
Product
Introducing Reachability for PHP
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.
By Benjamin Barslev - Apr 24, 2026
qpd
Advanced tools
QPD let you run the same SQL (SELECT for now) statements on different computing frameworks with pandas-like interfaces.
Currently, it support Pandas, Dask and Ray
(via Modin on Ray).
QPD directly translates SQL into pandas-like operations to run on the backend computing frameworks, so it can be significantly
faster than some other approaches, for example, to dump pandas dataframes into SQLite, run SQL and convert the result back into
a pandas dataframe. However, the top priorities of QPD are correctness and consistency. It ensures the results of
implemented SQL features following SQL convention, and it ensures consistent behavior regardless of backend computing frameworks.
A typical case is groupby().agg(). In pandas or pandas like frameworks, if any of the group keys is null, the default
behavior is to drop that group, however, in SQL they are not dropped. QPD follows the SQL way.
QPD syntax is a subset of the intersection of Spark SQL and SQLite. The correctness and consistency are extensively tested against SQLite. Practically, Spark SQL and SQLite are highly consistent on both syntax and behavior. So, in other words, QPD enables you to run common SQLs and get the same result on Pandas, SQLite, Spark, Dask, Ray and other backends that QPD will support in the future.
SQL is one of the most important data processing languages. It is very scale agnostic, and one of the major goals of the Fugue project is to enrich SQL and make SQL platform agnostic. QPD, as a subproject of Fugue, focuses on running SQL on pandas-like frameworks, it is an essential component to achieve the ultimate goal.
QPD can be installed from PyPI:
pip install qpd # install qpd + pandas
If you want to use Ray or Dask as the backend, you will need to install QPD with one of the targets:
pip install qpd[dask] # install qpd + dask[dataframe]
pip install qpd[ray] # install qpd + ray
pip install qpd[all] # install all dependencies above
from qpd_pandas import run_sql_on_pandas
import pandas as pd
df = pd.DataFrame([[0,1],[2,3],[0,5]], columns=["a","b"])
res = run_sql_on_pandas("SELECT a, SUM(b) AS b, COUNT(*) AS c FROM df GROUP BY a", {"df": df})
print(res)
Please read this to learn the best practice for initializing dask.
from qpd_dask import run_sql_on_dask
import dask.dataframe as pd
import pandas
df = pd.from_pandas(pandas.DataFrame([[0,1],[2,3],[0,5]], columns=["a","b"]))
res = run_sql_on_dask("SELECT a, SUM(b) AS b, COUNT(*) AS c FROM df GROUP BY a", {"df": df})
print(res.compute()) # dask dataframe is lazy, you need to call compute
Please read this to learn the best practice for initializing ray. And read this for initializing modin + ray.
Please don't use dask as modin backend if you want to use QPD, it's not tested
import ray
ray.init()
from qpd_ray import run_sql_on_ray
import modin.pandas as pd
df = pd.DataFrame([[0,1],[2,3],[0,5]], columns=["a","b"])
res = run_sql_on_ray("SELECT a, SUM(b) AS b, COUNT(*) AS c FROM df GROUP BY a", {"df": df})
print(res)
By default, QPD requires users to use upper cased keywords, otherwise syntax errors will be raised.
However if you really don't like this behavior, you can turn it off, the parameter is ignore_case,
here is an example:
from qpd_pandas import run_sql_on_pandas
import pandas as pd
df = pd.DataFrame([[0,1],[2,3],[0,5]], columns=["a","b"])
res = run_sql_on_pandas(
"select a, sum(b) as b, count(*) as c from df group by a",
{"df": df}, ignore_case=True)
print(res)
No, that will not happen. QPD is using Spark SQL syntax file. Spark SQL is highly optimized. If we create a Koalas backend, correctness and consistency can be guaranteed, but there will be no performance advantage. So for Spark, please use Spark SQL. If you use Fugue SQL on Spark backend, it will also directly use Spark to run the SQL statements. We don't see the value to make QPD run on Spark.
FROM, SELECT 1 AS a, 'b' AS bFAQs
Query Pandas Using SQL
We found that qpd demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.

Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
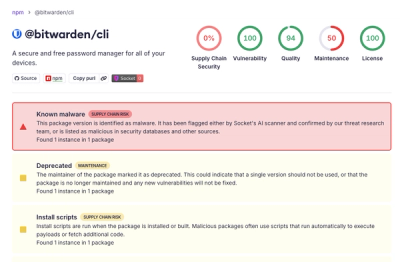
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.