PyGPT - Desktop AI Assistant

Release: 2.5.10 | build: 2025.03.06 | Python: >=3.10, <3.13
Official website: https://pygpt.net | Documentation: https://pygpt.readthedocs.io
Discord: https://pygpt.net/discord | Snap: https://snapcraft.io/pygpt | PyPi: https://pypi.org/project/pygpt-net
Compiled version for Linux (zip) and Windows 10/11 (msi) 64-bit: https://pygpt.net/#download
❤️ Donate: https://www.buymeacoffee.com/szczyglis | https://github.com/sponsors/szczyglis-dev
Overview
PyGPT is all-in-one Desktop AI Assistant that provides direct interaction with OpenAI language models, including o1, gpt-4o, gpt-4, gpt-4 Vision, and gpt-3.5, through the OpenAI API. By utilizing LangChain and LlamaIndex, the application also supports alternative LLMs, like those available on HuggingFace, locally available models (like Llama 3,Mistral, DeepSeek V3/R1 or Bielik), Google Gemini and Anthropic Claude.
This assistant offers multiple modes of operation such as chat, assistants, completions, and image-related tasks using DALL-E 3 for generation and gpt-4 Vision for image analysis. PyGPT has filesystem capabilities for file I/O, can generate and run Python code, execute system commands, execute custom commands and manage file transfers. It also allows models to perform web searches with the Google and Microsoft Bing.
For audio interactions, PyGPT includes speech synthesis using the Microsoft Azure, Google, Eleven Labs and OpenAI Text-To-Speech services. Additionally, it features speech recognition capabilities provided by OpenAI Whisper, Google and Bing enabling the application to understand spoken commands and transcribe audio inputs into text. It features context memory with save and load functionality, enabling users to resume interactions from predefined points in the conversation. Prompt creation and management are streamlined through an intuitive preset system.
PyGPT's functionality extends through plugin support, allowing for custom enhancements. Its multi-modal capabilities make it an adaptable tool for a range of AI-assisted operations, such as text-based interactions, system automation, daily assisting, vision applications, natural language processing, code generation and image creation.
Multiple operation modes are included, such as chat, text completion, assistant, vision, LangChain, Chat with Files (via LlamaIndex), commands execution, external API calls and image generation, making PyGPT a multi-tool for many AI-driven tasks.
Video (mp4, version 2.4.35, build 2024-11-28):
https://github.com/user-attachments/assets/5751a003-950f-40e7-a655-d098bbf27b0c
Screenshot (version 2.4.35, build 2024-11-28):

You can download compiled 64-bit versions for Windows and Linux here: https://pygpt.net/#download
Features
- Desktop AI Assistant for
Linux, Windows and Mac, written in Python.
- Works similarly to
ChatGPT, but locally (on a desktop computer).
- 12 modes of operation: Chat, Vision, Completion, Assistant, Image generation, LangChain, Chat with Files, Chat with Audio, Research (Perplexity), Experts, Autonomous Mode and Agents.
- Supports multiple models:
o1, GPT-4o, GPT-4, GPT-3.5, and any model accessible through LangChain, LlamaIndex and Ollama such as Llama 3, Mistral, Google Gemini, Anthropic Claude, DeepSeek V3/R1, Bielik, etc.
- Chat with your own Files: integrated
LlamaIndex support: chat with data such as: txt, pdf, csv, html, md, docx, json, epub, xlsx, xml, webpages, Google, GitHub, video/audio, images and other data types, or use conversation history as additional context provided to the model.
- Built-in vector databases support and automated files and data embedding.
- Included support features for individuals with disabilities: customizable keyboard shortcuts, voice control, and translation of on-screen actions into audio via speech synthesis.
- Handles and stores the full context of conversations (short and long-term memory).
- Internet access via
Google and Microsoft Bing.
- Speech synthesis via
Microsoft Azure, Google, Eleven Labs and OpenAI Text-To-Speech services.
- Speech recognition via
OpenAI Whisper, Google and Microsoft Speech Recognition.
- Real-time video camera capture in Vision mode.
- Image analysis via
GPT-4 Vision and GPT-4o.
- Integrated
LangChain support (you can connect to any LLM, e.g., on HuggingFace).
- Integrated calendar, day notes and search in contexts by selected date.
- Tools and commands execution (via plugins: access to the local filesystem, Python Code Interpreter, system commands execution, and more).
- Custom commands creation and execution.
- Crontab / Task scheduler included.
- Manages files and attachments with options to upload, download, and organize.
- Context history with the capability to revert to previous contexts (long-term memory).
- Allows you to easily manage prompts with handy editable presets.
- Provides an intuitive operation and interface.
- Includes a notepad.
- Includes simple painter / drawing tool.
- Supports multiple languages.
- Requires no previous knowledge of using AI models.
- Simplifies image generation using
DALL-E.
- Fully configurable.
- Themes support.
- Real-time code syntax highlighting.
- Plugins support.
- Built-in token usage calculation.
- Possesses the potential to support future OpenAI models.
- Open source; source code is available on
GitHub.
- Utilizes the user's own API key.
- and many more.
The application is free, open-source, and runs on PCs with Linux, Windows 10, Windows 11 and Mac.
Full Python source code is available on GitHub.
PyGPT uses the user's API key - to use the GPT models,
you must have a registered OpenAI account and your own API key. Local models do not require any API keys.
You can also use built-it LangChain support to connect to other Large Language Models (LLMs),
such as those on HuggingFace. Additional API keys may be required.
Installation
Binaries (Linux, Windows 10 and 11)
You can download compiled binary versions for Linux and Windows (10/11).
PyGPT binaries require a PC with Windows 10, 11, or Linux. Simply download the installer or the archive with the appropriate version from the download page at https://pygpt.net, extract it, or install it, and then run the application. A binary version for Mac is not available, so you must run PyGPT from PyPi or from the source code on Mac. Currently, only 64-bit binaries are available.
Linux version requires GLIBC >= 2.35.
Snap Store
You can install PyGPT directly from Snap Store:
sudo snap install pygpt
To manage future updates just use:
sudo snap refresh pygpt

Using camera: to use camera in Snap version you must connect the camera with:
sudo snap connect pygpt:camera
Using microphone: to use microphone in Snap version you must connect the microphone with:
sudo snap connect pygpt:audio-record :audio-record
sudo snap connect pygpt:alsa
Using audio output: to use audio output in Snap version you must connect the audio with:
sudo snap connect pygpt:audio-playback
sudo snap connect pygpt:alsa
Connecting IPython in Docker in Snap version:
To use IPython in the Snap version, you must connect PyGPT to the Docker daemon:
sudo snap connect pygpt:docker-executables docker:docker-executables
sudo snap connect pygpt:docker docker:docker-daemon
PyPi (pip)
The application can also be installed from PyPi using pip install:
- Create virtual environment:
python3 -m venv venv
source venv/bin/activate
pip install pygpt-net
- Once installed run the command to start the application:
pygpt
Running from GitHub source code
An alternative method is to download the source code from GitHub and execute the application using the Python interpreter (>=3.10, <3.13).
Install with pip
- Clone git repository or download .zip file:
git clone https://github.com/szczyglis-dev/py-gpt.git
cd py-gpt
- Create a new virtual environment:
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python3 run.py
Install with Poetry
- Clone git repository or download .zip file:
git clone https://github.com/szczyglis-dev/py-gpt.git
cd py-gpt
- Install Poetry (if not installed):
pip install poetry
- Create a new virtual environment that uses Python 3.10:
poetry env use python3.10
poetry shell
poetry install
poetry run python3 run.py
Tip: you can use PyInstaller to create a compiled version of
the application for your system (required version >= 6.0.0).
Troubleshooting
If you have a problems with xcb plugin with newer versions of PySide on Linux, e.g. like this:
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found.
This application failed to start because no Qt platform plugin could be initialized.
Reinstalling the application may fix this problem.
...then install libxcb:
sudo apt install libxcb-cursor0
If you have a problems with audio on Linux, then try to install portaudio19-dev and/or libasound2:
sudo apt install portaudio19-dev
sudo apt install libasound2
sudo apt install libasound2-data
sudo apt install libasound2-plugins
Problems with GLIBC on Linux
If you encounter error:
Error loading Python lib libpython3.10.so.1.0: dlopen: /lib/x86_64-linux-gnu/libm.so.6: version GLIBC_2.35 not found (required by libpython3.10.so.1.0)
when trying to run the compiled version for Linux, try updating GLIBC to version 2.35, or use a newer operating system that has at least version 2.35 of GLIBC.
Access to camera in Snap version:
sudo snap connect pygpt:camera
Access to microphone in Snap version:
To use microphone in Snap version you must connect the microphone with:
sudo snap connect pygpt:audio-record :audio-record
Access to microphone and audio in Windows version:
If you have a problems with audio or microphone in the non-binary PIP/Python version on Windows, check to see if FFmpeg is installed. If it's not, install it and add it to the PATH. You can find a tutorial on how to do this here: https://phoenixnap.com/kb/ffmpeg-windows. The binary version already includes FFmpeg.
Windows and VC++ Redistributable
On Windows, the proper functioning requires the installation of the VC++ Redistributable, which can be found on the Microsoft website:
https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist
The libraries from this environment are used by PySide6 - one of the base packages used by PyGPT.
The absence of the installed libraries may cause display errors or completely prevent the application from running.
It may also be necessary to add the path C:\path\to\venv\Lib\python3.x\site-packages\PySide6 to the PATH variable.
WebEngine/Chromium renderer and OpenGL problems
If you have a problems with WebEngine / Chromium renderer you can force the legacy mode by launching the app with command line arguments:
python3 run.py --legacy=1
and to force disable OpenGL hardware acceleration:
python3 run.py --disable-gpu=1
You can also manualy enable legacy mode by editing config file - open the %WORKDIR%/config.json config file in editor and set the following options:
"render.engine": "legacy",
"render.open_gl": false,
Other requirements
For operation, an internet connection is needed (for API connectivity), a registered OpenAI account,
and an active API key that must be input into the program. Local models, such as Llama3 do not require OpenAI account and any API keys.
Debugging and logging
Please go to Debugging and Logging section for instructions on how to log and diagnose issues in a more detailed manner.
Quick Start
Setting-up OpenAI API KEY
Tip: The API key is required to work with the OpenAI API. If you wish to use custom API endpoints or local API that do not require API keys, simply enter anything into the API key field to avoid a prompt about the API key being empty.
During the initial launch, you must configure your API key within the application.
To do so, navigate to the menu:
Config -> Settings -> API Keys
and then paste the API key into the OpenAI API KEY field.

The API key can be obtained by registering on the OpenAI website:
https://platform.openai.com
Your API keys will be available here:
https://platform.openai.com/account/api-keys
Note: The ability to use models within the application depends on the API user's access to a given model!
Working modes
Chat
+ Inline Vision and Image generation
This mode in PyGPT mirrors ChatGPT, allowing you to chat with models such as o1, GPT-4, GPT-4o and GPT-3.5. It works by using the ChatCompletion OpenAI API.
Tip: This mode directly uses the OpenAI API. If you want to use models other than GPT (such as Gemini, Claude, or Llama3), use Chat with Files mode.
The main part of the interface is a chat window where you see your conversations. Below it is a message box for typing. On the right side, you can set up or change the model and system prompt. You can also save these settings as presets to easily switch between models or tasks.
Above where you type your messages, the interface shows you the number of tokens your message will use up as you type it – this helps to keep track of usage. There is also a feature to attach and upload files in this area. Go to the Files and Attachments section for more information on how to use attachments.

Vision: If you want to send photos from your disk or images from your camera for analysis, and the selected model does not support Vision, you must enable the GPT-4 Vision (inline) plugin in the Plugins menu. This plugin allows you to send photos or images from your camera for analysis in any Chat mode.

With this plugin, you can capture an image with your camera or attach an image and send it for analysis to discuss the photograph:

Image generation: If you want to generate images (using DALL-E) directly in chat you must enable plugin DALL-E 3 (inline) in the Plugins menu.
Plugin allows you to generate images in Chat mode:

Chat with Audio
2024-11-26: currently in beta.
This mode works like the Chat mode but with native support for audio input and output using a multimodal model - gpt-4o-audio. In this mode, audio input and output are directed to and from the model directly, without the use of external plugins. This enables faster and better audio communication.
More info: https://platform.openai.com/docs/guides/audio/quickstart
Currently, in beta. Tool and function calls are not enabled in this mode.
Research (Perplexity)
2025-03-02: currently in beta.
Mode operates using the Perplexity API: https://perplexity.ai.
It allows for deep web searching and utilizes Sonar models, available in Perplexity AI.
It requires a Perplexity API key, which can be generated at: https://perplexity.ai.
Completion
An older mode of operation that allows working in the standard text completion mode. However, it allows for a bit more flexibility with the text by enabling you to initiate the entire discussion in any way you like.
Similar to chat mode, on the right-hand side of the interface, there are convenient presets. These allow you to fine-tune instructions and swiftly transition between varied configurations and pre-made prompt templates.
Additionally, this mode offers options for labeling the AI and the user, making it possible to simulate dialogues between specific characters - for example, you could create a conversation between Batman and the Joker, as predefined in the prompt. This feature presents a range of creative possibilities for setting up different conversational scenarios in an engaging and exploratory manner.
From version 2.0.107 the davinci models are deprecated and has been replaced with gpt-3.5-turbo-instruct model in Completion mode.
Image generation (DALL-E)
DALL-E 3
PyGPT enables quick and easy image creation with DALL-E 3.
The older model version, DALL-E 2, is also accessible. Generating images is akin to a chat conversation - a user's prompt triggers the generation, followed by downloading, saving to the computer,
and displaying the image onscreen. You can send raw prompt to DALL-E in Image generation mode or ask the model for the best prompt.

Image generation using DALL-E is available in every mode via plugin DALL-E 3 Image Generation (inline). Just ask any model, in any mode, like e.g. GPT-4 to generate an image and it will do it inline, without need to mode change.
If you want to generate images (using DALL-E) directly in chat you must enable plugin DALL-E 3 Inline in the Plugins menu.
Plugin allows you to generate images in Chat mode:
Multiple variants
You can generate up to 4 different variants (DALL-E 2) for a given prompt in one session. DALL-E 3 allows one image.
To select the desired number of variants to create, use the slider located in the right-hand corner at
the bottom of the screen. This replaces the conversation temperature slider when you switch to image generation mode.
Raw mode
There is an option for switching prompt generation mode.
If Raw Mode is enabled, DALL-E will receive the prompt exactly as you have provided it.
If Raw Mode is disabled, GPT will generate the best prompt for you based on your instructions.
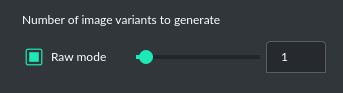
Image storage
Once you've generated an image, you can easily save it anywhere on your disk by right-clicking on it.
You also have the options to delete it or view it in full size in your web browser.
Tip: Use presets to save your prepared prompts.
This lets you quickly use them again for generating new images later on.
The app keeps a history of all your prompts, allowing you to revisit any session and reuse previous
prompts for creating new images.
Images are stored in img directory in PyGPT user data folder.
Vision (GPT-4 Vision)
This mode enables image analysis using the gpt-4o and gpt-4-vision models. Functioning much like the chat mode,
it also allows you to upload images or provide URLs to images. The vision feature can analyze both local
images and those found online.
Vision is also integrated into any chat mode via plugin GPT-4 Vision (inline). Just enable the plugin and use Vision in other work modes, such as Chat or Chat with Files.
Vision mode also includes real-time video capture from camera. To capture image from camera and append it to chat just click on video at left side. You can also enable Auto capture - image will be captured and appended to chat message every time you send message.
1) Video camera real-time image capture

2) you can also provide an image URL
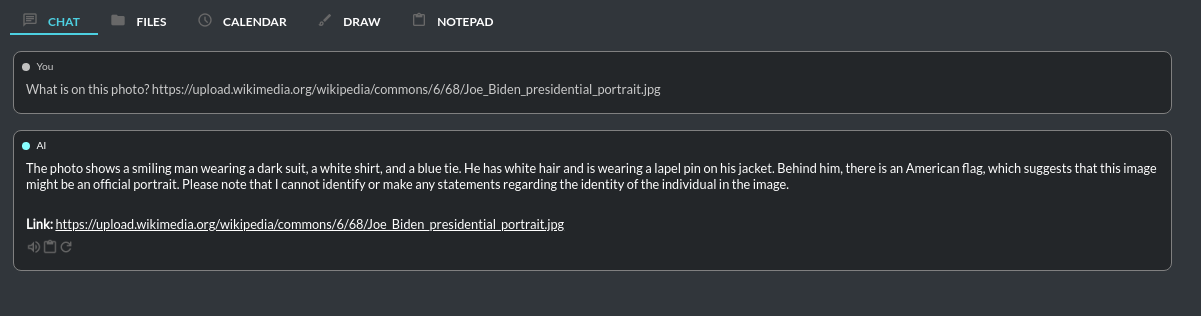
3) or you can just upload your local images or use the inline Vision in the standard chat mode:
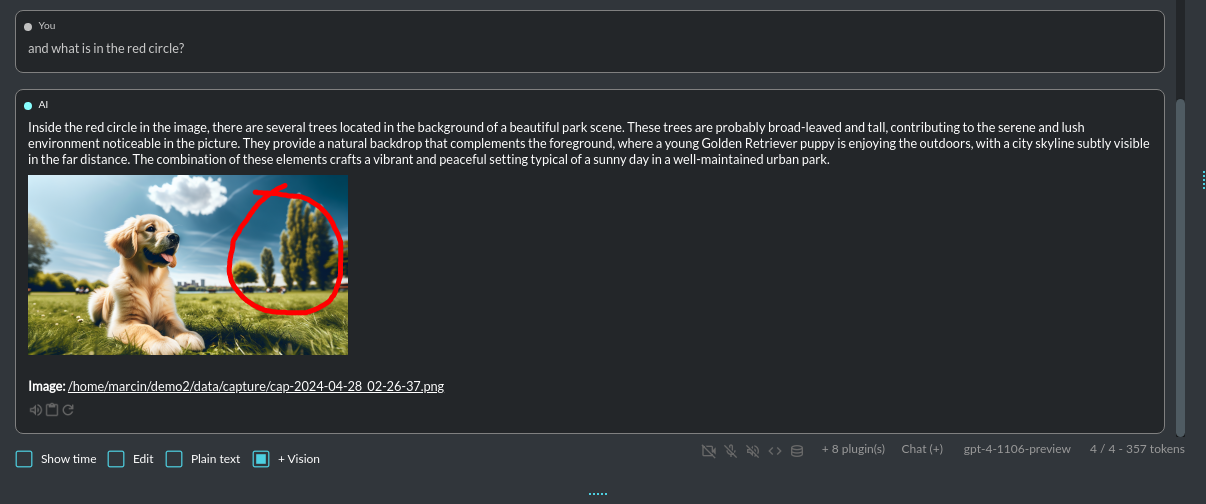
Tip: When using Vision (inline) by utilizing a plugin in standard mode, such as Chat (not Vision mode), the + Vision label will appear at the bottom of the Chat window.
Assistants
This mode uses the OpenAI's Assistants API.
This mode expands on the basic chat functionality by including additional external tools like a Code Interpreter for executing code, Retrieval Files for accessing files, and custom Functions for enhanced interaction and integration with other APIs or services. In this mode, you can easily upload and download files. PyGPT streamlines file management, enabling you to quickly upload documents and manage files created by the model.
Setting up new assistants is simple - a single click is all it takes, and they instantly sync with the OpenAI API. Importing assistants you've previously created with OpenAI into PyGPT is also a seamless process.

In Assistant mode you are allowed to storage your files in remote vector store (per Assistant) and manage them easily from app:
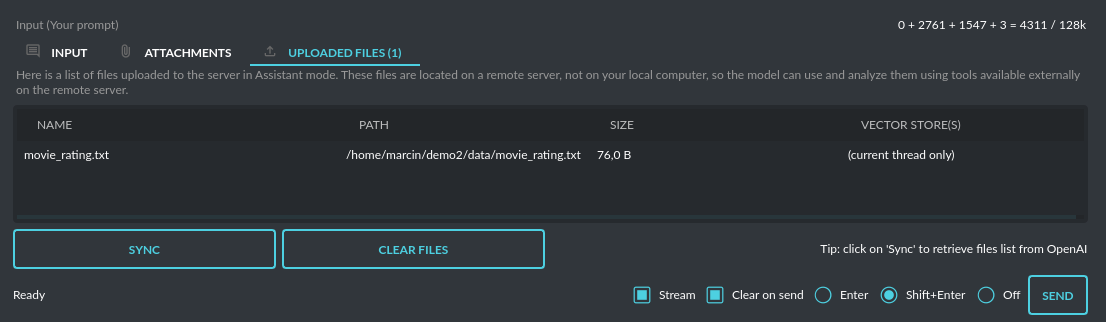
Please note that token usage calculation is unavailable in this mode. Nonetheless, file (attachment)
uploads are supported. Simply navigate to the Files tab to effortlessly manage files and attachments which
can be sent to the OpenAI API.
Vector stores (via Assistants API)
Assistant mode supports the use of external vector databases offered by the OpenAI API. This feature allows you to store your files in a database and then search them using the Assistant's API. Each assistant can be linked to one vector database—if a database is linked, all files uploaded in this mode will be stored in the linked vector database. If an assistant does not have a linked vector database, a temporary database is automatically created during the file upload, which is accessible only in the current thread. Files from temporary databases are automatically deleted after 7 days.
To enable the use of vector stores, enable the Chat with Files checkbox in the Assistant settings. This enables the File search tool in Assistants API.
To manage external vector databases, click the DB icon next to the vector database selection list in the Assistant creation and editing window (screen below). In this management window, you can create a new vector database, edit an existing one, or import a list of all existing databases from the OpenAI server:
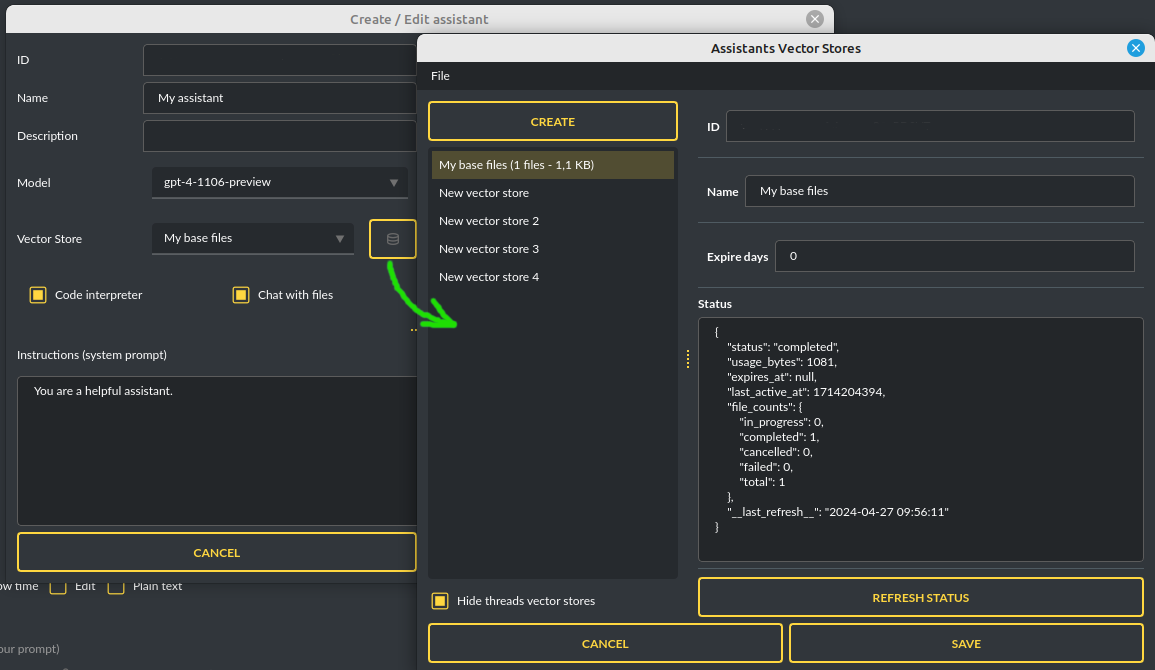
You can define, using Expire days, how long files should be automatically kept in the database before deletion (as storing files on OpenAI incurs costs). If the value is set to 0, files will not be automatically deleted.
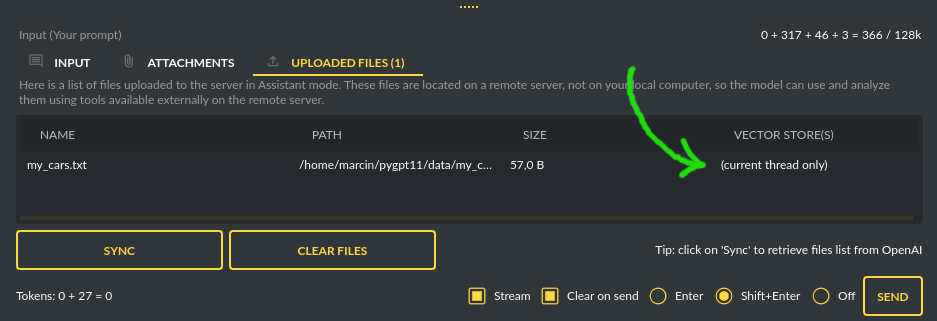
The vector database in use will be displayed in the list of uploaded files, on the field to the right—if a file is stored in a database, the name of the database will be displayed there; if not, information will be shown indicating that the file is only accessible within the thread:
LangChain
This mode enables you to work with models that are supported by LangChain. The LangChain support is integrated
into the application, allowing you to interact with any LLM by simply supplying a configuration
file for the specific model. You can add as many models as you like; just list them in the configuration
file named models.json.
Available LLMs providers supported by PyGPT, in LangChain and Chat with Files (LlamaIndex) modes:
- OpenAI
- Azure OpenAI
- Google (Gemini, etc.)
- HuggingFace
- Anthropic
- Ollama (Llama3, Mistral, etc.)
You have the ability to add custom model wrappers for models that are not available by default in PyGPT.
To integrate a new model, you can create your own wrapper and register it with the application.
Detailed instructions for this process are provided in the section titled Managing models / Adding models via LangChain.
Chat with Files (LlamaIndex)
This mode enables chat interaction with your documents and entire context history through conversation.
It seamlessly incorporates LlamaIndex into the chat interface, allowing for immediate querying of your indexed documents.
Querying single files
You can also query individual files "on the fly" using the query_file command from the Files I/O plugin. This allows you to query any file by simply asking a question about that file. A temporary index will be created in memory for the file being queried, and an answer will be returned from it. From version 2.1.9 similar command is available for querying web and external content: Directly query web content with LlamaIndex.
For example:
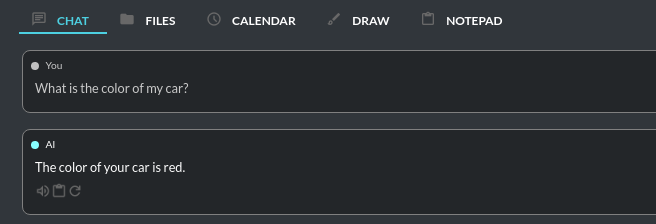
If you have a file: data/my_cars.txt with content My car is red.
You can ask for: Query the file my_cars.txt about what color my car is.
And you will receive the response: Red.
Note: this command indexes the file only for the current query and does not persist it in the database. To store queried files also in the standard index you must enable the option Auto-index readed files in plugin settings. Remember to enable + Tools checkbox to allow usage of tools and commands from plugins.
Using Chat with Files mode
In this mode, you are querying the whole index, stored in a vector store database.
To start, you need to index (embed) the files you want to use as additional context.
Embedding transforms your text data into vectors. If you're unfamiliar with embeddings and how they work, check out this article:
https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
For a visualization from OpenAI's page, see this picture:

Source: https://cdn.openai.com/new-and-improved-embedding-model/draft-20221214a/vectors-3.svg
To index your files, simply copy or upload them into the data directory and initiate indexing (embedding) by clicking the Index all button, or right-click on a file and select Index.... Additionally, you have the option to utilize data from indexed files in any Chat mode by activating the Chat with Files (LlamaIndex, inline) plugin.

After the file(s) are indexed (embedded in vector store), you can use context from them in chat mode:
Built-in file loaders:
Files:
- CSV files (csv)
- Epub files (epub)
- Excel .xlsx spreadsheets (xlsx)
- HTML files (html, htm)
- IPYNB Notebook files (ipynb)
- Image (vision) (jpg, jpeg, png, gif, bmp, tiff, webp)
- JSON files (json)
- Markdown files (md)
- PDF documents (pdf)
- Txt/raw files (txt)
- Video/audio (mp4, avi, mov, mkv, webm, mp3, mpeg, mpga, m4a, wav)
- Word .docx documents (docx)
- XML files (xml)
Web/external content:
- Bitbucket
- ChatGPT Retrieval Plugin
- GitHub Issues
- GitHub Repository
- Google Calendar
- Google Docs
- Google Drive
- Google Gmail
- Google Keep
- Google Sheets
- Microsoft OneDrive
- RSS
- SQL Database
- Sitemap (XML)
- Twitter/X posts
- Webpages (crawling any webpage content)
- YouTube (transcriptions)
You can configure data loaders in Settings / Indexes (LlamaIndex) / Data Loaders by providing list of keyword arguments for specified loaders.
You can also develop and provide your own custom loader and register it within the application.
LlamaIndex is also integrated with context database - you can use data from database (your context history) as additional context in discussion.
Options for indexing existing context history or enabling real-time indexing new ones (from database) are available in Settings / Indexes (LlamaIndex) section.
WARNING: remember that when indexing content, API calls to the embedding model are used. Each indexing consumes additional tokens. Always control the number of tokens used on the OpenAI page.
Tip: Using the Chat with Files mode, you have default access to files manually indexed from the /data directory. However, you can use additional context by attaching a file - such additional context from the attachment does not land in the main index, but only in a temporary one, available only for the given conversation.
Token limit: When you use Chat with Files in non-query mode, LlamaIndex adds extra context to the system prompt. If you use a plugins (which also adds more instructions to system prompt), you might go over the maximum number of tokens allowed. If you get a warning that says you've used too many tokens, turn off plugins you're not using or turn off the "+ Tools" option to reduce the number of tokens used by the system prompt.
Available vector stores (provided by LlamaIndex):
- ChromaVectorStore
- ElasticsearchStore
- PinecodeVectorStore
- RedisVectorStore
- SimpleVectorStore
You can configure selected vector store by providing config options like api_key, etc. in Settings -> LlamaIndex window. See the section: Configuration / Vector stores for configuration reference.
Configuring data loaders
In the Settings -> LlamaIndex -> Data loaders section you can define the additional keyword arguments to pass into data loader instance. See the section: Configuration / Data Loaders for configuration reference.
Agent (LlamaIndex)
Currently in beta version -- introduced in 2.4.10 (2024-11-14)
Mode that allows the use of agents offered by LlamaIndex.
Includes built-in agents:
- OpenAI
- ReAct
- Structured Planner (sub-tasks)
In the future, the list of built-in agents will be expanded.
You can also create your own agent by creating a new provider that inherits from pygpt_net.provider.agents.base.
Tools and Plugins
In this mode, all commands from active plugins are available (commands from plugins are automatically converted into tools for the agent on-the-fly).
RAG - using indexes
If an index is selected in the agent preset, a tool for reading data from the index is automatically added to the agent, creating a RAG automatically.
Multimodality is currently unavailable, only text is supported. Vision support will be added in the future.
Loop / Evaluate Mode
You can run the agent in autonomous mode, in a loop, and with evaluation of the current output. When you enable the Loop / Evaluate checkbox, after the final response is given, the quality of the answer will be rated on a percentage scale of 0% to 100% by another agent. If the response receives a score lower than the one expected (set using a slider at the bottom right corner of the screen, with a default value 75%), a prompt will be sent to the agent requesting improvements and enhancements to the response.
Setting the expected (required) score to 0% means that the response will be evaluated every time the agent produces a result, and it will always be prompted to self-improve its answer. This way, you can put the agent in an autonomous loop, where it will continue to operate until it succeeds.
You can set the limit of steps in such a loop by going to Settings -> Agents and experts -> LlamaIndex agents -> Max evaluation steps . The default value is 3, meaning the agent will only make three attempts to improve or correct its answer. If you set the limit to zero, there will be no limit, and the agent can operate in this mode indefinitely (watch out for tokens!).
You can change the prompt used for evaluating the response in Settings -> Prompts -> Agent: evaluation prompt in loop. Here, you can adjust it to suit your needs, for example, by defining more or less critical feedback for the responses received.
Agent (Autonomous)
This is an older version of the Agent mode, still available as legacy. However, it is recommended to use the newer mode: Agent (LlamaIndex).
WARNING: Please use this mode with caution - autonomous mode, when connected with other plugins, may produce unexpected results!
The mode activates autonomous mode, where AI begins a conversation with itself.
You can set this loop to run for any number of iterations. Throughout this sequence, the model will engage
in self-dialogue, answering his own questions and comments, in order to find the best possible solution, subjecting previously generated steps to criticism.
WARNING: Setting the number of run steps (iterations) to 0 activates an infinite loop which can generate a large number of requests and cause very high token consumption, so use this option with caution! Confirmation will be displayed every time you run the infinite loop.
This mode is similar to Auto-GPT - it can be used to create more advanced inferences and to solve problems by breaking them down into subtasks that the model will autonomously perform one after another until the goal is achieved.
You can create presets with custom instructions for multiple agents, incorporating various workflows, instructions, and goals to achieve.
All plugins are available for agents, so you can enable features such as file access, command execution, web searching, image generation, vision analysis, etc., for your agents. Connecting agents with plugins can create a fully autonomous, self-sufficient system. All currently enabled plugins are automatically available to the Agent.
When the Auto-stop option is enabled, the agent will attempt to stop once the goal has been reached.
In opposition to Auto-stop, when the Always continue... option is enabled, the agent will use the "always continue" prompt to generate additional reasoning and automatically proceed to the next step, even if it appears that the task has been completed.
Options
The agent is essentially a virtual mode that internally sequences the execution of a selected underlying mode.
You can choose which internal mode the agent should use in the settings:
Settings / Agent (autonomous) / Sub-mode to use
Available choices include: chat, completion, langchain, vision, llama_index (Chat with Files).
Default is: chat.
If you want to use the LlamaIndex mode when running the agent, you can also specify which index LlamaIndex should use with the option:
Settings / Agents and experts / Index to use

Experts (co-op, co-operation mode)
This mode is experimental.
Expert mode allows for the creation of experts (using presets) and then consulting them during a conversation. In this mode, a primary base context is created for conducting the conversation. From within this context, the model can make requests to an expert to perform a task and return the results to the main thread. When an expert is called in the background, a separate context is created for them with their own memory. This means that each expert, during the life of one main context, also has access to their own memory via their separate, isolated context.
In simple terms - you can imagine an expert as a separate, additional instance of the model running in the background, which can be called at any moment for assistance, with its own context and memory, as well as its own specialized instructions in a given subject.
Experts do not share contexts with one another, and the only point of contact between them is the main conversation thread. In this main thread, the model acts as a manager of experts, who can exchange data between them as needed.
An expert is selected based on the name in the presets; for example, naming your expert as: ID = python_expert, name = "Python programmer" will create an expert whom the model will attempt to invoke for matters related to Python programming. You can also manually request to refer to a given expert:
Call the Python expert to generate some code.
Experts can be activated or deactivated - to enable or disable use RMB context menu to select the Enable/Disable options from the presets list. Only enabled experts are available to use in the thread.
Experts can also be used in Agent (autonomous) mode - by creating a new agent using a preset. Simply move the appropriate experts to the active list to automatically make them available for use by the agent.
You can also use experts in "inline" mode - by activating the Experts (inline) plugin. This allows for the use of experts in any mode, such as normal chat.
Expert mode, like agent mode, is a "virtual" mode - you need to select a target mode of operation for it, which can be done in the settings at Settings / Agent (autonomous) / Sub-mode for experts.
You can also ask for a list of active experts at any time:
Give me a list of active experts.
Context and memory
Short and long-term memory
PyGPT features a continuous chat mode that maintains a long context of the ongoing dialogue. It preserves the entire conversation history and automatically appends it to each new message (prompt) you send to the AI. Additionally, you have the flexibility to revisit past conversations whenever you choose. The application keeps a record of your chat history, allowing you to resume discussions from the exact point you stopped.
Handling multiple contexts
On the left side of the application interface, there is a panel that displays a list of saved conversations. You can save numerous contexts and switch between them with ease. This feature allows you to revisit and continue from any point in a previous conversation. PyGPT automatically generates a summary for each context, akin to the way ChatGPT operates and gives you the option to modify these titles itself.

You can disable context support in the settings by using the following option:
Config -> Settings -> Use context
Clearing history
You can clear the entire memory (all contexts) by selecting the menu option:
File -> Clear history...
Context storage
On the application side, the context is stored in the SQLite database located in the working directory (db.sqlite).
In addition, all history is also saved to .txt files for easy reading.
Once a conversation begins, a title for the chat is generated and displayed on the list to the left. This process is similar to ChatGPT, where the subject of the conversation is summarized, and a title for the thread is created based on that summary. You can change the name of the thread at any time.
Files And Attachments
Uploading attachments
Using Your Own Files as Additional Context in Conversations
You can use your own files (for example, to analyze them) during any conversation. You can do this in two ways: by indexing (embedding) your files in a vector database, which makes them available all the time during a "Chat with Files" session, or by adding a file attachment (the attachment file will only be available during the conversation in which it was uploaded).
Attachments
PyGPT makes it simple for users to upload files and send them to the model for tasks like analysis, similar to attaching files in ChatGPT. There's a separate Attachments tab next to the text input area specifically for managing file uploads.
Tip: Attachments uploaded in group are available in all contexts in group.

You can use attachments to provide additional context to the conversation. Uploaded files will be converted into text using loaders from LlamaIndex, and then embedded into the vector store. You can upload any file format supported by the application through LlamaIndex. Supported formats include:
Text-based types:
- CSV files (csv)
- Epub files (epub)
- Excel .xlsx spreadsheets (xlsx)
- HTML files (html, htm)
- IPYNB Notebook files (ipynb)
- JSON files (json)
- Markdown files (md)
- PDF documents (pdf)
- Plain-text files (txt and etc.)
- Word .docx documents (docx)
- XML files (xml)
Media-types:
- Image (using vision) (jpg, jpeg, png, gif, bmp, tiff, webp)
- Video/audio (mp4, avi, mov, mkv, webm, mp3, mpeg, mpga, m4a, wav)
Archives:
The content from the uploaded attachments will be used in the current conversation and will be available throughout (per context). There are 3 modes available for working with additional context from attachments:
-
Full context: Provides best results. This mode attaches the entire content of the read file to the user's prompt. This process happens in the background and may require a large number of tokens if you uploaded extensive content.
-
RAG: The indexed attachment will only be queried in real-time using LlamaIndex. This operation does not require any additional tokens, but it may not provide access to the full content of the file 1:1.
-
Summary: When queried, an additional query will be generated in the background and executed by a separate model to summarize the content of the attachment and return the required information to the main model. You can change the model used for summarization in the settings under the Files and attachments section.
In the RAG and Summary mode, you can enable an additional setting by going to Settings -> Files and attachments -> Use history in RAG query. This allows for better preparation of queries for RAG. When this option is turned on, the entire conversation context is considered, rather than just the user's last query. This allows for better searching of the index for additional context. In the RAG limit option, you can set a limit on how many recent entries in a discussion should be considered (0 = no limit, default: 3).
Important: When using Full context mode, the entire content of the file is included in the prompt, which can result in high token usage each time. If you want to reduce the number of tokens used, instead use the RAG option, which will only query the indexed attachment in the vector database to provide additional context.
Images as Additional Context
Files such as jpg, png, and similar images are a special case. By default, images are not used as additional context; they are analyzed in real-time using a vision model. If you want to use them as additional context instead, you must enable the "Allow images as additional context" option in the settings: Files and attachments -> Allow images as additional context.
Uploading larger files and auto-index
To use the RAG mode, the file must be indexed in the vector database. This occurs automatically at the time of upload if the Auto-index on upload option in the Attachments tab is enabled. When uploading large files, such indexing might take a while - therefore, if you are using the Full context option, which does not use the index, you can disable the Auto-index option to speed up the upload of the attachment. In this case, it will only be indexed when the RAG option is called for the first time, and until then, attachment will be available in the form of Full context and Summary.
Downloading files
PyGPT enables the automatic download and saving of files created by the model. This is carried out in the background, with the files being saved to an data folder located within the user's working directory. To view or manage these files, users can navigate to the Files tab which features a file browser for this specific directory. Here, users have the interface to handle all files sent by the AI.
This data directory is also where the application stores files that are generated locally by the AI, such as code files or any other data requested from the model. Users have the option to execute code directly from the stored files and read their contents, with the results fed back to the AI. This hands-off process is managed by the built-in plugin system and model-triggered commands. You can also indexing files from this directory (using integrated LlamaIndex) and use it's contents as additional context provided to discussion.
The Files I/O plugin takes care of file operations in the data directory, while the Code Interpreter plugin allows for the execution of code from these files.
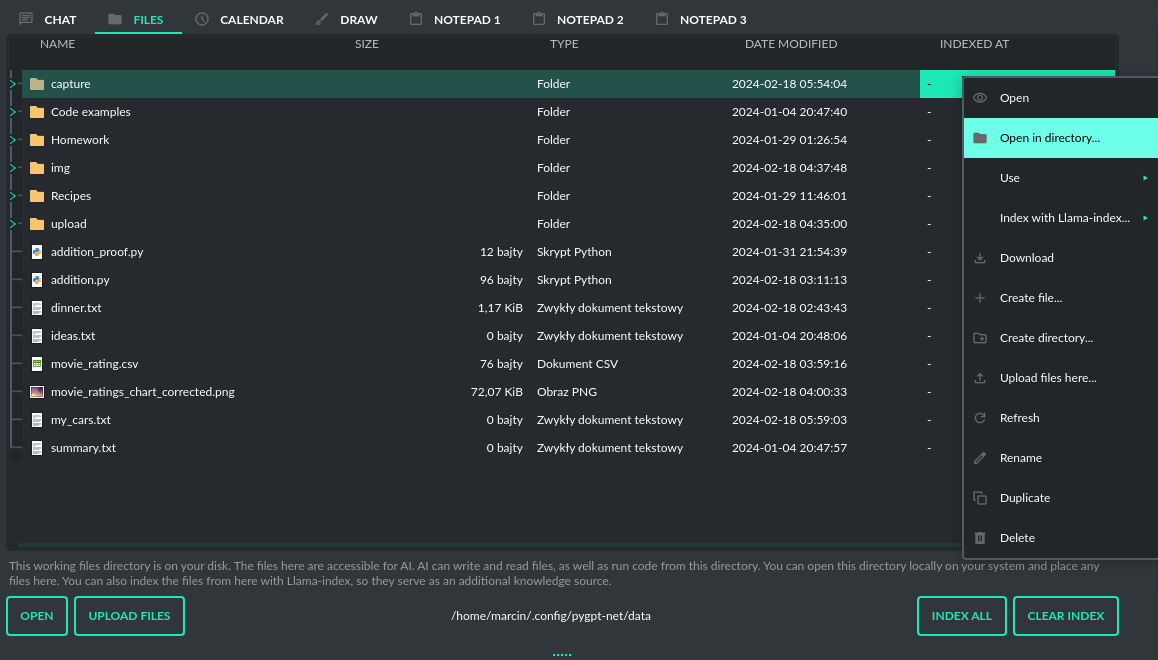
To allow the model to manage files or python code execution, the + Tools option must be active, along with the above-mentioned plugins:

Presets
What is preset?
Presets in PyGPT are essentially templates used to store and quickly apply different configurations. Each preset includes settings for the mode you want to use (such as chat, completion, or image generation), an initial system prompt, an assigned name for the AI, a username for the session, and the desired "temperature" for the conversation. A warmer "temperature" setting allows the AI to provide more creative responses, while a cooler setting encourages more predictable replies. These presets can be used across various modes and with models accessed via the OpenAI API or LangChain.
The application lets you create as many presets as needed and easily switch among them. Additionally, you can clone an existing preset, which is useful for creating variations based on previously set configurations and experimentation.

Example usage
The application includes several sample presets that help you become acquainted with the mechanism of their use.
Profiles
You can create multiple profiles for an app and switch between them. Each profile uses its own configuration, settings, context history, and a separate folder for user files. This allows you to set up different environments and quickly switch between them, changing the entire setup with just one click.
The app lets you create new profiles, edit existing ones, and duplicate current ones.
To create a new profile, select the option from the menu: Config -> Profile -> New Profile...
To edit saved profiles, choose the option from the menu: Config -> Profile -> Edit Profiles...
To switch to a created profile, pick the profile from the menu: Config -> Profile -> [Profile Name]
Each profile uses its own user directory (workdir). You can link a newly created or edited profile to an existing workdir with its configuration.
The name of the currently active profile is shown as (Profile Name) in the window title.
Models
Built-in models
PyGPT has built-in support for models (as of 2024-11-27):
bielik-11b-v2.2-instruct:Q4_K_Mchatgpt-4o-latestclaude-3-5-sonnet-20240620claude-3-opus-20240229codellamadall-e-2dall-e-3gemini-1.5-flashgemini-1.5-progpt-3.5-turbogpt-3.5-turbo-1106gpt-3.5-turbo-16kgpt-3.5-turbo-instructgpt-4gpt-4-0125-previewgpt-4-1106-previewgpt-4-32kgpt-4-turbogpt-4-turbo-2024-04-09gpt-4-turbo-previewgpt-4-vision-previewgpt-4ogpt-4o-2024-11-20gpt-4o-audio-previewgpt-4o-minillama2-uncensoredllama3.1llama3.1:405bllama3.1:70bmistralmistral-largeo1-minio1-preview
All models are specified in the configuration file models.json, which you can customize.
This file is located in your working directory. You can add new models provided directly by OpenAI API
and those supported by LlamaIndex or LangChain to this file. Configuration for LangChain wrapper is placed in langchain key, configuration for LlamaIndex in llama_index key.
Adding a custom model
You can add your own models. See the section Extending PyGPT / Adding a new model for more info.
There is built-in support for those LLM providers:
- OpenAI (openai)
- Azure OpenAI (azure_openai)
- Google (google)
- HuggingFace (huggingface)
- Anthropic (anthropic)
- Ollama (ollama)
How to use local or non-GPT models
Llama 3, Mistral, and other local models
How to use locally installed Llama 3 or Mistral models:
-
Choose a working mode: Chat with Files or LangChain.
-
On the models list - select, edit, or add a new model (with ollama provider). You can edit the model settings through the menu Config -> Models, then configure the model parameters in the advanced section.
-
Download and install Ollama from here: https://github.com/ollama/ollama
For example, on Linux:
curl -fsSL https://ollama.com/install.sh | sh
- Run the model (e.g. Llama 3) locally on your machine. For example, on Linux:
ollama run llama3.1
- Return to PyGPT and select the correct model from models list to chat with selected model using Ollama running locally.
Example available models
llama3.1codellamamistralllama2-uncensored
You can add more models by editing the models list.
List of all models supported by Ollama
https://ollama.com/library
https://github.com/ollama/ollama
IMPORTANT: Remember to define the correct model name in the **kwargs list in the model settings.
Using local embeddings
Refer to: https://docs.llamaindex.ai/en/stable/examples/embeddings/ollama_embedding/
You can use an Ollama instance for embeddings. Simply select the ollama provider in:
Config -> Settings -> Indexes (LlamaIndex) -> Embeddings -> Embeddings provider
Define parameters like model name and Ollama base URL in the Embeddings provider **kwargs list, e.g.:
-
name: model_name, value: llama3.1, type: str
-
name: base_url, value: http://localhost:11434, type: str
Google Gemini and Anthropic Claude
To use Gemini or Claude models, select the Chat with Files mode in PyGPT and select a predefined model.
Remember to configure the required parameters like API keys in the model ENV config fields.
Google Gemini
Required ENV:
Required **kwargs:
Anthropic Claude
Required ENV:
Required **kwargs:
Plugins
Overview
PyGPT can be enhanced with plugins to add new features.
Tip: Plugins works best with GPT-4 models.
The following plugins are currently available, and model can use them instantly:
-
Audio Input - provides speech recognition.
-
Audio Output - provides voice synthesis.
-
Autonomous Agent (inline) - enables autonomous conversation (AI to AI), manages loop, and connects output back to input. This is the inline Agent mode.
-
Chat with Files (LlamaIndex, inline) - plugin integrates LlamaIndex storage in any chat and provides additional knowledge into context (from indexed files and previous context from database).
-
API calls - plugin lets you connect the model to the external services using custom defined API calls.
-
Code Interpreter - responsible for generating and executing Python code, functioning much like
the Code Interpreter on ChatGPT, but locally. This means GPT can interface with any script, application, or code.
Plugins can work in conjunction to perform sequential tasks; for example, the Files plugin can write generated
Python code to a file, which the Code Interpreter can execute it and return its result to GPT.
-
Custom Commands - allows you to create and execute custom commands on your system.
-
Files I/O - provides access to the local filesystem, enabling GPT to read and write files,
as well as list and create directories.
-
System (OS) - allows you to create and execute custom commands on your system.
-
Mouse and Keyboard - provides the ability to control the mouse and keyboard by the model.
-
Web Search - provides the ability to connect to the Web, search web pages for current data, and index external content using LlamaIndex data loaders.
-
Serial port / USB - plugin provides commands for reading and sending data to USB ports.
-
Context history (calendar, inline) - provides access to context history database.
-
Crontab / Task scheduler - plugin provides cron-based job scheduling - you can schedule tasks/prompts to be sent at any time using cron-based syntax for task setup.
-
DALL-E 3: Image Generation (inline) - integrates DALL-E 3 image generation with any chat and mode. Just enable and ask for image in Chat mode, using standard model like GPT-4. The plugin does not require the + Tools option to be enabled.
-
Experts (inline) - allows calling experts in any chat mode. This is the inline Experts (co-op) mode.
-
GPT-4 Vision (inline) - integrates Vision capabilities with any chat mode, not just Vision mode. When the plugin is enabled, the model temporarily switches to vision in the background when an image attachment or vision capture is provided.
-
Real Time - automatically appends the current date and time to the system prompt, informing the model about current time.
-
System Prompt Extra (append) - appends additional system prompts (extra data) from a list to every current system prompt. You can enhance every system prompt with extra instructions that will be automatically appended to the system prompt.
-
Voice Control (inline) - provides voice control command execution within a conversation.
-
Mailer - Provides the ability to send, receive and read emails.
Audio Input
The plugin facilitates speech recognition (by default using the Whisper model from OpenAI, Google and Bing are also available). It allows for voice commands to be relayed to the AI using your own voice. Whisper doesn't require any extra API keys or additional configurations; it uses the main OpenAI key. In the plugin's configuration options, you should adjust the volume level (min energy) at which the plugin will respond to your microphone. Once the plugin is activated, a new Speak option will appear at the bottom near the Send button - when this is enabled, the application will respond to the voice received from the microphone.
The plugin can be extended with other speech recognition providers.
Options:
Choose the provider. Default: Whisper
Available providers:
- Whisper (via
OpenAI API)
- Whisper (local model) - not available in compiled and Snap versions, only Python/PyPi version
- Google (via
SpeechRecognition library)
- Google Cloud (via
SpeechRecognition library)
- Microsoft Bing (via
SpeechRecognition library)
Whisper (API)
Choose the model. Default: whisper-1
Whisper (local)
Model whisper_local_model
Choose the local model. Default: base
Available models: https://github.com/openai/whisper
Google
Additional keywords arguments google_args
Additional keywords arguments for r.recognize_google(audio, **kwargs)
Google Cloud
Additional keywords arguments google_cloud_args
Additional keywords arguments for r.recognize_google_cloud(audio, **kwargs)
Bing
Additional keywords arguments bing_args
Additional keywords arguments for r.recognize_bing(audio, **kwargs)
General options
Automatically send recognized speech as input text after recognition. Default: True
Enable only if you want to use advanced mode and the settings below. Do not enable this option if you just want to use the simplified mode (default). Default: False
Advanced mode options
The duration in seconds that the application waits for voice input from the microphone. Default: 5
Phrase max length phrase_length
Maximum duration for a voice sample (in seconds). Default: 10
Minimum threshold multiplier above the noise level to begin recording. Default: 1.3
Adjust for ambient noise adjust_noise
Enables adjustment to ambient noise levels. Default: True
Continuous listen continuous_listen
Experimental: continuous listening - do not stop listening after a single input.
Warning: This feature may lead to unexpected results and requires fine-tuning with
the rest of the options! If disabled, listening must be started manually
by enabling the Speak option. Default: False
Wait for response wait_response
Wait for a response before initiating listening for the next input. Default: True
Activate listening only after the magic word is provided. Default: False
Reset Magic word magic_word_reset
Reset the magic word status after it is received (the magic word will need to be provided again). Default: True
List of magic words to initiate listening (Magic word mode must be enabled). Default: OK, Okay, Hey GPT, OK GPT
Magic word timeout magic_word_timeout
The number of seconds the application waits for magic word. Default: 1
Magic word phrase max length magic_word_phrase_length
The minimum phrase duration for magic word. Default: 2
Prefix words prefix_words
List of words that must initiate each phrase to be processed. For example, you can define words like "OK" or "GPT"—if set, any phrases not starting with those words will be ignored. Insert multiple words or phrases separated by commas. Leave empty to deactivate. Default: empty
List of words that will stop the listening process. Default: stop, exit, quit, end, finish, close, terminate, kill, halt, abort
Options related to Speech Recognition internals:
energy_threshold recognition_energy_threshold
Represents the energy level threshold for sounds. Default: 300
dynamic_energy_threshold recognition_dynamic_energy_threshold
Represents whether the energy level threshold (see recognizer_instance.energy_threshold) for sounds
should be automatically adjusted based on the currently ambient noise level while listening. Default: True
dynamic_energy_adjustment_damping recognition_dynamic_energy_adjustment_damping
Represents approximately the fraction of the current energy threshold that is retained after one second
of dynamic threshold adjustment. Default: 0.15
pause_threshold recognition_pause_threshold
Represents the minimum length of silence (in seconds) that will register as the end of a phrase. Default: 0.8
adjust_for_ambient_noise: duration recognition_adjust_for_ambient_noise_duration
The duration parameter is the maximum number of seconds that it will dynamically adjust the threshold
for before returning. Default: 1
Options reference: https://pypi.org/project/SpeechRecognition/1.3.1/
Audio Output
The plugin lets you turn text into speech using the TTS model from OpenAI or other services like Microsoft Azure, Google, and Eleven Labs. You can add more text-to-speech providers to it too. OpenAI TTS does not require any additional API keys or extra configuration; it utilizes the main OpenAI key.
Microsoft Azure requires to have an Azure API Key. Before using speech synthesis via Microsoft Azure, Google or Eleven Labs, you must configure the audio plugin with your API keys, regions and voices if required.

Through the available options, you can select the voice that you want the model to use. More voice synthesis providers coming soon.
To enable voice synthesis, activate the Audio Output plugin in the Plugins menu or turn on the Audio Output option in the Audio / Voice menu (both options in the menu achieve the same outcome).
Options
Choose the provider. Default: OpenAI TTS
Available providers:
- OpenAI TTS
- Microsoft Azure TTS
- Google TTS
- Eleven Labs TTS
OpenAI Text-To-Speech
Choose the model. Available options:
- tts-1
- tts-1-hd
Default: tts-1
Choose the voice. Available voices to choose from:
- alloy
- echo
- fable
- onyx
- nova
- shimmer
Default: alloy
Microsoft Azure Text-To-Speech
Azure API Key azure_api_key
Here, you should enter the API key, which can be obtained by registering for free on the following website: https://azure.microsoft.com/en-us/services/cognitive-services/text-to-speech
Azure Region azure_region
You must also provide the appropriate region for Azure here. Default: eastus
Voice (EN) azure_voice_en
Here you can specify the name of the voice used for speech synthesis for English. Default: en-US-AriaNeural
Voice (non-English) azure_voice_pl
Here you can specify the name of the voice used for speech synthesis for other non-english languages. Default: pl-PL-AgnieszkaNeural
Google Text-To-Speech
Google Cloud Text-to-speech API Key google_api_key
You can obtain your own API key at: https://console.cloud.google.com/apis/library/texttospeech.googleapis.com
Specify voice. Voices: https://cloud.google.com/text-to-speech/docs/voices
Language code google_api_key
Language code. Language codes: https://cloud.google.com/speech-to-text/docs/speech-to-text-supported-languages
Eleven Labs Text-To-Speech
Eleven Labs API Key eleven_labs_api_key
You can obtain your own API key at: https://elevenlabs.io/speech-synthesis
Voice ID eleven_labs_voice
Voice ID. Voices: https://elevenlabs.io/voice-library
Specify model. Models: https://elevenlabs.io/docs/speech-synthesis/models
If speech synthesis is enabled, a voice will be additionally generated in the background while generating a response via GPT.
Both OpenAI TTS and OpenAI Whisper use the same single API key provided for the OpenAI API, with no additional keys required.
Autonomous Agent (inline)
WARNING: Please use autonomous mode with caution! - this mode, when connected with other plugins, may produce unexpected results!
The plugin activates autonomous mode in standard chat modes, where AI begins a conversation with itself.
You can set this loop to run for any number of iterations. Throughout this sequence, the model will engage
in self-dialogue, answering his own questions and comments, in order to find the best possible solution, subjecting previously generated steps to criticism.
This mode is similar to Auto-GPT - it can be used to create more advanced inferences and to solve problems by breaking them down into subtasks that the model will autonomously perform one after another until the goal is achieved. The plugin is capable of working in cooperation with other plugins, thus it can utilize tools such as web search, access to the file system, or image generation using DALL-E.
You can adjust the number of iterations for the self-conversation in the Plugins / Settings... menu under the following option:
Default: 3
WARNING: Setting this option to 0 activates an infinity loop which can generate a large number of requests and cause very high token consumption, so use this option with caution!
Editable list of prompts used to instruct how to handle autonomous mode, you can create as many prompts as you want.
First active prompt on list will be used to handle autonomous mode. INFO: At least one active prompt is required!
Auto-stop after goal is reached auto_stop
If enabled, plugin will stop after goal is reached." Default: True
Reverse roles between iterations reverse_roles
Only for Completion/LangChain modes.
If enabled, this option reverses the roles (AI <> user) with each iteration. For example,
if in the previous iteration the response was generated for "Batman," the next iteration will use that
response to generate an input for "Joker." Default: True
Chat with Files (LlamaIndex, inline)
Plugin integrates LlamaIndex storage in any chat and provides additional knowledge into context.
Ask LlamaIndex first ask_llama_first
When enabled, then LlamaIndex will be asked first, and response will be used as additional knowledge in prompt. When disabled, then LlamaIndex will be asked only when needed. INFO: Disabled in autonomous mode (via plugin)! Default: False
Auto-prepare question before asking LlamaIndex first prepare_question
When enabled, then question will be prepared before asking LlamaIndex first to create best query. Default: False
Model for question preparation model_prepare_question
Model used to prepare question before asking LlamaIndex. Default: gpt-3.5-turbo
Max output tokens for question preparation prepare_question_max_tokens
Max tokens in output when preparing question before asking LlamaIndex. Default: 500
Prompt for question preparation syntax_prepare_question
System prompt for question preparation.
Max characters in question max_question_chars
Max characters in question when querying LlamaIndex, 0 = no limit. Default: 1000
Append metadata to context append_meta
If enabled, then metadata from LlamaIndex will be appended to additional context. Default: False
Model used for querying LlamaIndex. Default: gpt-3.5-turbo
Indexes to use. If you want to use multiple indexes at once then separate them by comma. Default: base
API calls
PyGPT lets you connect the model to the external services using custom defined API calls.
To activate this feature, turn on the API calls plugin found in the Plugins menu.
In this plugin you can provide list of allowed API calls, their parameters and request types. The model will replace provided placeholders with required params and make API call to external service.
Your custom API calls cmds
You can provide custom API calls on the list here.
Params to specify for API call:
- Enabled (True / False)
- Name: unique API call name (ID)
- Instruction: description for model when and how to use this API call
- GET params: list, separated by comma, GET params to append to endpoint URL
- POST params: list, separated by comma, POST params to send in POST request
- POST JSON: provide the JSON object, template to send in POST JSON request, use
%param% as POST param placeholders
- Headers: provide the JSON object with dictionary of extra request headers, like Authorization, API keys, etc.
- Request type: use GET for basic GET request, POST to send encoded POST params or POST_JSON to send JSON-encoded object as body
- Endpoint: API endpoint URL, use
{param} as GET param placeholders
An example API call is provided with plugin by default, it calls the Wikipedia API:
In the above example, every time you ask the model for query Wiki for provided query (e.g. Call the Wikipedia API for query: Nikola Tesla) it will replace placeholders in provided API endpoint URL with a generated query and it will call prepared API endpoint URL, like below:
https://en.wikipedia.org/w/api.php?action=opensearch&limit=5&format=json&search=Nikola%20Tesla
You can specify type of request: GET, POST and POST JSON.
In the POST request you can provide POST params, they will be encoded and send as POST data.
In the POST JSON request you must provide JSON object template to be send, using %param% placeholders in the JSON object to be replaced with the model.
You can also provide any required credentials, like Authorization headers, API keys, tokens, etc. using the headers field - you can provide a JSON object here with a dictionary key => value - provided JSON object will be converted to headers dictonary and send with the request.
Disable SSL verify disable_ssl
Disables SSL verification when making requests. Default: False
Connection timeout (seconds). Default: 5
User agent to use when making requests. Default: Mozilla/5.0
Code Interpreter
Executing Code
From version 2.4.13 with built-in IPython.
The plugin operates similarly to the Code Interpreter in ChatGPT, with the key difference that it works locally on the user's system. It allows for the execution of any Python code on the computer that the model may generate. When combined with the Files I/O plugin, it facilitates running code from files saved in the data directory. You can also prepare your own code files and enable the model to use them or add your own plugin for this purpose. You can execute commands and code on the host machine or in Docker container.
IPython: Starting from version 2.4.13, it is highly recommended to adopt the new option: IPython, which offers significant improvements over previous workflows. IPython provides a robust environment for executing code within a kernel, allowing you to maintain the state of your session by preserving the results of previous commands. This feature is particularly useful for iterative development and data analysis, as it enables you to build upon prior computations without starting from scratch. Moreover, IPython supports the use of magic commands, such as !pip install <package_name>, which facilitate the installation of new packages directly within the session. This capability streamlines the process of managing dependencies and enhances the flexibility of your development environment. Overall, IPython offers a more efficient and user-friendly experience for executing and managing code.
To use IPython in sandbox mode, Docker must be installed on your system.
You can find the installation instructions here: https://docs.docker.com/engine/install/
Tip: connecting IPython in Docker in Snap version:
To use IPython in the Snap version, you must connect PyGPT to the Docker daemon:
sudo snap connect pygpt:docker-executables docker:docker-executables
sudo snap connect pygpt:docker docker:docker-daemon
Code interpreter: a real-time Python Code Interpreter is built-in. Click the <> icon to open the interpreter window. Both the input and output of the interpreter are connected to the plugin. Any output generated by the executed code will be displayed in the interpreter. Additionally, you can request the model to retrieve contents from the interpreter window output.
Tip: always remember to enable the + Tools option to allow execute commands from the plugins.
Options:
General
Connect to the Python Code Interpreter window attach_output
Automatically attach code input/output to the Python Code Interpreter window. Default: True
Tool: get_python_output cmd.get_python_output
Allows get_python_output command execution. If enabled, it allows retrieval of the output from the Python Code Interpreter window. Default: True
Tool: get_python_input cmd.get_python_input
Allows get_python_input command execution. If enabled, it allows retrieval all input code (from edit section) from the Python Code Interpreter window. Default: True
Tool: clear_python_output cmd.clear_python_output
Allows clear_python_output command execution. If enabled, it allows clear the output of the Python Code Interpreter window. Default: True
IPython
Sandbox (docker container) sandbox_ipython
Executes IPython in sandbox (docker container). Docker must be installed and running.
Dockerfile ipython_dockerfile
You can customize the Dockerfile for the image used by IPython by editing the configuration above and rebuilding the image via Tools -> Rebuild IPython Docker Image.
Session Key ipython_session_key
It must match the key provided in the Dockerfile.
Docker image name ipython_image_name
Custom image name
Docker container name ipython_container_name
Custom container name
Connection address ipython_conn_addr
Default: 127.0.0.1
Port: shell ipython_port_shell
Default: 5555
Port: iopub ipython_port_iopub
Default: 5556
Port: stdin ipython_port_stdin
Default: 5557
Port: control ipython_port_control
Default: 5558
Default: 5559
Tool: ipython_execute cmd.ipython_execute
Allows Python code execution in IPython interpreter (in current kernel). Default: True
Tool: python_kernel_restart cmd.ipython_kernel_restart
Allows to restart IPython kernel. Default: True
Python (legacy)
Sandbox (docker container) sandbox_docker
Executes commands in sandbox (docker container). Docker must be installed and running.
Python command template python_cmd_tpl
Python command template (use {filename} as path to file placeholder). Default: python3 {filename}
You can customize the Dockerfile for the image used by legacy Python by editing the configuration above and rebuilding the image via Tools -> Rebuild Python (Legacy) Docker Image.
Docker image name image_name
Custom Docker image name
Docker container name container_name
Custom Docker container name
Tool: code_execute cmd.code_execute
Allows code_execute command execution. If enabled, provides Python code execution (generate and execute from file). Default: True
Tool: code_execute_all cmd.code_execute_all
Allows code_execute_all command execution. If enabled, provides execution of all the Python code in interpreter window. Default: True
Tool: code_execute_file cmd.code_execute_file
Allows code_execute_file command execution. If enabled, provides Python code execution from existing .py file. Default: True
HTML Canvas
Tool: render_html_output cmd.render_html_output
Allows render_html_output command execution. If enabled, it allows to render HTML/JS code in built-it HTML/JS browser (HTML Canvas). Default: True
Tool: get_html_output cmd.get_html_output
Allows get_html_output command execution. If enabled, it allows retrieval current output from HTML Canvas. Default: True
Sandbox (docker container) sandbox_docker
Execute commands in sandbox (docker container). Docker must be installed and running. Default: False
Docker image sandbox_docker_image
Docker image to use for sandbox Default: python:3.8-alpine
Custom Commands
With the Custom Commands plugin, you can integrate PyGPT with your operating system and scripts or applications. You can define an unlimited number of custom commands and instruct GPT on when and how to execute them. Configuration is straightforward, and PyGPT includes a simple tutorial command for testing and learning how it works:

To add a new custom command, click the ADD button and then:
- Provide a name for your command: this is a unique identifier for GPT.
- Provide an
instruction explaining what this command does; GPT will know when to use the command based on this instruction.
- Define
params, separated by commas - GPT will send data to your commands using these params. These params will be placed into placeholders you have defined in the cmd field. For example:
If you want instruct GPT to execute your Python script named smart_home_lights.py with an argument, such as 1 to turn the light ON, and 0 to turn it OFF, define it as follows:
- name: lights_cmd
- instruction: turn lights on/off; use 1 as 'arg' to turn ON, or 0 as 'arg' to turn OFF
- params: arg
- cmd:
python /path/to/smart_home_lights.py {arg}
The setup defined above will work as follows:
When you ask GPT to turn your lights ON, GPT will locate this command and prepare the command python /path/to/smart_home_lights.py {arg} with {arg} replaced with 1. On your system, it will execute the command:
python /path/to/smart_home_lights.py 1
And that's all. GPT will take care of the rest when you ask to turn ON the lights.
You can define as many placeholders and parameters as you desire.
Here are some predefined system placeholders for use:
{_time} - current time in H:M:S format{_date} - current date in Y-m-d format{_datetime} - current date and time in Y-m-d H:M:S format{_file} - path to the file from which the command is invoked{_home} - path to PyGPT's home/working directory
You can connect predefined placeholders with your own params.
Example:
- name: song_cmd
- instruction: store the generated song on hard disk
- params: song_text, title
- cmd:
echo "{song_text}" > {_home}/{title}.txt
With the setup above, every time you ask GPT to generate a song for you and save it to the disk, it will:
- Generate a song.
- Locate your command.
- Execute the command by sending the song's title and text.
- The command will save the song text into a file named with the song's title in the PyGPT working directory.
Example tutorial command
PyGPT provides simple tutorial command to show how it works, to run it just ask GPT for execute tutorial test command and it will show you how it works:
> please execute tutorial test command

Files I/O
The plugin allows for file management within the local filesystem. It enables the model to create, read, write and query files located in the data directory, which can be found in the user's work directory. With this plugin, the AI can also generate Python code files and thereafter execute that code within the user's system.
Plugin capabilities include:
- Sending files as attachments
- Reading files
- Appending to files
- Writing files
- Deleting files and directories
- Listing files and directories
- Creating directories
- Downloading files
- Copying files and directories
- Moving (renaming) files and directories
- Reading file info
- Indexing files and directories using LlamaIndex
- Querying files using LlamaIndex
- Searching for files and directories
If a file being created (with the same name) already exists, a prefix including the date and time is added to the file name.
Options:
General
Tool: send (upload) file as attachment cmd.send_file
Allows cmd.send_file command execution. Default: True
Tool: read file cmd.read_file
Allows read_file command execution. Default: True
Tool: append to file cmd.append_file
Allows append_file command execution. Text-based files only (plain text, JSON, CSV, etc.) Default: True
Tool: save file cmd.save_file
Allows save_file command execution. Text-based files only (plain text, JSON, CSV, etc.) Default: True
Tool: delete file cmd.delete_file
Allows delete_file command execution. Default: True
Tool: list files (ls) cmd.list_files
Allows list_dir command execution. Default: True
Tool: list files in dirs in directory (ls) cmd.list_dir
Allows mkdir command execution. Default: True
Tool: downloading files cmd.download_file
Allows download_file command execution. Default: True
Tool: removing directories cmd.rmdir
Allows rmdir command execution. Default: True
Tool: copying files cmd.copy_file
Allows copy_file command execution. Default: True
Tool: copying directories (recursive) cmd.copy_dir
Allows copy_dir command execution. Default: True
Tool: move files and directories (rename) cmd.move
Allows move command execution. Default: True
Tool: check if path is directory cmd.is_dir
Allows is_dir command execution. Default: True
Tool: check if path is file cmd.is_file
Allows is_file command execution. Default: True
Tool: check if file or directory exists cmd.file_exists
Allows file_exists command execution. Default: True
Tool: get file size cmd.file_size
Allows file_size command execution. Default: True
Tool: get file info cmd.file_info
Allows file_info command execution. Default: True
Tool: find file or directory cmd.find
Allows find command execution. Default: True
Tool: get current working directory cmd.cwd
Allows cwd command execution. Default: True
Use data loaders use_loaders
Use data loaders from LlamaIndex for file reading (read_file command). Default: True
Indexing
Tool: quick query the file with LlamaIndex cmd.query_file
Allows query_file command execution (in-memory index). If enabled, model will be able to quick index file into memory and query it for data (in-memory index) Default: True
Model for query in-memory index model_tmp_query
Model used for query temporary index for query_file command (in-memory index). Default: gpt-3.5-turbo
Tool: indexing files to persistent index cmd.file_index
Allows file_index command execution. If enabled, model will be able to index file or directory using LlamaIndex (persistent index). Default: True
Index to use when indexing files idx
ID of index to use for indexing files (persistent index). Default: base
Auto index reading files auto_index
If enabled, every time file is read, it will be automatically indexed (persistent index). Default: False
Only index reading files only_index
If enabled, file will be indexed without return its content on file read (persistent index). Default: False
System (OS)
The plugin provides access to the operating system and executes system commands.
Options:
General
Auto-append CWD to sys_exec auto_cwd
Automatically append current working directory to sys_exec command. Default: True
Tool: sys_exec cmd.sys_exec
Allows sys_exec command execution. If enabled, provides system commands execution. Default: True
Mouse And Keyboard
Introduced in version: 2.4.4 (2024-11-09)
WARNING: Use this plugin with caution - allowing all options gives the model full control over the mouse and keyboard
The plugin allows for controlling the mouse and keyboard by the model. With this plugin, you can send a task to the model, e.g., "open notepad, type something in it" or "open web browser, do search, find something."
Plugin capabilities include:
- Get mouse cursor position
- Control mouse cursor position
- Control mouse clicks
- Control mouse scroll
- Control the keyboard (pressing keys, typing text)
- Making screenshots
The + Tools option must be enabled to use this plugin.
Options:
General
Prompt used to instruct how to control the mouse and keyboard.
Enable: Allow mouse movement allow_mouse_move
Allows mouse movement. Default: True
Enable: Allow mouse click allow_mouse_click
Allows mouse click. Default: True
Enable: Allow mouse scroll allow_mouse_scroll
Allows mouse scroll. Default: True
Enable: Allow keyboard key press allow_keyboard
Allows keyboard typing. Default: True
Enable: Allow making screenshots allow_screenshot
Allows making screenshots. Default: True
Tool: mouse_get_pos cmd.mouse_get_pos
Allows mouse_get_pos command execution. Default: True
Tool: mouse_set_pos cmd.mouse_set_pos
Allows mouse_set_pos command execution. Default: True
Tool: make_screenshot cmd.make_screenshot
Allows make_screenshot command execution. Default: True
Tool: mouse_click cmd.mouse_click
Allows mouse_click command execution. Default: True
Tool: mouse_move cmd.mouse_move
Allows mouse_move command execution. Default: True
Tool: mouse_scroll cmd.mouse_scroll
Allows mouse_scroll command execution. Default: True
Tool: keyboard_key cmd.keyboard_key
Allows keyboard_key command execution. Default: True
Tool: keyboard_type cmd.keyboard_type
Allows keyboard_type command execution. Default: True
Web Search
PyGPT lets you connect GPT to the internet and carry out web searches in real time as you make queries.
To activate this feature, turn on the Web Search plugin found in the Plugins menu.
Web searches are provided by Google Custom Search Engine and Microsoft Bing APIs and can be extended with other search engine providers.
Options
Choose the provider. Default: Google
Available providers:
Google
To use this provider, you need an API key, which you can obtain by registering an account at:
https://developers.google.com/custom-search/v1/overview
After registering an account, create a new project and select it from the list of available projects:
https://programmablesearchengine.google.com/controlpanel/all
After selecting your project, you need to enable the Whole Internet Search option in its settings.
Then, copy the following two items into PyGPT:
These data must be configured in the appropriate fields in the Plugins / Settings... menu:

Google Custom Search API KEY google_api_key
You can obtain your own API key at https://developers.google.com/custom-search/v1/overview
Google Custom Search CX ID google_api_cx
You will find your CX ID at https://programmablesearchengine.google.com/controlpanel/all - remember to enable "Search on ALL internet pages" option in project settings.
Microsoft Bing
Bing Search API KEY bing_api_key
You can obtain your own API key at https://www.microsoft.com/en-us/bing/apis/bing-web-search-api
Bing Search API endpoint bing_endpoint
API endpoint for Bing Search API, default: https://api.bing.microsoft.com/v7.0/search
General options
Number of pages to search num_pages
Number of max pages to search per query. Default: 10
Max content characters max_page_content_length
Max characters of page content to get (0 = unlimited). Default: 0
Per-page content chunk size chunk_size
Per-page content chunk size (max characters per chunk). Default: 20000
Disable SSL verify disable_ssl
Disables SSL verification when crawling web pages. Default: False
Use raw content (without summarization) raw
Return raw content from web search instead of summarized content. Provides more data but consumes more tokens. Default: True
Connection timeout (seconds). Default: 5
User agent to use when making requests. Default: Mozilla/5.0.
Max result length max_result_length
Max length of the summarized or raw result (characters). Default: 50000
Max summary tokens summary_max_tokens
Max tokens in output when generating summary. Default: 1500
Tool: web_search cmd.web_search
Allows web_search command execution. If enabled, model will be able to search the Web. Default: True
Tool: web_url_open cmd.web_url_open
Allows web_url_open command execution. If enabled, model will be able to open specified URL and summarize content. Default: True
Tool: web_url_raw cmd.web_url_raw
Allows web_url_raw command execution. If enabled, model will be able to open specified URL and get the raw content. Default: True
Tool: web_request cmd.web_request
Allows web_request command execution. If enabled, model will be able to send any HTTP request to specified URL or API endpoint. Default: True
Tool: web_extract_links cmd.web_extract_links
Allows web_extract_links command execution. If enabled, model will be able to open URL and get list of all links from it. Default: True
Tool: web_extract_images cmd.web_extract_images
Allows web_extract_images command execution. If enabled, model will be able to open URL and get list of all images from it.. Default: True
Advanced
Model used for web page summarize summary_model
Model used for web page summarize. Default: gpt-4o-mini
Summarize prompt prompt_summarize
Prompt used for web search results summarize, use {query} as a placeholder for search query.
Summarize prompt (URL open) prompt_summarize_url
Prompt used for specified URL page summarize.
Indexing
Tool: web_index cmd.web_index
Allows web_index command execution. If enabled, model will be able to index pages and external content using LlamaIndex (persistent index). Default: True
Tool: web_index_query cmd.web_index_query
Allows web_index_query command execution. If enabled, model will be able to quick index and query web content using LlamaIndex (in-memory index). Default: True
Auto-index all used URLs using LlamaIndex auto_index
If enabled, every URL used by the model will be automatically indexed using LlamaIndex (persistent index). Default: False
ID of index to use for web page indexing (persistent index). Default: base
Serial port / USB
Provides commands for reading and sending data to USB ports.
Tip: in Snap version you must connect the interface first: https://snapcraft.io/docs/serial-port-interface
You can send commands to, for example, an Arduino or any other controllers using the serial port for communication.
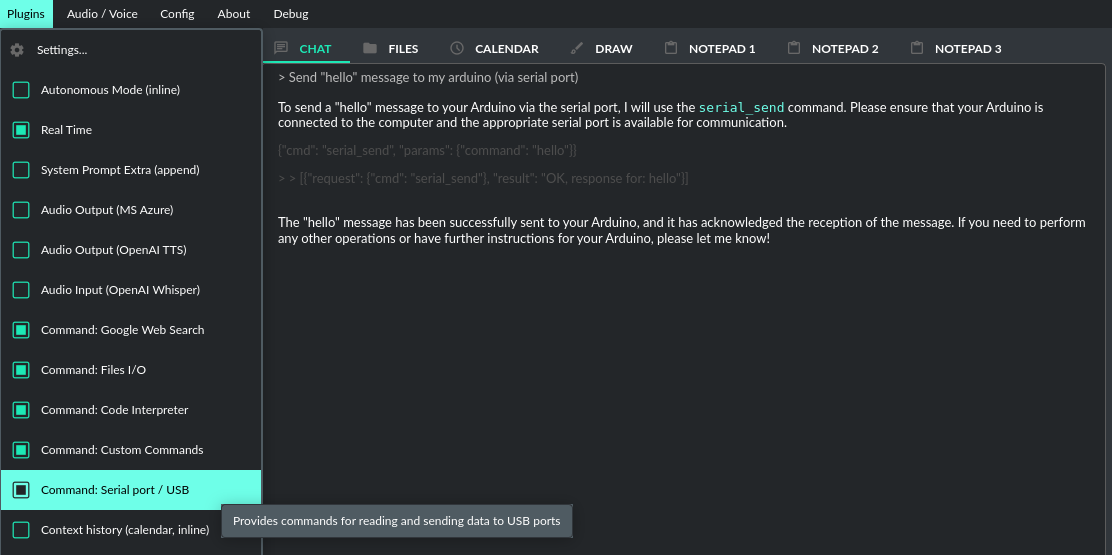
Above is an example of co-operation with the following code uploaded to Arduino Uno and connected via USB:
void setup() {
Serial.begin(9600);
}
void loop() {
if (Serial.available() > 0) {
String input = Serial.readStringUntil('\n');
if (input.length() > 0) {
Serial.println("OK, response for: " + input);
}
}
}
Options
USB port name, e.g. /dev/ttyUSB0, /dev/ttyACM0, COM3. Default: /dev/ttyUSB0
Connection speed (baudrate, bps) serial_bps
Port connection speed, in bps. Default: 9600
Timeout in seconds. Default: 1
Sleep in seconds after connection Default: 2
Tool: Send text commands to USB port cmd.serial_send
Allows serial_send command execution. Default: True
Tool: Send raw bytes to USB port cmd.serial_send_bytes
Allows serial_send_bytes command execution. Default: True
Tool: Read data from USB port cmd.serial_read
Allows serial_read command execution. Default: True
Context history (calendar, inline)
Provides access to context history database.
Plugin also provides access to reading and creating day notes.
Examples of use, you can ask e.g. for the following:
Give me today day note
Save a new note for today
Update my today note with...
Get the list of yesterday conversations
Get contents of conversation ID 123
etc.
You can also use @ ID tags to automatically use summary of previous contexts in current discussion.
To use context from previous discussion with specified ID use following syntax in your query:
@123
Where 123 is the ID of previous context (conversation) in database, example of use:
Let's talk about discussion @123
Options
Enable: using context @ ID tags use_tags
When enabled, it allows to automatically retrieve context history using @ tags, e.g. use @123 in question to use summary of context with ID 123 as additional context. Default: False
Tool: get date range context list cmd.get_ctx_list_in_date_range
Allows get_ctx_list_in_date_range command execution. If enabled, it allows getting the list of context history (previous conversations). Default: `True
Tool: get context content by ID cmd.get_ctx_content_by_id
Allows get_ctx_content_by_id command execution. If enabled, it allows getting summarized content of context with defined ID. Default: True
Tool: count contexts in date range cmd.count_ctx_in_date
Allows count_ctx_in_date command execution. If enabled, it allows counting contexts in date range. Default: True
Tool: get day note cmd.get_day_note
Allows get_day_note command execution. If enabled, it allows retrieving day note for specific date. Default: True
Tool: add day note cmd.add_day_note
Allows add_day_note command execution. If enabled, it allows adding day note for specific date. Default: True
Tool: update day note cmd.update_day_note
Allows update_day_note command execution. If enabled, it allows updating day note for specific date. Default: True
Tool: remove day note cmd.remove_day_note
Allows remove_day_note command execution. If enabled, it allows removing day note for specific date. Default: True
Model used for summarize. Default: gpt-3.5-turbo
Max summary tokens summary_max_tokens
Max tokens in output when generating summary. Default: 1500
Max contexts to retrieve ctx_items_limit
Max items in context history list to retrieve in one query. 0 = no limit. Default: 30
Per-context items content chunk size chunk_size
Per-context content chunk size (max characters per chunk). Default: 100000 chars
Options (advanced)
Prompt: @ tags (system) prompt_tag_system
Prompt for use @ tag (system).
Prompt: @ tags (summary) prompt_tag_summary
Prompt for use @ tag (summary).
Crontab / Task scheduler
Plugin provides cron-based job scheduling - you can schedule tasks/prompts to be sent at any time using cron-based syntax for task setup.
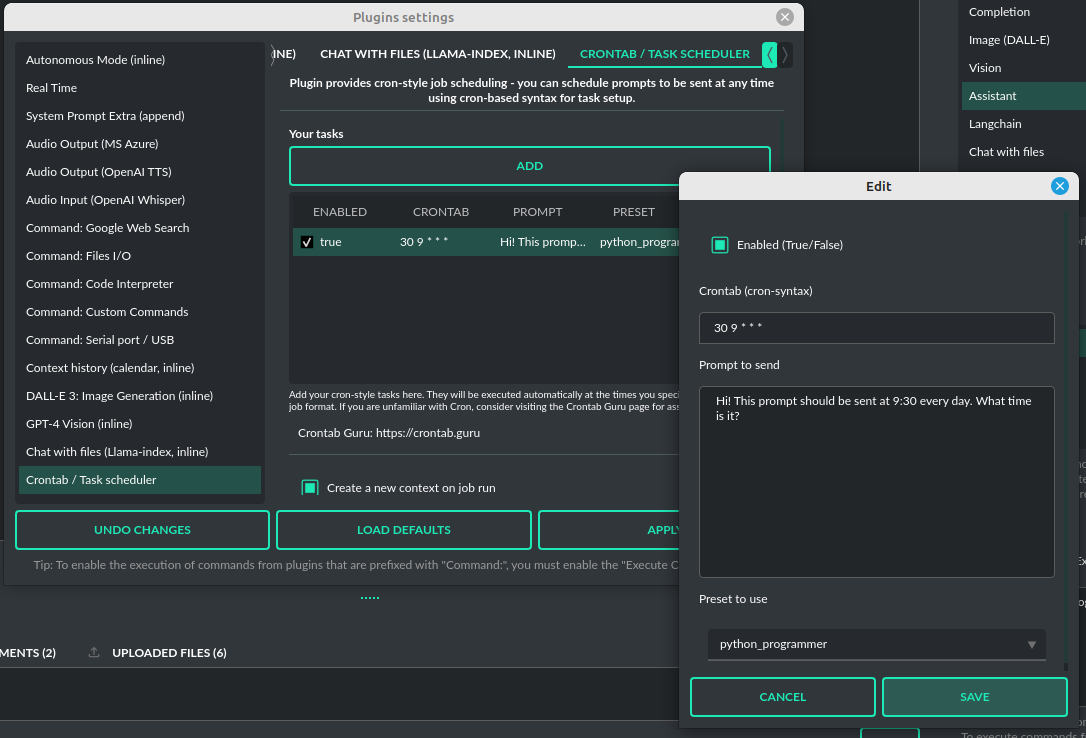
Add your cron-style tasks here.
They will be executed automatically at the times you specify in the cron-based job format.
If you are unfamiliar with Cron, consider visiting the Cron Guru page for assistance: https://crontab.guru
Number of active tasks is always displayed in a tray dropdown menu:
Create a new context on job run new_ctx
If enabled, then a new context will be created on every run of the job. Default: True
Show notification on job run show_notify
If enabled, then a tray notification will be shown on every run of the job. Default: True
DALL-E 3: Image Generation (inline)
The plugin integrates DALL-E 3 image generation with any chat mode. Simply enable it and request an image in Chat mode, using a standard model such as GPT-4. The plugin does not require the + Tools option to be enabled.
Options
The prompt is used to generate a query for the DALL-E image generation model, which runs in the background.
Experts (inline)
The plugin allows calling experts in any chat mode. This is the inline Experts (co-op) mode.
See the Work modes -> Experts section for more details.
GPT-4 Vision (inline)
The plugin integrates vision capabilities across all chat modes, not just Vision mode. Once enabled, it allows the model to seamlessly switch to vision processing in the background whenever an image attachment or vision capture is detected.
Tip: When using Vision (inline) by utilizing a plugin in standard mode, such as Chat (not Vision mode), the + Vision special checkbox will appear at the bottom of the Chat window. It will be automatically enabled any time you provide content for analysis (like an uploaded photo). When the checkbox is enabled, the vision model is used. If you wish to exit the vision model after image analysis, simply uncheck the checkbox. It will activate again automatically when the next image content for analysis is provided.
Options
The model used to temporarily provide vision capabilities. Default: gpt-4-vision-preview.
The prompt used for vision mode. It will append or replace current system prompt when using vision model.
Replace prompt replace_prompt
Replace whole system prompt with vision prompt against appending it to the current prompt. Default: False
Tool: capturing images from camera cmd.camera_capture
Allows capture command execution. If enabled, model will be able to capture images from camera itself. The + Tools option must be enabled. Default: False
Tool: making screenshots cmd.make_screenshot
Allows screenshot command execution. If enabled, model will be able to making screenshots itself. The + Tools option must be enabled. Default: False
Mailer
Enables the sending, receiving, and reading of emails from the inbox. Currently, only SMTP is supported. More options coming soon.
Options
From (email), e.g. me@domain.com
Tool: send_mail cmd.send_mail
Allows send_mail command execution. If enabled, model will be able to sending emails.
Tool: receive_emails cmd.receive_emails
Allows receive_emails command execution. If enabled, model will be able to receive emails from the server.
Tool: get_email_body cmd.get_email_body
Allows get_email_body command execution. If enabled, model will be able to receive message body from the server.
SMTP Host, e.g. smtp.domain.com
SMTP Port (Inbox) smtp_port_inbox
SMTP Port, default: 995
SMTP Port (Outbox) smtp_port_outbox
SMTP Port, default: 465
SMTP User, e.g. user@domain.com
SMTP Password smtp_password
SMTP Password.
Real Time
This plugin automatically adds the current date and time to each system prompt you send.
You have the option to include just the date, just the time, or both.
When enabled, it quietly enhances each system prompt with current time information before sending it to GPT.
Options
If enabled, it appends the current time to the system prompt. Default: True
If enabled, it appends the current date to the system prompt. Default: True
Template to append to the system prompt. The placeholder {time} will be replaced with the
current date and time in real-time. Default: Current time is {time}.
The plugin appends additional system prompts (extra data) from a list to every current system prompt.
You can enhance every system prompt with extra instructions that will be automatically appended to the system prompt.
Options
List of extra prompts - prompts that will be appended to system prompt.
All active extra prompts defined on list will be appended to the system prompt in the order they are listed here.
Voice Control (inline)
The plugin provides voice control command execution within a conversation.
See the Accessibility section for more details.
Creating Your Own Plugins
You can create your own plugin for PyGPT at any time. The plugin can be written in Python and then registered with the application just before launching it. All plugins included with the app are stored in the plugin directory - you can use them as coding examples for your own plugins.
PyGPT can be extended with:
-
custom models
-
custom plugins
-
custom LLMs wrappers
-
custom vector store providers
-
custom data loaders
-
custom audio input providers
-
custom audio output providers
-
custom web search engine providers
See the section Extending PyGPT / Adding a custom plugin for more details.
Functions and commands execution
Tip remember to enable the + Tools checkbox to enable execution of tools and commands from plugins.
From version 2.2.20 PyGPT uses native API function calls by default. You can go back to internal syntax (described below) by switching off option Config -> Settings -> Prompts -> Use native API function calls. Native API function calls are available in Chat, Completion and Assistant modes only (using OpenAI API).
In background, PyGPT uses an internal syntax to define commands and their parameters, which can then be used by the model and executed on the application side or even directly in the system. This syntax looks as follows (example command below):
~###~{"cmd": "send_email", "params": {"quote": "Why don't skeletons fight each other? They don't have the guts!"}}~###~
It is a JSON object wrapped between ~###~. The application extracts the JSON object from such formatted text and executes the appropriate function based on the provided parameters and command name. Many of these types of commands are defined in plugins (e.g., those used for file operations or internet searches). You can also define your own commands using the Custom Commands plugin, or simply by creating your own plugin and adding it to the application.
Tip: The + Tools option checkbox must be enabled to allow the execution of commands from plugins. Disable the option if you do not want to use commands, to prevent additional token usage (as the command execution system prompt consumes additional tokens).
When native API function calls are disabled, a special system prompt responsible for invoking commands is added to the main system prompt if the + Tools option is active.
However, there is an additional possibility to define your own commands and execute them with the help of GPT.
These are functions - defined on the OpenAI API side and described using JSON objects. You can find a complete guide on how to define functions here:
https://platform.openai.com/docs/guides/function-calling
https://cookbook.openai.com/examples/how_to_call_functions_with_chat_models
PyGPT offers compatibility of these functions with commands used in the application. All you need to do is define the appropriate functions using the syntax required by OpenAI, and PyGPT will do the rest, translating such syntax on the fly into its own internal format.
You can define functions for modes: Chat and Assistants.
Note that - in Chat mode, they should be defined in Presets, and for Assistants, in the Assistant settings.
Example of usage:
Create a new Preset, open the Preset edit dialog and add a new function using + Function button with the following content:
Name: send_email
Description: Sends a quote using email
Params (JSON):
{
"type": "object",
"properties": {
"quote": {
"type": "string",
"description": "A generated funny quote"
}
},
"required": [
"quote"
]
}
Then, in the Custom Commands plugin, create a new command with the same name and the same parameters:
Command name: send_email
Instruction/prompt: send mail (don't needed, because it will be called on OpenAI side)
Params list: quote
Command to execute: echo "OK. Email sent: {quote}"
At next, enable the + Tools option and enable the plugin.
Ask GPT in Chat mode:
Create a funny quote and email it
In response you will receive prepared command, like this:
~###~{"cmd": "send_email", "params": {"quote": "Why do we tell actors to 'break a leg?' Because every play has a cast!"}}~###~
After receiving this, PyGPT will execute the system echo command with params given from params field and replacing {quote} placeholder with quote param value.
As a result, response like this will be sent to the model:
[{"request": {"cmd": "send_email"}, "result": "OK. Email sent: Why do we tell actors to 'break a leg?' Because every play has a cast!"}]
In this mode (via Assistants API), it should be done similarly, with the difference that here the functions should be defined in the assistant's settings.
With this flow you can use both forms - OpenAI and PyGPT - to define and execute commands and functions in the application. They will cooperate with each other and you can use them interchangeably.
Tools
PyGPT features several useful tools, including:
- Notepad
- Painter
- Calendar
- Indexer
- Media Player
- Image viewer
- Text editor
- Transcribe audio/video files
- Python Code Interpreter
- HTML/JS Canvas (built-in HTML renderer)

Notepad
The application has a built-in notepad, divided into several tabs. This can be useful for storing information in a convenient way, without the need to open an external text editor. The content of the notepad is automatically saved whenever the content changes.
Painter
Using the Painter tool, you can create quick sketches and submit them to the model for analysis. You can also edit opened from disk or captured from camera images, for example, by adding elements like arrows or outlines to objects. Additionally, you can capture screenshots from the system - the captured image is placed in the drawing tool and attached to the query being sent.
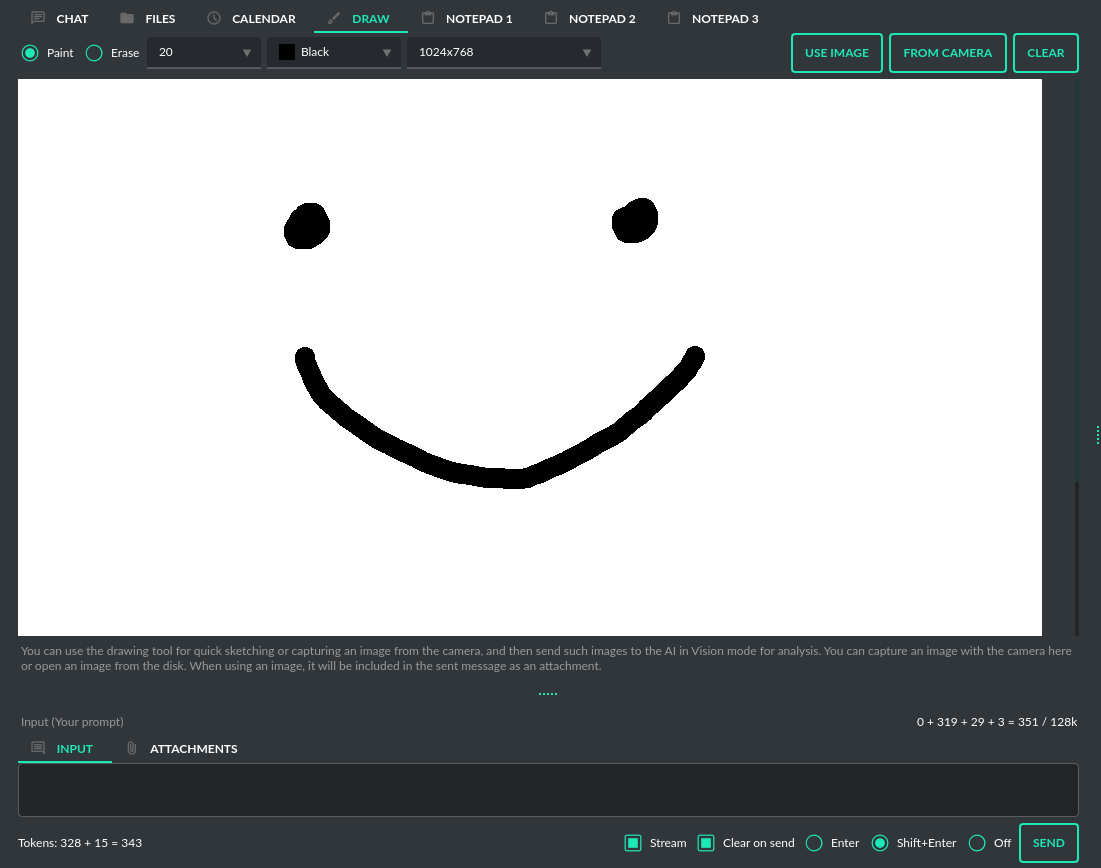
To capture the screenshot just click on the Ask with screenshot option in a tray-icon dropdown:
Calendar
Using the calendar, you can go back to selected conversations from a specific day and add daily notes. After adding a note, it will be marked on the list, and you can change the color of its label by right-clicking and selecting Set label color. By clicking on a particular day of the week, conversations from that day will be displayed.
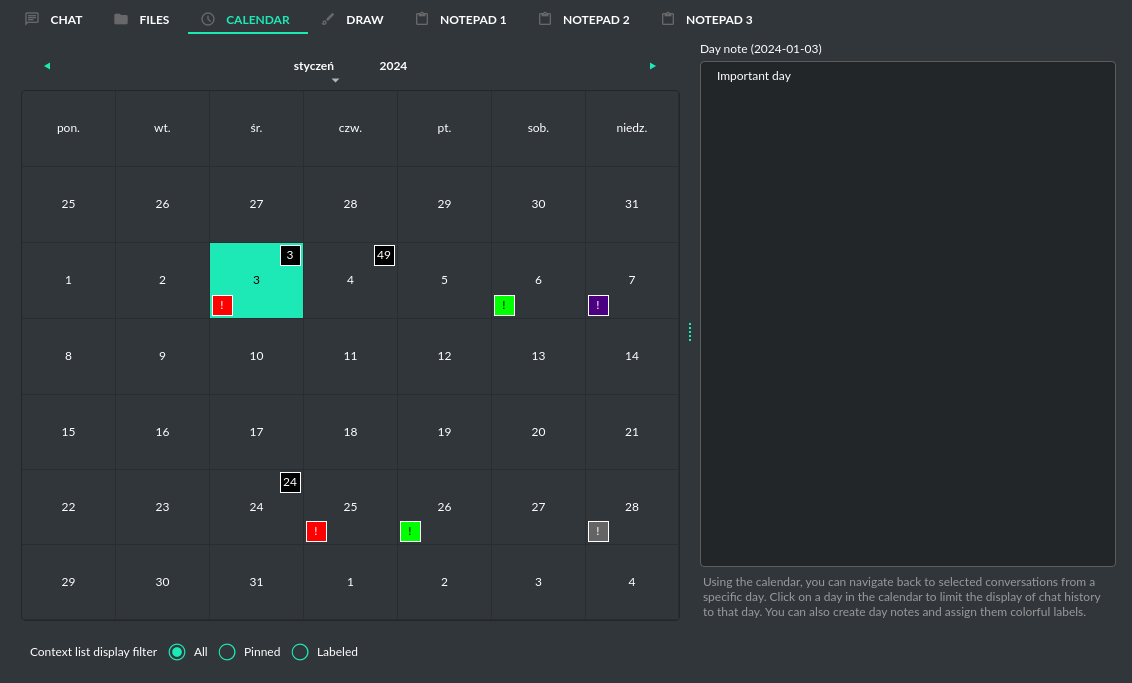
Indexer
This tool allows indexing of local files or directories and external web content to a vector database, which can then be used with the Chat with Files mode. Using this tool, you can manage local indexes and add new data with built-in LlamaIndex integration.
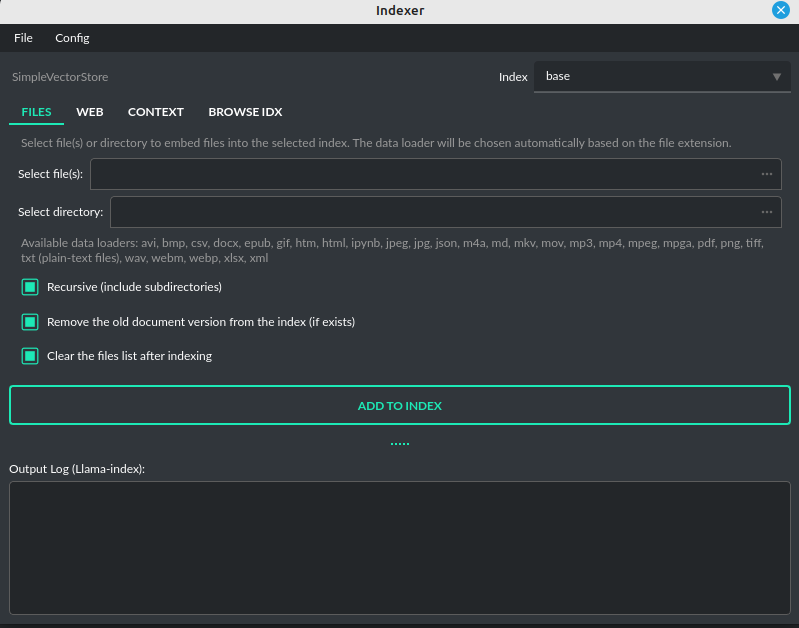
Media Player
A simple video/audio player that allows you to play video files directly from within the app.
Image Viewer
A simple image browser that lets you preview images directly within the app.
Text Editor
A simple text editor that enables you to edit text files directly within the app.
Transcribe Audio/Video Files
An audio transcription tool with which you can prepare a transcript from a video or audio file. It will use a speech recognition plugin to generate the text from the file.
Python Code Interpreter
This tool allows you to run Python code directly from within the app. It is integrated with the Code Interpreter plugin, ensuring that code generated by the model is automatically available from the interpreter. In the plugin settings, you can enable the execution of code in a Docker environment.
HTML/JS Canvas
Allows to render HTML/JS code in HTML Canvas (built-in renderer based on Chromium). To use it, just ask the model to render the HTML/JS code in built-in browser (HTML Canvas). Tool is integrated with the Code Interpreter plugin.
Token usage calculation
Input tokens
The application features a token calculator. It attempts to forecast the number of tokens that
a particular query will consume and displays this estimate in real time. This gives you improved
control over your token usage. The app provides detailed information about the tokens used for the user's prompt,
the system prompt, any additional data, and those used within the context (the memory of previous entries).
Remember that these are only approximate calculations and do not include, for example, the number of tokens consumed by some plugins. You can find the exact number of tokens used on the OpenAI website.

Total tokens
After receiving a response from the model, the application displays the actual total number of tokens used for the query (received from the API).

Accessibility
Since version 2.2.8, PyGPT has added beta support for disabled people and voice control. This may be very useful for blind people.
In the Config / Accessibility menu, you can turn on accessibility features such as:
Using voice control
Voice control can be turned on in two ways: globally, through settings in Config -> Accessibility, and by using the Voice control (inline) plugin. Both options let you use the same voice commands, but they work a bit differently - the global option allows you to run commands outside of a conversation, anywhere, while the plugin option lets you execute commands directly during a conversation – allowing you to interact with the model and execute commands at the same time, within the conversation.
In the plugin (inline) option, you can also turn on a special trigger word that will be needed for content to be recognized as a voice command. You can set this up by going to Plugins -> Settings -> Voice Control (inline):
Magic prefix for voice commands
Tip: When the voice control is enabled via a plugin, simply provide commands while providing the content of the conversation by using the standard Microphone button.
Enabling voice control globally
Turn on the voice control option in Config / Accessibility:
Enable voice control (using microphone)
Once you enable this option, an Voice Control button will appear at the bottom right corner of the window. When you click on this button, the microphone will start listening; clicking it again stops listening and starts recognizing the voice command you said. You can cancel voice recording at any time with the ESC key. You can also set a keyboard shortcut to turn voice recording on/off.
Voice command recognition works based on a model, so you don't have to worry about saying things perfectly.
Here's a list of commands you can ask for by voice:
- Get the current application status
- Exit the application
- Enable audio output
- Disable audio output
- Enable audio input
- Disable audio input
- Add a memo to the calendar
- Clear memos from calendar
- Read the calendar memos
- Enable the camera
- Disable the camera
- Capture image from camera
- Create a new context
- Go to the previous context
- Go to the next context
- Go to the latest context
- Focus on the input
- Send the input
- Clear the input
- Get current conversation info
- Get available commands list
- Stop executing current action
- Clear the attachments
- Read the last conversation entry
- Read the whole conversation
- Rename current context
- Search for a conversation
- Clear the search results
- Send the message to input
- Append message to current input without sending it
- Switch to chat mode
- Switch to chat with files (llama-index) mode
- Switch to the next mode
- Switch to the previous mode
- Switch to the next model
- Switch to the previous model
- Add note to notepad
- Clear notepad contents
- Read current notepad contents
- Switch to the next preset
- Switch to the previous preset
- Switch to the chat tab
- Switch to the calendar tab
- Switch to the draw (painter) tab
- Switch to the files tab
- Switch to the notepad tab
- Switch to the next tab
- Switch to the previous tab
- Start listening for voice input
- Stop listening for voice input
- Toggle listening for voice input
More commands coming soon.
Just ask for an action that matches one of the descriptions above. These descriptions are also known to the model, and relevant commands are assigned to them. When you voice a command that fits one of those patterns, the model will trigger the appropriate action.
For convenience, you can enable a short sound to play when voice recording starts and stops. To do this, turn on the option:
Audio notify microphone listening start/stop
To enable a sound notification when a voice command is recognized and command execution begins, turn on the option:
Audio notify voice command execution
For voice translation of on-screen events and information about completed commands via speech synthesis, you can turn on the option:
Use voice synthesis to describe events on the screen.

Configuration
Settings
The following basic options can be modified directly within the application:
Config -> Settings...

General
-
Minimize to tray on exit: Minimize to tray icon on exit. Tray icon enabled is required for this option to work. Default: False.
-
Render engine: chat output render engine: WebEngine / Chromium - for full HTML/CSS and Legacy (markdown) for legacy, simple markdown CSS output. Default: WebEngine / Chromium.
-
OpenGL hardware acceleration: enables hardware acceleration in WebEngine / Chromium renderer. Default: False.
-
Application environment (os.environ): Additional environment vars to set on application start.
API Keys
-
OpenAI API KEY: Required for the OpenAI API. If you wish to use custom endpoints or local APIs, then you may enter any value here.
-
OpenAI ORGANIZATION KEY: The organization's API key, which is optional for use within the application.
-
API Endpoint: OpenAI API endpoint URL, default: https://api.openai.com/v1.
-
Proxy address: Proxy address to be used for connection; supports HTTP/SOCKS.
-
Google API KEY: Required for the Google API and Gemini models.
-
Anthropic API KEY: Required for the Anthropic API and Claude models.
-
HuggingFace API KEY: Required for the HuggingFace API.
-
OpenAI API version: Azure OpenAI API version, e.g. 2023-07-01-preview
-
Azure OpenAI API endpoint: Azure OpenAI API endpoint, https://.openai.azure.com/
Layout
-
Zoom: Adjusts the zoom in chat window (web render view). WebEngine / Chromium render mode only.
-
Style (chat): Chat style (Blocks, or ChatGPT-like, or ChatGPT-like Wide. WebEngine / Chromium render mode only.
-
Code syntax highlight: Syntax highlight theme in code blocks. WebEngine / Chromium render mode only.
-
Font Size (chat window): Adjusts the font size in the chat window (plain-text) and notepads.
-
Font Size (input): Adjusts the font size in the input window.
-
Font Size (ctx list): Adjusts the font size in contexts list.
-
Font Size (toolbox): Adjusts the font size in toolbox on right.
-
Layout density: Adjusts layout elements density. Default: -1.
-
DPI scaling: Enable/disable DPI scaling. Restart of the application is required for this option to take effect. Default: True.
-
DPI factor: DPI factor. Restart of the application is required for this option to take effect. Default: 1.0.
-
Display tips (help descriptions): Display help tips, Default: True.
-
Store dialog window positions: Enable or disable dialogs positions store/restore, Default: True.
-
Use theme colors in chat window: Use color theme in chat window, Default: True.
Files and attachments
-
Store attachments in the workdir upload directory: Enable to store a local copy of uploaded attachments for future use. Default: True
-
Store images, capture and upload in data directory: Enable to store everything in single data directory. Default: False
-
Directory for file downloads: Subdirectory for downloaded files, e.g. in Assistants mode, inside "data". Default: "download"
-
Verbose mode: Enabled verbose mode when using attachment as additional context.
-
Model for querying index: Model to use for preparing query and querying the index when the RAG option is selected.
-
Model for attachment content summary: Model to use when generating a summary for the content of a file when the Summary option is selected.
-
Use history in RAG query: When enabled, the content of the entire conversation will be used when preparing a query if mode is RAG or Summary.
-
RAG limit: Only if the option Use history in RAG query is enabled. Specify the limit of how many recent entries in the conversation will be used when generating a query for RAG. 0 = no limit.
Context
-
Context Threshold: Sets the number of tokens reserved for the model to respond to the next prompt.
-
Limit of last contexts on list to show (0 = unlimited): Limit of the last contexts on list, default: 0 (unlimited)
-
Show context groups on top of the context list: Display groups on top, default: False
-
Show date separators on the context list: Show date periods, default: True
-
Show date separators in groups on the context list: Show date periods in groups, default: True
-
Show date separators in pinned on the context list: Show date periods in pinned items, default: False
-
Use Context: Toggles the use of conversation context (memory of previous inputs).
-
Store History: Toggles conversation history store.
-
Store Time in History: Chooses whether timestamps are added to the .txt files.
-
Context Auto-summary: Enables automatic generation of titles for contexts, Default: True.
-
Lock incompatible modes: If enabled, the app will create a new context when switched to an incompatible mode within an existing context.
-
Search also in conversation content, not only in titles: When enabled, context search will also consider the content of conversations, not just the titles of conversations.
-
Show LlamaIndex sources: If enabled, sources utilized will be displayed in the response (if available, it will not work in streamed chat).
-
Show code interpreter output: If enabled, output from the code interpreter in the Assistant API will be displayed in real-time (in stream mode), Default: True.
-
Use extra context output: If enabled, plain text output (if available) from command results will be displayed alongside the JSON output, Default: True.
-
Convert lists to paragraphs: If enabled, lists (ul, ol) will be converted to paragraphs (p), Default: True.
-
Model used for auto-summary: Model used for context auto-summary (default: gpt-3.5-turbo-1106).
Models
-
Max Output Tokens: Sets the maximum number of tokens the model can generate for a single response.
-
Max Total Tokens: Sets the maximum token count that the application can send to the model, including the conversation context.
-
RPM limit: Sets the limit of maximum requests per minute (RPM), 0 = no limit.
-
Temperature: Sets the randomness of the conversation. A lower value makes the model's responses more deterministic, while a higher value increases creativity and abstraction.
-
Top-p: A parameter that influences the model's response diversity, similar to temperature. For more information, please check the OpenAI documentation.
-
Frequency Penalty: Decreases the likelihood of repetition in the model's responses.
-
Presence Penalty: Discourages the model from mentioning topics that have already been brought up in the conversation.
Prompts
-
Use native API function calls: Use API function calls to run commands from plugins instead of using command prompts - Chat and Assistants modes ONLY, default: True
-
Command execute: instruction: Prompt for appending command execution instructions. Placeholders: {schema}, {extra}
-
Command execute: extra footer (non-Assistant modes): Extra footer to append after commands JSON schema.
-
Command execute: extra footer (Assistant mode only): PAdditional instructions to separate local commands from the remote environment that is already configured in the Assistants.
-
Context: auto-summary (system prompt): System prompt for context auto-summary.
-
Context: auto-summary (user message): User message for context auto-summary. Placeholders: {input}, {output}
-
Agent: evaluation prompt in loop (LlamaIndex): Prompt used for evaluating the response in Agents (LlamaIndex) mode.
-
Agent: system instruction (Legacy): Prompt to instruct how to handle autonomous mode.
-
Agent: continue (Legacy): Prompt sent to automatically continue the conversation.
-
Agent: continue (always, more steps) (Legacy): Prompt sent to always automatically continue the conversation (more reasoning - "Always continue..." option).
-
Agent: goal update (Legacy): Prompt to instruct how to update current goal status.
-
Experts: Master prompt: Prompt to instruct how to handle experts.
-
DALL-E: image generate: Prompt for generating prompts for DALL-E (if raw-mode is disabled).
Images
-
DALL-E Image size: The resolution of the generated images (DALL-E). Default: 1792x1024.
-
DALL-E Image quality: The image quality of the generated images (DALL-E). Default: standard.
-
Open image dialog after generate: Enable the image dialog to open after an image is generated in Image mode.
-
DALL-E: prompt generation model: Model used for generating prompts for DALL-E (if raw-mode is disabled).
Vision
-
Vision: Camera Input Device: Video capture camera index (index of the camera, default: 0).
-
Vision: Camera capture width (px): Video capture resolution (width).
-
Vision: Camera capture height (px): Video capture resolution (height).
-
Vision: Image capture quality: Video capture image JPEG quality (%).
Audio
-
Audio Input Device: Selects the audio device for Microphone input.
-
Channels: Input channels, default: 1
-
Sampling Rate: Sampling rate, default: 44100
Indexes (LlamaIndex)
-
Indexes: List of created indexes.
-
Vector Store: Vector store to use (vector database provided by LlamaIndex).
-
Vector Store (**kwargs): Keyword arguments for vector store provider (api_key, index_name, etc.).
-
Embeddings provider: Embeddings provider.
-
Embeddings provider (ENV): ENV vars to embeddings provider (API keys, etc.).
-
Embeddings provider (**kwargs): Keyword arguments for embeddings provider (model name, etc.).
-
RPM limit for embeddings API calls: Specify the limit of maximum requests per minute (RPM), 0 = no limit.
-
Recursive directory indexing: Enables recursive directory indexing, default is False.
-
Replace old document versions in the index during re-indexing: If enabled, previous versions of documents will be deleted from the index when the newest versions are indexed, default is True.
-
Excluded file extensions: File extensions to exclude if no data loader for this extension, separated by comma.
-
Force exclude files: If enabled, the exclusion list will be applied even when the data loader for the extension is active. Default: False.
-
Stop indexing on error: If enabled, indexing will stop whenever an error occurs Default: True.
-
Custom metadata to append/replace to indexed documents (file): Define custom metadata key => value fields for specified file extensions, separate extensions by comma.\nAllowed placeholders: {path}, {relative_path} {filename}, {dirname}, {relative_dir} {ext}, {size}, {mtime}, {date}, {date_time}, {time}, {timestamp}. Use * (asterisk) as extension if you want to apply field to all files. Set empty value to remove field with specified key from metadata.
-
Custom metadata to append/replace to indexed documents (web): Define custom metadata key => value fields for specified external data loaders.\nAllowed placeholders: {date}, {date_time}, {time}, {timestamp} + {data loader args}
-
Additional keyword arguments (**kwargs) for data loaders: Additional keyword arguments, such as settings, API keys, for the data loader. These arguments will be passed to the loader; please refer to the LlamaIndex or LlamaHub loaders reference for a list of allowed arguments for the specified data loader.
-
Use local models in Video/Audio and Image (vision) loaders: Enables usage of local models in Video/Audio and Image (vision) loaders. If disabled then API models will be used (GPT-4 Vision and Whisper). Note: local models will work only in Python version (not compiled/Snap). Default: False.
-
Auto-index DB in real time: Enables conversation context auto-indexing in defined modes.
-
ID of index for auto-indexing: Index to use if auto-indexing of conversation context is enabled.
-
Enable auto-index in modes: List of modes with enabled context auto-index, separated by comma.
-
DB (ALL), DB (UPDATE), FILES (ALL): Index the data – batch indexing is available here.
-
Chat mode: chat mode for use in query engine, default: context
Agent and experts
General
Display a tray notification when the goal is achieved.: If enabled, a notification will be displayed after goal achieved / finished run.
LlamaIndex Agents
-
Max steps (per iteration) - Max steps is one iteration before goal achieved
-
Max evaluation steps in loop - Maximum evaluation steps to achieve the final result, set 0 to infinity
-
Append and compare previous evaluation prompt in next evaluation - If enabled, previous improvement prompt will be checked in next eval in loop, default: False
-
Verbose - enables verbose mode.
Legacy
-
Sub-mode for agents: Sub-mode to use in Agent mode (chat, completion, langchain, llama_index, etc.). Default: chat.
-
Sub-mode for experts: Sub-mode to use in Experts mode (chat, completion, langchain, llama_index, etc.). Default: chat.
-
Index to use: Only if sub-mode is llama_index (Chat with Files), choose the index to use in both Agent and Expert modes.
Accessibility
-
Enable voice control (using microphone): enables voice control (using microphone and defined commands).
-
Model: model used for voice command recognition.
-
Use voice synthesis to describe events on the screen.: enables audio description of on-screen events.
-
Use audio output cache: If enabled, all static audio outputs will be cached on the disk instead of being generated every time. Default: True.
-
Audio notify microphone listening start/stop: enables audio "tick" notify when microphone listening started/ended.
-
Audio notify voice command execution: enables audio "tick" notify when voice command is executed.
-
Control shortcut keys: configuration for keyboard shortcuts for a specified actions.
-
Blacklist for voice synthesis events describe (ignored events): list of muted events for 'Use voice synthesis to describe event' option.
-
Voice control actions blacklist: Disable actions in voice control; add actions to the blacklist to prevent execution through voice commands.
Updates
Developer
-
Show debug menu: Enables debug (developer) menu.
-
Log and debug context: Enables logging of context input/output.
-
Log and debug events: Enables logging of event dispatch.
-
Log plugin usage to console: Enables logging of plugin usage to console.
-
Log DALL-E usage to console: Enables logging of DALL-E usage to console.
-
Log LlamaIndex usage to console: Enables logging of LlamaIndex usage to console.
-
Log Assistants usage to console: Enables logging of Assistants API usage to console.
-
Log level: toggle log level (ERROR|WARNING|INFO|DEBUG)
JSON files
The configuration is stored in JSON files for easy manual modification outside of the application.
These configuration files are located in the user's work directory within the following subdirectory:
{HOME_DIR}/.config/pygpt-net/
Manual configuration
You can manually edit the configuration files in this directory (this is your work directory):
{HOME_DIR}/.config/pygpt-net/
assistants.json - stores the list of assistants.attachments.json - stores the list of current attachments.config.json - stores the main configuration settings.models.json - stores models configurations.cache - a directory for audio cache.capture - a directory for captured images from camera and screenshotscss - a directory for CSS stylesheets (user override)history - a directory for context history in .txt format.idx - LlamaIndex indexesimg - a directory for images generated with DALL-E 3 and DALL-E 2, saved as .png files.locale - a directory for locales (user override)data - a directory for data files and files downloaded/generated by GPT.presets - a directory for presets stored as .json files.upload - a directory for local copies of attachments coming from outside the workdirdb.sqlite - a database with contexts, notepads and indexes data recordsapp.log - a file with error and debug log
Setting the Working Directory Using Command Line Arguments
To set the current working directory using a command-line argument, use:
python3 ./run.py --workdir="/path/to/workdir"
or, for the binary version:
pygpt.exe --workdir="/path/to/workdir"
Translations / Locale
Locale .ini files are located in the app directory:
./data/locale
This directory is automatically scanned when the application launches. To add a new translation,
create and save the file with the appropriate name, for example:
locale.es.ini
This will add Spanish as a selectable language in the application's language menu.
Overwriting CSS and locales with Your Own Files:
You can also overwrite files in the locale and css app directories with your own files in the user directory.
This allows you to overwrite language files or CSS styles in a very simple way - by just creating files in your working directory.
{HOME_DIR}/.config/pygpt-net/
locale - a directory for locales in .ini format.css - a directory for CSS styles in .css format.
Adding Your Own Fonts
You can add your own fonts and use them in CSS files. To load your own fonts, you should place them in the %workdir%/fonts directory. Supported font types include: otf, ttf.
You can see the list of loaded fonts in Debug / Config.
Example:
%workdir%
|_css
|_data
|_fonts
|_MyFont
|_MyFont-Regular.ttf
|_MyFont-Bold.ttf
|...
pre {{
font-family: 'MyFont';
}}
Data Loaders
Configuring data loaders
In the Settings -> LlamaIndex -> Data loaders section you can define the additional keyword arguments to pass into data loader instance.
In most cases, an internal LlamaIndex loaders are used internally.
You can check these base loaders e.g. here:
File: https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/readers/llama-index-readers-file/llama_index/readers/file
Web: https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/readers/llama-index-readers-web
Tip: to index an external data or data from the Web just ask for it, by using Web Search plugin, e.g. you can ask the model with Please index the youtube video: URL to video, etc. Data loader for a specified content will be choosen automatically.
Allowed additional keyword arguments for built-in data loaders (files):
CSV Files (file_csv)
concat_rows - bool, default: Trueencoding - str, default: utf-8
HTML Files (file_html)
tag - str, default: sectionignore_no_id - bool, default: False
Image (vision) (file_image_vision)
This loader can operate in two modes: local model and API.
If the local mode is enabled, then the local model will be used. The local mode requires a Python/PyPi version of the application and is not available in the compiled or Snap versions.
If the API mode (default) is selected, then the OpenAI API and the standard vision model will be used.
Note: Usage of API mode consumes additional tokens in OpenAI API (for GPT-4 Vision model)!
Local mode requires torch, transformers, sentencepiece and Pillow to be installed and uses the Salesforce/blip2-opt-2.7b model to describing images.
keep_image - bool, default: Falselocal_prompt - str, default: Question: describe what you see in this image. Answer:api_prompt - str, default: Describe what you see in this image - Prompt to use in APIapi_model - str, default: gpt-4-vision-preview - Model to use in APIapi_tokens - int, default: 1000 - Max output tokens in API
IPYNB Notebook files (file_ipynb)
parser_config - dict, default: Noneconcatenate - bool, default: False
Markdown files (file_md)
remove_hyperlinks - bool, default: Trueremove_images - bool, default: True
PDF documents (file_pdf)
return_full_document - bool, default: False
Video/Audio (file_video_audio)
This loader can operate in two modes: local model and API.
If the local mode is enabled, then the local Whisper model will be used. The local mode requires a Python/PyPi version of the application and is not available in the compiled or Snap versions.
If the API mode (default) is selected, then the currently selected provider in Audio Input plugin will be used. If the OpenAI Whisper is chosen then the OpenAI API and the API Whisper model will be used.
Note: Usage of Whisper via API consumes additional tokens in OpenAI API (for Whisper model)!
Local mode requires torch and openai-whisper to be installed and uses the Whisper model locally to transcribing video and audio.
XML files (file_xml)
tree_level_split - int, default: 0
Allowed additional keyword arguments for built-in data loaders (Web and external content):
Bitbucket (web_bitbucket)
username - str, default: Noneapi_key - str, default: Noneextensions_to_skip - list, default: []
ChatGPT Retrieval (web_chatgpt_retrieval)
endpoint_url - str, default: Nonebearer_token - str, default: Noneretries - int, default: Nonebatch_size - int, default: 100
Google Calendar (web_google_calendar)
credentials_path - str, default: credentials.jsontoken_path - str, default: token.json
Google Docs (web_google_docs)
credentials_path - str, default: credentials.jsontoken_path - str, default: token.json
Google Drive (web_google_drive)
credentials_path - str, default: credentials.jsontoken_path - str, default: token.jsonpydrive_creds_path - str, default: creds.txtclient_config - dict, default: {}
Google Gmail (web_google_gmail)
credentials_path - str, default: credentials.jsontoken_path - str, default: token.jsonuse_iterative_parser - bool, default: Falsemax_results - int, default: 10results_per_page - int, default: None
Google Keep (web_google_keep)
credentials_path - str, default: keep_credentials.json
Google Sheets (web_google_sheets)
credentials_path - str, default: credentials.jsontoken_path - str, default: token.json
GitHub Issues (web_github_issues)
token - str, default: Noneverbose - bool, default: False
GitHub Repository (web_github_repository)
token - str, default: Noneverbose - bool, default: Falseconcurrent_requests - int, default: 5timeout - int, default: 5retries - int, default: 0filter_dirs_include - list, default: Nonefilter_dirs_exclude - list, default: Nonefilter_file_ext_include - list, default: Nonefilter_file_ext_exclude - list, default: None
Microsoft OneDrive (web_microsoft_onedrive)
client_id - str, default: Noneclient_secret - str, default: Nonetenant_id - str, default: consumers
Sitemap (XML) (web_sitemap)
html_to_text - bool, default: Falselimit - int, default: 10
SQL Database (web_database)
You can provide a single URI in the form of: {scheme}://{user}:{password}@{host}:{port}/{dbname}, or you can provide each field manually:
scheme - str, default: Nonehost - str, default: Noneport - str, default: Noneuser - str, default: Nonepassword - str, default: Nonedbname - str, default: None
Twitter/X posts (web_twitter)
bearer_token - str, default: Nonenum_tweets - int, default: 100
Vector stores
Available vector stores (provided by LlamaIndex):
- ChromaVectorStore
- ElasticsearchStore
- PinecodeVectorStore
- RedisVectorStore
- SimpleVectorStore
You can configure selected vector store by providing config options like api_key, etc. in Settings -> LlamaIndex window.
Arguments provided here (on list: Vector Store (**kwargs) in Advanced settings will be passed to selected vector store provider. You can check keyword arguments needed by selected provider on LlamaIndex API reference page:
https://docs.llamaindex.ai/en/stable/api_reference/storage/vector_store.html
Which keyword arguments are passed to providers?
For ChromaVectorStore and SimpleVectorStore all arguments are set by PyGPT and passed internally (you do not need to configure anything).
For other providers you can provide these arguments:
ElasticsearchStore
Keyword arguments for ElasticsearchStore(**kwargs):
index_name (default: current index ID, already set, not required)- any other keyword arguments provided on list
PinecodeVectorStore
Keyword arguments for Pinecone(**kwargs):
api_key- index_name (default: current index ID, already set, not required)
RedisVectorStore
Keyword arguments for RedisVectorStore(**kwargs):
index_name (default: current index ID, already set, not required)- any other keyword arguments provided on list
You can extend list of available providers by creating custom provider and registering it on app launch.
By default, you are using chat-based mode when using Chat with Files.
If you want to only query index (without chat) you can enable Query index only (without chat) option.
Adding custom vector stores and data loaders
You can create a custom vector store provider or data loader for your data and develop a custom launcher for the application.
See the section Extending PyGPT / Adding a custom Vector Store provider for more details.
Updates
Updating PyGPT
PyGPT comes with an integrated update notification system. When a new version with additional features is released, you'll receive an alert within the app.
To get the new version, simply download it and start using it in place of the old one. All your custom settings like configuration, presets, indexes, and past conversations will be kept and ready to use right away in the new version.
Debugging and Logging
In Settings -> Developer dialog, you can enable the Show debug menu option to turn on the debugging menu. The menu allows you to inspect the status of application elements. In the debugging menu, there is a Logger option that opens a log window. In the window, the program's operation is displayed in real-time.
Logging levels:
By default, all errors and exceptions are logged to the file:
{HOME_DIR}/.config/pygpt-net/app.log
To increase the logging level (ERROR level is default), run the application with --debug argument:
python3 run.py --debug=1
or
python3 run.py --debug=2
The value 1 enables the INFOlogging level.
The value 2 enables the DEBUG logging level (most information).
Compatibility (legacy) mode
If you have a problems with WebEngine / Chromium renderer you can force the legacy mode by launching the app with command line arguments:
python3 run.py --legacy=1
and to force disable OpenGL hardware acceleration:
python3 run.py --disable-gpu=1
You can also manualy enable legacy mode by editing config file - open the %WORKDIR%/config.json config file in editor and set the following options:
"render.engine": "legacy",
"render.open_gl": false,
Extending PyGPT
Quick start
You can create your own extensions for PyGPT at any time.
PyGPT can be extended with:
-
custom models
-
custom plugins
-
custom LLM wrappers
-
custom vector store providers
-
custom data loaders
-
custom audio input providers
-
custom audio output providers
-
custom web search engine providers
Examples (tutorial files)
See the examples directory in this repository with examples of custom launcher, plugin, vector store, LLM (LangChain and LlamaIndex) provider and data loader:
-
examples/custom_launcher.py
-
examples/example_audio_input.py
-
examples/example_audio_output.py
-
examples/example_data_loader.py
-
examples/example_llm.py
-
examples/example_plugin.py
-
examples/example_vector_store.py
-
examples/example_web_search.py
These example files can be used as a starting point for creating your own extensions for PyGPT.
Extending PyGPT with custom plugins, LLMs wrappers and vector stores:
-
You can pass custom plugin instances, LLMs wrappers and vector store providers to the launcher.
-
This is useful if you want to extend PyGPT with your own plugins, vectors storage and LLMs.
To register custom plugins:
- Pass a list with the plugin instances as
plugins keyword argument.
To register custom LLMs wrappers:
- Pass a list with the LLMs wrappers instances as
llms keyword argument.
To register custom vector store providers:
- Pass a list with the vector store provider instances as
vector_stores keyword argument.
To register custom data loaders:
- Pass a list with the data loader instances as
loaders keyword argument.
To register custom audio input providers:
- Pass a list with the audio input provider instances as
audio_input keyword argument.
To register custom audio output providers:
- Pass a list with the audio output provider instances as
audio_output keyword argument.
To register custom web providers:
- Pass a list with the web provider instances as
web keyword argument.
Adding a custom model
To add a new model using the OpenAI API, LangChain, or LlamaIndex wrapper, use the editor in Config -> Models or manually edit the models.json file by inserting the model's configuration details. If you are adding a model via LangChain or LlamaIndex, ensure to include the model's name, its supported modes (either chat, completion, or both), the LLM provider (such as OpenAI or HuggingFace), and, if you are using an external API-based model, an optional API KEY along with any other necessary environment settings.
Example of models configuration - %WORKDIR%/models.json:
"gpt-3.5-turbo": {
"id": "gpt-3.5-turbo",
"name": "gpt-3.5-turbo",
"mode": [
"chat",
"assistant",
"langchain",
"llama_index"
],
"langchain": {
"provider": "openai",
"mode": [
"chat"
],
"args": [
{
"name": "model_name",
"value": "gpt-3.5-turbo",
"type": "str"
}
],
"env": [
{
"name": "OPENAI_API_KEY",
"value": "{api_key}"
}
]
},
"llama_index": {
"provider": "openai",
"mode": [
"chat"
],
"args": [
{
"name": "model",
"value": "gpt-3.5-turbo",
"type": "str"
}
],
"env": [
{
"name": "OPENAI_API_KEY",
"value": "{api_key}"
}
]
},
"ctx": 4096,
"tokens": 4096,
"default": false
},
There is built-in support for those LLM providers:
- `OpenAI` (openai)
- `Azure OpenAI` (azure_openai)
- `Google` (google)
- `HuggingFace API` (huggingface_api)
- `Anthropic` (anthropic)
- `Ollama` (ollama)
Tip: {api_key} in models.json is a placeholder for the main OpenAI API KEY from the settings. It will be replaced by the configured key value.
Adding a custom plugin
Creating Your Own Plugin
You can create your own plugin for PyGPT. The plugin can be written in Python and then registered with the application just before launching it. All plugins included with the app are stored in the plugin directory - you can use them as coding examples for your own plugins.
Examples (tutorial files)
See the example plugin in this examples directory:
examples/example_plugin.py
These example file can be used as a starting point for creating your own plugin for PyGPT.
To register a custom plugin:
Example of a custom launcher:
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(),
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
Handling events
In the plugin, you can receive and modify dispatched events.
To do this, create a method named handle(self, event, *args, **kwargs) and handle the received events like here:
from pygpt_net.core.events import Event
def handle(self, event: Event, *args, **kwargs):
"""
Handle dispatched events
:param event: event object
"""
name = event.name
data = event.data
ctx = event.ctx
if name == Event.INPUT_BEFORE:
self.some_method(data['value'])
elif name == Event.CTX_BEGIN:
self.some_other_method(ctx)
else:
List of Events
Event names are defined in Event class in pygpt_net.core.events.
Syntax: event name - triggered on, event data (data type):
-
AI_NAME - when preparing an AI name, data['value'] (string, name of the AI assistant)
-
AGENT_PROMPT - on agent prompt in eval mode, data['value'] (string, prompt)
-
AUDIO_INPUT_RECORD_START - start audio input recording
-
AUDIO_INPUT_RECORD_STOP - stop audio input recording
-
AUDIO_INPUT_RECORD_TOGGLE - toggle audio input recording
-
AUDIO_INPUT_TRANSCRIBE - on audio file transcribe, data['path'] (string, path to audio file)
-
AUDIO_INPUT_STOP - force stop audio input
-
AUDIO_INPUT_TOGGLE - when speech input is enabled or disabled, data['value'] (bool, True/False)
-
AUDIO_OUTPUT_STOP - force stop audio output
-
AUDIO_OUTPUT_TOGGLE - when speech output is enabled or disabled, data['value'] (bool, True/False)
-
AUDIO_READ_TEXT - on text read using speech synthesis, data['text'] (str, text to read)
-
CMD_EXECUTE - when a command is executed, data['commands'] (list, commands and arguments)
-
CMD_INLINE - when an inline command is executed, data['commands'] (list, commands and arguments)
-
CMD_SYNTAX - when appending syntax for commands, data['prompt'], data['syntax'] (string, list, prompt and list with commands usage syntax)
-
CMD_SYNTAX_INLINE - when appending syntax for commands (inline mode), data['prompt'], data['syntax'] (string, list, prompt and list with commands usage syntax)
-
CTX_AFTER - after the context item is sent, ctx
-
CTX_BEFORE - before the context item is sent, ctx
-
CTX_BEGIN - when context item create, ctx
-
CTX_END - when context item handling is finished, ctx
-
CTX_SELECT - when context is selected on list, data['value'] (int, ctx meta ID)
-
DISABLE - when the plugin is disabled, data['value'] (string, plugin ID)
-
ENABLE - when the plugin is enabled, data['value'] (string, plugin ID)
-
FORCE_STOP - on force stop plugins
-
INPUT_BEFORE - upon receiving input from the textarea, data['value'] (string, text to be sent)
-
MODE_BEFORE - before the mode is selected data['value'], data['prompt'] (string, string, mode ID)
-
MODE_SELECT - on mode select data['value'] (string, mode ID)
-
MODEL_BEFORE - before the model is selected data['value'] (string, model ID)
-
MODEL_SELECT - on model select data['value'] (string, model ID)
-
PLUGIN_SETTINGS_CHANGED - on plugin settings update (saving settings)
-
PLUGIN_OPTION_GET - on request for plugin option value data['name'], data['value'] (string, any, name of requested option, value)
-
POST_PROMPT - after preparing a system prompt, data['value'] (string, system prompt)
-
POST_PROMPT_ASYNC - after preparing a system prompt, just before request in async thread, data['value'] (string, system prompt)
-
POST_PROMPT_END - after preparing a system prompt, just before request in async thread, at the very end data['value'] (string, system prompt)
-
PRE_PROMPT - before preparing a system prompt, data['value'] (string, system prompt)
-
SYSTEM_PROMPT - when preparing a system prompt, data['value'] (string, system prompt)
-
TOOL_OUTPUT_RENDER - when rendering extra content from tools from plugins, data['content'] (string, content)
-
UI_ATTACHMENTS - when the attachment upload elements are rendered, data['value'] (bool, show True/False)
-
UI_VISION - when the vision elements are rendered, data['value'] (bool, show True/False)
-
USER_NAME - when preparing a user's name, data['value'] (string, name of the user)
-
USER_SEND - just before the input text is sent, data['value'] (string, input text)
You can stop the propagation of a received event at any time by setting stop to True:
event.stop = True
Events flow can be debugged by enabling the option Config -> Settings -> Developer -> Log and debug events.
Adding a custom LLM provider
Handling LLMs with LangChain and LlamaIndex is implemented through separated wrappers. This allows for the addition of support for any provider and model available via LangChain or LlamaIndex. All built-in wrappers for the models and its providers are placed in the pygpt_net.provider.llms.
These wrappers are loaded into the application during startup using launcher.add_llm() method:
from pygpt_net.provider.llms.openai import OpenAILLM
from pygpt_net.provider.llms.azure_openai import AzureOpenAILLM
from pygpt_net.provider.llms.anthropic import AnthropicLLM
from pygpt_net.provider.llms.hugging_face import HuggingFaceLLM
from pygpt_net.provider.llms.ollama import OllamaLLM
from pygpt_net.provider.llms.google import GoogleLLM
def run(**kwargs):
"""Runs the app."""
launcher = Launcher()
launcher.init()
...
launcher.add_llm(OpenAILLM())
launcher.add_llm(AzureOpenAILLM())
launcher.add_llm(AnthropicLLM())
launcher.add_llm(HuggingFaceLLM())
launcher.add_llm(OllamaLLM())
launcher.add_llm(GoogleLLM())
launcher.run()
To add support for providers not included by default, you can create your own wrapper that returns a custom model to the application and then pass this custom wrapper to the launcher.
Extending PyGPT with custom plugins and LLM wrappers is straightforward:
- Pass instances of custom plugins and LLM wrappers directly to the launcher.
To register custom LLM wrappers:
- Provide a list of LLM wrapper instances as
llms keyword argument.
Example:
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = []
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
Examples (tutorial files)
See the examples directory in this repository with examples of custom launcher, plugin, vector store, LLM (LangChain and LlamaIndex) provider and data loader:
-
examples/custom_launcher.py
-
examples/example_audio_input.py
-
examples/example_audio_output.py
-
examples/example_data_loader.py
-
examples/example_llm.py <-- use it as an example
-
examples/example_plugin.py
-
examples/example_vector_store.py
-
examples/example_web_search.py
These example files can be used as a starting point for creating your own extensions for PyGPT.
To integrate your own model or provider into PyGPT, you can also reference the classes located in the pygpt_net.provider.llms. These samples can act as an more complex example for your custom class. Ensure that your custom wrapper class includes two essential methods: chat and completion. These methods should return the respective objects required for the model to operate in chat and completion modes.
Every single LLM provider (wrapper) inherits from BaseLLM class and can provide 3 components: provider for LangChain, provider for LlamaIndex, and provider for Embeddings.
Adding a custom vector store provider
You can create a custom vector store provider or data loader for your data and develop a custom launcher for the application. To register your custom vector store provider or data loader, simply register it by passing the vector store provider instance to vector_stores keyword argument and loader instance in the loaders keyword argument:
from pygpt_net.provider.vector_stores.chroma import ChromaProvider
from pygpt_net.provider.vector_stores.elasticsearch import ElasticsearchProvider
from pygpt_net.provider.vector_stores.pinecode import PinecodeProvider
from pygpt_net.provider.vector_stores.redis import RedisProvider
from pygpt_net.provider.vector_stores.simple import SimpleProvider
def run(**kwargs):
launcher.add_vector_store(ChromaProvider())
launcher.add_vector_store(ElasticsearchProvider())
launcher.add_vector_store(PinecodeProvider())
launcher.add_vector_store(RedisProvider())
launcher.add_vector_store(SimpleProvider())
vector_stores = kwargs.get('vector_stores', None)
if isinstance(vector_stores, list):
for store in vector_stores:
launcher.add_vector_store(store)
To register your custom vector store provider just register it by passing provider instance in vector_stores keyword argument:
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(),
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
)
The vector store provider must be an instance of pygpt_net.provider.vector_stores.base.BaseStore.
You can review the code of the built-in providers in pygpt_net.provider.vector_stores and use them as examples when creating a custom provider.
Adding a custom data loader
from pygpt_net.app import run
from plugins import CustomPlugin, OtherCustomPlugin
from llms import CustomLLM
from vector_stores import CustomVectorStore
from loaders import CustomLoader
plugins = [
CustomPlugin(),
OtherCustomPlugin(),
]
llms = [
CustomLLM(),
]
vector_stores = [
CustomVectorStore(),
]
loaders = [
CustomLoader(),
]
run(
plugins=plugins,
llms=llms,
vector_stores=vector_stores,
loaders=loaders
)
The data loader must be an instance of pygpt_net.provider.loaders.base.BaseLoader.
You can review the code of the built-in loaders in pygpt_net.provider.loaders and use them as examples when creating a custom loader.
DISCLAIMER
This application is not officially associated with OpenAI. The author shall not be held liable for any damages
resulting from the use of this application. It is provided "as is," without any form of warranty.
Users are reminded to be mindful of token usage - always verify the number of tokens utilized by the model on
the OpenAI website and engage with the application responsibly. Activating plugins, such as Web Search,
may consume additional tokens that are not displayed in the main window.
Always monitor your actual token usage on the OpenAI website.
CHANGELOG
Recent changes:
2.5.10 (2025-03-06)
- Added a new model: Claude 3.7 Sonnet.
- Fixed the context switch issue when the column changed and the tab is not a chat tab.
- LlamaIndex upgraded to 0.12.22.
- LlamaIndex LLMs upgraded to recent versions.
2.5.9 (2025-03-05)
- Improved formatting of HTML code in the output.
- Disabled automatic indentation parsing as code blocks.
- Disabled automatic scrolling of the notepad when opening a tab.
2.5.8 (2025-03-02)
- Added a new mode: Research (Perplexity) powered by: https://perplexity.ai - beta.
- Added Perplexity models: sonar, sonar-pro, sonar-deep-research, sonar-reasoning, sonar-reasoning-pro, r1-1776.
- Added a new OpenAI model: gpt-4.5-preview.
2.5.7 (2025-02-26)
- Stream mode has been enabled in o1 models.
- CSS styling for tags (reasoning models) has been added.
- The search input has been moved to the top.
- The ChatGPT-based style is now set as default.
- Fix: Display of max tokens in models with a context window greater than 128k.
2.5.6 (2025-02-03)
- Fix: disabled index initialization if embedding provider is OpenAI and no API KEY is provided.
- Fix: embedding provider initialization on empty index.
2.5.5 (2025-02-02)
- Fix: system prompt apply.
- Added calendar live update on tab change.
- Added API Key monit at launch displayed only once.
2.5.4 (2025-02-02)
- Added new models:
o3-mini and gpt-4o-mini-audio-preview.
- Enabled tool calls in Chat with Audio mode.
- Added a check to verify if Ollama is running and if the model is available.
2.5.3 (2025-02-01)
- Fix: Snap permission denied bug.
- Fix: column focus on tab change.
- Datetime separators in groups moved to right side.
2.5.2 (2025-02-01)
- Fix: spinner update after inline image generation.
- Added Ollama suffix to Ollama-models in models list.
2.5.1 (2025-02-01)
- PySide6 upgraded to 6.6.2.
- Disabled Transformers startup warnings.
2.5.0 (2025-01-31)
- Added provider for DeepSeek (in Chat with Files mode, beta).
- Added new models: OpenAI o1, Llama 3.3, DeepSeek V3 and R1 (API + local, with Ollama).
- Added tool calls for OpenAI o1.
- Added native vision for OpenAI o1.
- Fix: tool calls in Ollama provider.
- Fix: error handling in stream mode.
- Fix: added check for active plugin tools before tool call.
Credits and links
Official website: https://pygpt.net
Documentation: https://pygpt.readthedocs.io
Support and donate: https://pygpt.net/#donate
GitHub: https://github.com/szczyglis-dev/py-gpt
Discord: https://pygpt.net/discord
Snap Store: https://snapcraft.io/pygpt
PyPI: https://pypi.org/project/pygpt-net
Author: Marcin Szczygliński (Poland, EU)
Contact: info@pygpt.net
License: MIT License
Special thanks
GitHub's community:
Third-party libraries
Full list of external libraries used in this project is located in the requirements.txt file in the main folder of the repository.
All used SVG icons are from Material Design Icons provided by Google:
https://github.com/google/material-design-icons
https://fonts.google.com/icons
Monaspace fonts provided by GitHub: https://github.com/githubnext/monaspace
Code of the LlamaIndex offline loaders integrated into app is taken from LlamaHub: https://llamahub.ai
Awesome ChatGPT Prompts (used in templates): https://github.com/f/awesome-chatgpt-prompts/
Code syntax highlight powered by: https://highlightjs.org
LaTeX support by: https://katex.org and https://github.com/mitya57/python-markdown-math




{kind=link}