emotion | | NER-Piple, Emotion detection |
| Part 2: Translate between 200+ Languages in 1 line of code with Marian-Models | en.translate_to.de, en.translate_to.fr, en.translate_to.he | | Translation-Pipeline (En to Fr), Translation-Pipeline (En to Ger), Translation (En to He) |
| Part 3: More Multilingual NLP-translations for Asian Languages with Marian | en.translate_to.hi, en.translate_to.ru, en.translate_to.zh | | Translation (En to Hi), Translation (En to Ru), Translation (En to Zh) |
| Part 4: Unsupervise Chinese Keyword Extraction, NER and Translation from chinese news | zh.translate_to.en, zh.segment_words, yake, zh.lemma, zh.ner | | Translation-Pipeline (Zh to En), Zh-Lemmatizer |
| Part 5: Multilingual sentiment classifier training for 100+ languages | train.sentiment, xx.embed_sentence.labse train.sentiment | n.a. | Sentence_Embedding.Labse |
| Part 6: Question-answering and Text-summarization with T5-Modell | answer_question, en.t5, en.t5.base | | T5-Paper |
| Part 7: Overview of all tasks available with T5 | en.t5.base | | T5-Paper |
| Part 8: Overview of some of the Multilingual modes with State Of the Art accuracy (1-liner) | bn.lemma, ja.lemma, am.lemma, bh.lemma, zh.segment_words, ... | | Bengali-Lemmatizer, Japanese-Lemmatizer , Amharic-Lemmatizer |
| Overview of some Multilingual modes avaiable with State Of the Art accuracy (1-liner) | bn.ner.cc_300d, ja.ner, zh.ner, th.ner.lst20.glove_840B_300D, ar.ner | | Bengali-NER |
| NLU 20 Minutes Crashcourse - the fast Data Science route | - | | - |