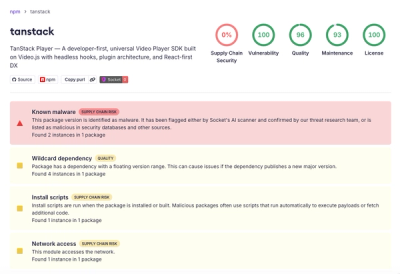
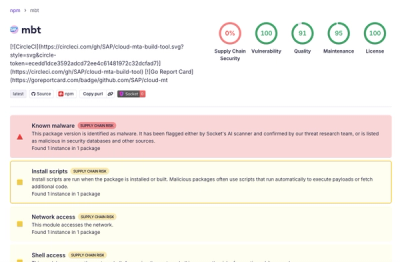
RavenPack API - Python client
A Python library to consume the
RavenPack <https://www.ravenpack.com>__ API.
API documentation. <https://www.ravenpack.com/support/>__
Installation
::
pip install ravenpackapi
About
The Python client helps managing the API calls to the RavenPack dataset
server in a Pythonic way, here are some examples of usage, you can find
more in the tests.
Usage
In order to be able to use the RavenPack API you will need an API KEY.
If you don't already have one please contact your customer support <mailto:sales@ravenpack.com>__ representative.
To begin using the API you will need to instantiate an API object that
will deal with the API calls.
Using your RavenPack API KEY, you can either set the RP_API_KEY
environment variable or set it in your code:
.. code:: python
from ravenpackapi import RPApi
api = RPApi(api_key="YOUR_API_KEY")
Creating a new dataset
To create a dataset you can call the ``create_dataset`` method of the
API with a Dataset instance.
.. code:: python
from ravenpackapi import Dataset
ds = api.create_dataset(
Dataset(
name="New Dataset",
filters={
"relevance": {
"$gte": 90
}
},
)
)
print("Dataset created", ds)
Getting data from the datasets
In the API wrapper, there are several models that maybe used for
interacting with data.
Here is how you may get a dataset definition for a pre-existing dataset
.. code:: python
# Get the dataset description from the server, here we use 'us30'
# one of RavenPack public datasets with the top30 companies in the US
ds = api.get_dataset(dataset_id='us30')
Downloads: json
^^^^^^^^^^^^^^^
The json endpoint is useful for asking data synchronously, optimized for
small requests, if you need to download big data chunks you may want to
use the asynchronous datafile endpoint instead.
.. code:: python
data = ds.json(
start_date='2018-01-05 18:00:00',
end_date='2018-01-05 18:01:00',
)
for record in data:
print(record)
Json queries are limited to
- granular datasets: 10,000 records
- indicator datasets: 500 entities, timerange 1 year, lookback window 1
year
Downloads: datafile
^^^^^^^^^^^^^^^^^^^
For bigger requests the datafile endpoint can be used to prepare a
datafile asynchronously on the RavenPack server for later retrieval.
Requesting a datafile, will give you back a job object, that will take
some time to complete.
.. code:: python
job = ds.request_datafile(
start_date='2018-01-05 18:00:00',
end_date='2018-01-05 18:01:00',
)
with open('output.csv') as fp:
job.save_to_file(filename=fp.name)
Streaming real-time data
It is possible to subscribe to a real-time stream for a dataset.
Once you create a streaming connection to the real-time feed with your
dataset, you will receive analytics records as soon as they are
published.
It is suggested to handle possible disconnection with a retry policy.
You can find a `real-time streaming example
here <ravenpackapi/examples/get_realtime_news.py>`__.
The Result object handles the conversion of various fields into the
appropriate type, i.e. ``record.timestamp_utc`` will be converted to
``datetime``
Entity mapping
~~~~~~~~~~~~~~
The entity mapping endpoint allow you to find the RP\_ENTITY\_ID mapped
to your universe of entities.
.. code:: python
universe = [
"RavenPack",
{'ticker': 'AAPL'},
{ # Amazon, specifying various fields
"client_id": "12345-A",
"date": "2017-01-01",
"name": "Amazon Inc.",
"entity_type": "COMP",
"isin": "US0231351067",
"cusip": "023135106",
"sedol": "B58WM62",
"listing": "XNAS:AMZN"
},
]
mapping = api.get_entity_mapping(universe)
# in this case we match everything
assert len(mapping.matched) == len(universe)
assert [m.name for m in mapping.matched] == [
"RavenPack Ltd.",
"Apple Inc.",
"Amazon.com Inc."
]
Entity reference
~~~~~~~~~~~~~~~~
The entity reference endpoint give you all the available information for
an Entity given the RP\_ENTITY\_ID
.. code:: python
ALPHABET_RP_ENTITY_ID = '4A6F00'
references = api.get_entity_reference(ALPHABET_RP_ENTITY_ID)
# show all the names over history
for name in references.names:
print(name.value, name.start, name.end)
# print all the ticket valid today
for ticker in references.tickers:
if ticker.is_valid():
print(ticker)
Training Datasets
~~~~~~~~~~~~~~~~~
Analyse your own content using RavenPack’s proprietary NLP technology.
The API for analyzing your internal content is still in beta and may
change in the future. You can request an early access and `see an
example of usage here <ravenpackapi/examples/text_extraction.py>`__.
Accessing the low-level requests
RavenPack API wrapper is using the requests library <https://2.python-requests.org>__ to do HTTPS requests, you can
set common requests parameters to all the outbound calls by setting the
common_request_params attribute.
For example, to disable HTTPS certificate verification and to setup your
internal proxy:
.. code:: python
api = RPApi()
api.common_request_params.update(
dict(
proxies={'https': 'http://your_internal_proxy:9999'},
verify=False,
)
)
# use the api to do requests
PS. For setting your internal proxies, requests will honor the
HTTPS_PROXY environment variable.