
Product
Introducing Socket Fix for Safe, Automated Dependency Upgrades
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.
By John-David Dalton - Apr 25, 2025
![]()
Turn a list of STAC items into a 4D xarray DataArray (dims: time, band, y, x), including reprojection to a common grid. The array is a lazy Dask array, so loading and processing the data in parallel—locally or on a cluster—is just a compute() call away.
For more information and examples, please see the documentation.
import stackstac
import pystac_client
URL = "https://earth-search.aws.element84.com/v1"
catalog = pystac_client.Client.open(URL)
stac_items = catalog.search(
intersects=dict(type="Point", coordinates=[-105.78, 35.79]),
collections=["sentinel-2-l2a"],
datetime="2020-04-01/2020-05-01"
).get_all_items()
stack = stackstac.stack(stac_items)
print(stack)
<xarray.DataArray 'stackstac-fefccf3d6b2f9922dc658c114e79865b' (time: 13, band: 17, y: 10980, x: 10980)>
dask.array<fetch_raster_window, shape=(13, 17, 10980, 10980), dtype=float64, chunksize=(1, 1, 1024, 1024), chunktype=numpy.ndarray>
Coordinates: (12/24)
* time (time) datetime64[ns] 2020-04-01T18:04:04 ......
id (time) <U24 'S2B_13SDV_20200401_0_L2A' ... 'S...
* band (band) <U8 'overview' 'visual' ... 'WVP' 'SCL'
* x (x) float64 4e+05 4e+05 ... 5.097e+05 5.098e+05
* y (y) float64 4e+06 4e+06 ... 3.89e+06 3.89e+06
view:off_nadir int64 0
... ...
instruments <U3 'msi'
created (time) <U24 '2020-09-05T06:23:47.836Z' ... '2...
sentinel:sequence <U1 '0'
sentinel:grid_square <U2 'DV'
title (band) object None ... 'Scene Classification ...
epsg int64 32613
Attributes:
spec: RasterSpec(epsg=32613, bounds=(399960.0, 3890220.0, 509760.0...
crs: epsg:32613
transform: | 10.00, 0.00, 399960.00|\n| 0.00,-10.00, 4000020.00|\n| 0.0...
resolution: 10.0
Once in xarray form, many operations become easy. For example, we can compute a low-cloud weekly mean-NDVI timeseries:
lowcloud = stack[stack["eo:cloud_cover"] < 40]
nir, red = lowcloud.sel(band="B08"), lowcloud.sel(band="B04")
ndvi = (nir - red) / (nir + red)
weekly_ndvi = ndvi.resample(time="1w").mean(dim=("time", "x", "y")).rename("NDVI")
# Call `weekly_ndvi.compute()` to process ~25GiB of raster data in parallel. Might want a dask cluster for that!
pip install stackstac
Windows notes:
It's a good idea to use conda to handle installing rasterio on Windows. There's considerably more pain involved with GDAL-type installations using pip. Then pip install stackstac.
stackstac does for you:red, green, and blue asset on each Item is great, but a single RGB asset containing a 3-band GeoTIFF is not supported yet..msk files) are ignored for performance. JPEG2000 will probably work, but probably be slow unless you buy kakadu. Formats make a big difference.Short-term:
s3://-style URIs (right now, you'll need to pass in gdal_env=stackstac.DEFAULT_GDAL_ENV.updated(always=dict(session=rio.session.AWSSession(...))))Long term (if anyone uses this thing):
FAQs
Load a STAC collection into xarray with dask
We found that stackstac demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.

Security News
CISA denies CVE funding issues amid backlash over a new CVE foundation formed by board members, raising concerns about transparency and program governance.
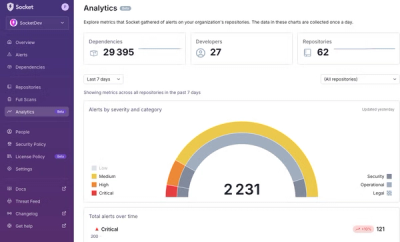
Product
We’re excited to announce a powerful new capability in Socket: historical data and enhanced analytics.