{kind=link}
{kind=link}

Product
Introducing Reachability for PHP
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.
By Benjamin Barslev - Apr 24, 2026
pdfkit
Advanced tools
Wkhtmltopdf python wrapper to convert html to pdf using the webkit rendering engine and qt
.. image:: https://github.com/JazzCore/python-pdfkit/actions/workflows/main.yaml/badge.svg?branch=master :target: https://github.com/JazzCore/python-pdfkit/actions/workflows/main.yaml
.. image:: https://badge.fury.io/py/pdfkit.svg :target: http://badge.fury.io/py/pdfkit
Python 2 and 3 wrapper for wkhtmltopdf utility to convert HTML to PDF using Webkit.
This is adapted version of ruby PDFKit <https://github.com/pdfkit/pdfkit>_ library, so big thanks to them!
Install python-pdfkit::
$ pip install pdfkit (or pip3 for python3)
Install wkhtmltopdf:
Debian/Ubuntu::
$ sudo apt-get install wkhtmltopdf
macOS::
$ brew install homebrew/cask/wkhtmltopdf
Warning! Version in debian/ubuntu repos have reduced functionality (because it compiled without the wkhtmltopdf QT patches), such as adding outlines, headers, footers, TOC etc. To use this options you should install static binary from wkhtmltopdf <http://wkhtmltopdf.org/>_ site or you can use this script <https://github.com/JazzCore/python-pdfkit/blob/master/travis/before-script.sh>_.
homepage <http://wkhtmltopdf.org/>_ for binary installersFor simple tasks::
import pdfkit
pdfkit.from_url('http://google.com', 'out.pdf')
pdfkit.from_file('test.html', 'out.pdf')
pdfkit.from_string('Hello!', 'out.pdf')
You can pass a list with multiple URLs or files::
pdfkit.from_url(['google.com', 'yandex.ru', 'engadget.com'], 'out.pdf')
pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
Also you can pass an opened file::
with open('file.html') as f:
pdfkit.from_file(f, 'out.pdf')
If you wish to further process generated PDF, you can read it to a variable::
# Without output_path, PDF is returned for assigning to a variable
pdf = pdfkit.from_url('http://google.com')
You can specify all wkhtmltopdf options <http://wkhtmltopdf.org/usage/wkhtmltopdf.txt>_. You can drop '--' in option name. If option without value, use None, False or '' for dict value:. For repeatable options (incl. allow, cookie, custom-header, post, postfile, run-script, replace) you may use a list or a tuple. With option that need multiple values (e.g. --custom-header Authorization secret) we may use a 2-tuple (see example below).
::
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-empty-value', '""')
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'no-outline': None
}
pdfkit.from_url('http://google.com', 'out.pdf', options=options)
By default, PDFKit will run wkhtmltopdf with quiet option turned on, since in most cases output is not needed and can cause excessive memory usage and corrupted results. If need to get wkhtmltopdf output you should pass verbose=True to API calls::
pdfkit.from_url('google.com', 'out.pdf', verbose=True)
Due to wkhtmltopdf command syntax, TOC and Cover options must be specified separately. If you need cover before TOC, use cover_first option::
toc = {
'xsl-style-sheet': 'toc.xsl'
}
cover = 'cover.html'
pdfkit.from_file('file.html', options=options, toc=toc, cover=cover)
pdfkit.from_file('file.html', options=options, toc=toc, cover=cover, cover_first=True)
You can specify external CSS files when converting files or strings using css option.
Warning This is a workaround for this bug <http://code.google.com/p/wkhtmltopdf/issues/detail?id=144>_ in wkhtmltopdf. You should try --user-style-sheet option first.
::
# Single CSS file
css = 'example.css'
pdfkit.from_file('file.html', options=options, css=css)
# Multiple CSS files
css = ['example.css', 'example2.css']
pdfkit.from_file('file.html', options=options, css=css)
You can also pass any options through meta tags in your HTML::
body = """
<html>
<head>
<meta name="pdfkit-page-size" content="Legal"/>
<meta name="pdfkit-orientation" content="Landscape"/>
</head>
Hello World!
</html>
"""
pdfkit.from_string(body, 'out.pdf') #with --page-size=Legal and --orientation=Landscape
Each API call takes an optional configuration paramater. This should be an instance of pdfkit.configuration() API call. It takes the configuration options as initial paramaters. The available options are:
wkhtmltopdf - the location of the wkhtmltopdf binary. By default pdfkit will attempt to locate this using which (on UNIX type systems) or where (on Windows).meta_tag_prefix - the prefix for pdfkit specific meta tags - by default this is pdfkit-Example - for when wkhtmltopdf is not on $PATH::
config = pdfkit.configuration(wkhtmltopdf='/opt/bin/wkhtmltopdf')
pdfkit.from_string(html_string, output_file, configuration=config)
Also you can use configuration() call to check if wkhtmltopdf is present in $PATH::
try:
config = pdfkit.configuration()
pdfkit.from_string(html_string, output_file)
except OSError:
#not present in PATH
Debugging issues with PDF generation ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
If you struggling to generate correct PDF firstly you should check wkhtmltopdf output for some clues, you can get it by passing verbose=True to API calls::
pdfkit.from_url('http://google.com', 'out.pdf', verbose=True)
If you are getting strange results in PDF or some option looks like its ignored you should try to run wkhtmltopdf directly to see if it produces the same result. You can get CLI command by creating pdfkit.PDFKit class directly and then calling its command() method::
import pdfkit
r = pdfkit.PDFKit('html', 'string', verbose=True)
print(' '.join(r.command()))
# try running wkhtmltopdf to create PDF
output = r.to_pdf()
Common errors: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
IOError: 'No wkhtmltopdf executable found':
Make sure that you have wkhtmltopdf in your $PATH or set via custom configuration (see preceding section). where wkhtmltopdf in Windows or which wkhtmltopdf on Linux should return actual path to binary.
IOError: 'Command Failed'
This error means that PDFKit was unable to process an input. You can try to directly run a command from error message and see what error caused failure (on some wkhtmltopdf versions this can be cause by segmentation faults)
1.0.0
0.6.1
0.6.0
0.5.0
0.4.1
0.4.0
0.3.0
0.2.4
0.2.3
FAQs
Wkhtmltopdf python wrapper to convert html to pdf using the webkit rendering engine and qt
We found that pdfkit demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.

Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
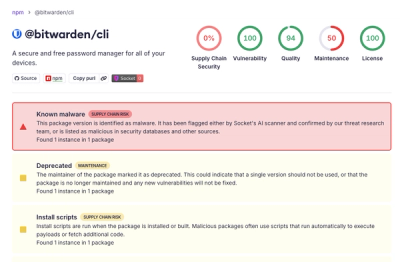
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.