
Product
Introducing Data Exports
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
By Ola Adekola - Apr 23, 2026
pysparta
Advanced tools
Library to help ETL using Pyspark.
Sparta is a simple library to help you work on ETL builds using PySpark.
Install the latest version with pip install pysparta
This is a module with functions for extracting and reading data.
Example
from sparta.extract import read_with_schema
schema = 'epidemiological_week LONG, date DATE, order_for_place INT, state STRING, city STRING, city_ibge_code LONG, place_type STRING, last_available_confirmed INT'
path = '/content/sample_data/covid19-e0534be4ad17411e81305aba2d9194d9.csv'
df = read_with_schema(path, schema, {'header': 'true'}, 'csv')
This is a module with data transformation functions
Example
from sparta.transformation import drop_duplicates
cols = ['longitude','latitude']
df = drop_duplicates(df, 'population', cols)
This is a module with load and write functions.
Example
from sparta.load import create_hive_table
create_hive_table(df, "table_name", 5, "col1", "col2", "col3")
This is a module with several functions that can help in ETL work.
Example
from sparta.secret import get_secret_aws
get_secret_aws('Nome_Secret', 'sa-east-1')
Sparta currently supports PySpark 3.0+ and Python 3.7+.
FAQs
Library to help ETL using pyspark
We found that pysparta demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
Research
/Security News
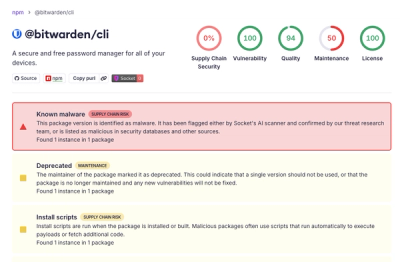
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.

Research
/Security News
Docker and Socket have uncovered malicious Checkmarx KICS images and suspicious code extension releases in a broader supply chain compromise.