
Security News
Deno 2.6 + Socket: Supply Chain Defense In Your CLI
Deno 2.6 introduces deno audit with a new --socket flag that plugs directly into Socket to bring supply chain security checks into the Deno CLI.
By Sarah Gooding - Dec 12, 2025
pseudo-py-listener
Advanced tools
PyListener is tool for near real-time voice processing and speech to text conversion, it can be pretty fast to slightly sluggish depending on the compute and memory availability of the environment, I suggest using it in situations where a delay of ~1 second is reasonable, e.g. AI assistants, voice command processing etc.
Use the package manager pip to install foobar.
pip install py-listener
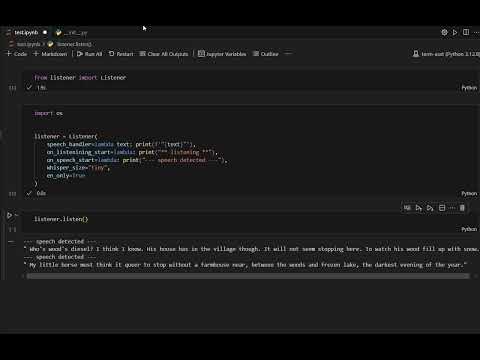
from listener import Listener
# prints what the speaker is saying, look at all
# parameters of the constructor to find out more features
try:
listener = Listener(speech_handler=print)
except:
listener.close()
raise
# start listening
listener.listen(block=True)
# stops listening
# listener.close()
# starts listening again
# listener.listen()
There is only one class in the package, the Listener.
It starts collecting audio data after instantation into n second chunks, n is a number passed as an argument, it checks if the audio chunk contains any human voice in it and if there is human voice, it collects that chunk for later processing (conversion to text or any other user-defined processing) and discards the chunk otherwise.
speech_handler: a function that is called with the text segments extracted from the human voice in the recorded audio as the only argument, speech_handler(speech: List[str]).
on_listening_start: a parameterless function that is called right after the Listener object starts collecting audio.
time_window: an integer that specifies the chunk size of the collected audio in seconds, 2 is the default.
no_channels: the number of audio channels to be used for recording, 1 is the default.
has_voice: a function that is called on the recorded audio chunks to determine if they have human voice in them, it gets the audio chunk in a numpy.ndarray object as the only argument, Silero is used by default to do this, has_voice(chunk: numpy.ndarrray).
voice_handler: a function that is used to process an utterance, a continuous segment of speech, it gets a list of audio chunks as the only argument, voice_handler(List[numpy.ndarray]).
min_speech_ms: the minimum number of miliseconds of voice activity that counts as speech, default is 0, that means all human voice activity is considered valid speech, no matter how brief.
speech_prob_thresh: the minimum probability of voice activity that is actually considered human voice, must be 0-1, default is 0.5.
whisper_size: a size for the underlying whisper model, options: tiny, tiny.en, base, base.en, small, small.en,
medium, medium.en, large, turbo.
f
whisper_kwargs: keyword arguments for the underlying faster_whisper.WhisperModel instance see faster_whisper for all available arguments.
compute_type: compute type for the whisper model, options: int8, int8_float32, int8_float16s, int8_bfloat16, int16, float16, bfloat16, float32, check OpenNMT docs for an updated list of options.
en_only: a boolean flag indicating if the the voice detection and speech-to-text models should use half precision arithmetic to save memory and reduce latency, the default is True if CUDA is available, it has no effect on CPUs at the time of this writing so it's set to False by default on CPU environments.
device: this the device where the speech detection and speech to text conversion models run, the default is cuda if available, else cpu.
listen: starts recording audio and
voice_handler function is passed, calls the function with the accumulated human voice, voice_handler(list[numpy.ndarray]).time_window second chunks until a time_window second long silence is detected, at which point it converts the accumulated voice to text, and calls the given speech_handler function and passes this transcription to it as the only argument, the transcription is a list of text segments, speech_handler(List[str]).listen method inside a main guard, i.e. if __name__ == "__main__" on CPU-only systems.close: stops recording audio and frees the resource held by the listener.
close method when the listener is no longer required, because on CPU-only systems, the audio is sent to the model running in the child process in shared memory objects and if the close method is not called, thos
objects may not get cleared and result in memory leaks, it also terminates the child process.core.py -> choose_whisper_model() method, allow larger models as compute_type gets smaller, the logic is too rigid at the moment.Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
FAQs
Real time speech to text
We found that pseudo-py-listener demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
Deno 2.6 introduces deno audit with a new --socket flag that plugs directly into Socket to bring supply chain security checks into the Deno CLI.

Security News
New DoS and source code exposure bugs in React Server Components and Next.js: what’s affected and how to update safely.

Security News
Socket CEO Feross Aboukhadijeh joins Software Engineering Daily to discuss modern software supply chain attacks and rising AI-driven security risks.