

Product
Introducing Reachability for PHP
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.
By Benjamin Barslev - Apr 24, 2026
sqlite-s3vfs
Advanced tools


Python virtual filesystem for SQLite to read from and write to S3.
No locking is performed, so client code must ensure that writes do not overlap with other writes or reads. If multiple writes happen at the same time, the database will probably become corrupt and data be lost.
Based on simonwo's gist, and inspired by phiresky's sql.js-httpvfs, dacort's Stack Overflow answer, and michalc's sqlite-s3-query.
sqlite-s3vfs stores the SQLite database in fixed-sized blocks, and each is stored as a separate object in S3. SQLite stores its data in fixed-size pages, and always writes exactly a page at a time. This virtual filesystem translates page reads and writes to block reads and writes. In the case of SQLite pages being the same size as blocks, which is the case by default, each page write results in exactly one block write.
Separate objects are required since S3 does not support the partial replace of an object; to change even 1 byte, it must be re-uploaded in full.
sqlite-s3vfs can be installed from PyPI using pip.
pip install sqlite-s3vfs
This will automatically install boto3, APSW, and any of their dependencies.
sqlite-s3vfs is an APSW virtual filesystem that requires boto3 for its communication with S3.
import apsw
import boto3
import sqlite_s3vfs
# A boto3 bucket resource
bucket = boto3.Session().resource('s3').Bucket('my-bucket')
# An S3VFS for that bucket
s3vfs = sqlite_s3vfs.S3VFS(bucket=bucket)
# sqlite-s3vfs stores many objects under this prefix
# Note that it's not typical to start a key prefix with '/'
key_prefix = 'my/path/cool.sqlite'
# Connect, insert data, and query
with apsw.Connection(key_prefix, vfs=s3vfs.name) as db:
cursor = db.cursor()
cursor.execute('''
CREATE TABLE foo(x,y);
INSERT INTO foo VALUES(1,2);
''')
cursor.execute('SELECT * FROM foo;')
print(cursor.fetchall())
See the APSW documentation for more examples.
The bytes corresponding to a regular SQLite file can be extracted with the serialize_iter function, which returns an iterable,
for chunk in s3vfs.serialize_iter(key_prefix=key_prefix):
print(chunk)
or with serialize_fileobj, which returns a non-seekable file-like object. This can be passed to Boto3's upload_fileobj method to upload a regular SQLite file to S3.
target_obj = boto3.Session().resource('s3').Bucket('my-target-bucket').Object('target/cool.sqlite')
target_obj.upload_fileobj(s3vfs.serialize_fileobj(key_prefix=key_prefix))
# Any iterable that yields bytes can be used. In this example, bytes come from
# a regular SQLite file already in S3
source_obj = boto3.Session().resource('s3').Bucket('my-source-bucket').Object('source/cool.sqlite')
bytes_iter = source_obj.get()['Body'].iter_chunks()
s3vfs.deserialize_iter(key_prefix='my/path/cool.sqlite', bytes_iter=bytes_iter)
SQLite writes data in pages, which are 4096 bytes by default. sqlite-s3vfs stores data in blocks, which are also 4096 bytes by default. If you change one you should change the other to match for performance reasons.
s3vfs = sqlite_s3vfs.S3VFS(bucket=bucket, block_size=65536)
with apsw.Connection(key_prefix, vfs=s3vfs.name) as db:
cursor = db.cursor()
cursor.execute('''
PRAGMA page_size = 65536;
''')
The tests require the dev dependencies and MinIO started
pip install -e ".[dev]"
./start-minio.sh
can be run with pytest
pytest
and finally Minio stopped
./stop-minio.sh
FAQs
Virtual filesystem for SQLite to read from and write to S3
We found that sqlite-s3vfs demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for PHP is now available in experimental, helping teams identify which vulnerabilities are actually exploitable.

Product
Export Socket alert data to your own cloud storage in JSON, CSV, or Parquet, with flexible snapshot or incremental delivery.
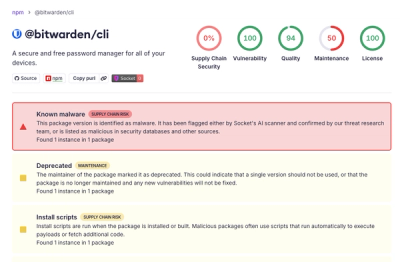
Research
/Security News
Bitwarden CLI 2026.4.0 was compromised in the Checkmarx supply chain campaign after attackers abused a GitHub Action in Bitwarden’s CI/CD pipeline.