StructuredDataProfiling
The StructuredDataProfiling is a Python library developed to automatically profile structured datasets and to facilitate the creation of data tests.
The library creates data tests in the form of Expectations using the great_expectations framework. Expectations are 'declarative statements that a computer can evaluate and semantically meaningful to humans'.
An expectation could be, for example, 'the sum of columns a and b should be equal to one' or 'the values in column c should be non-negative'.
StructuredDataProfiling runs a series of tests aimed at identifying statistics, rules, and constraints characterising a given dataset. The information generated by the profiler is collected by performing the following operations:
- Characterise uni- and bi-variate distributions.
- Identify data quality issues.
- Evaluate relationships between attributes (ex. column C is the difference between columns A and B)
- Understand ontologies characterizing categorical data (column A contains names, while B contains geographical places).
For an overview of the library outputs please check the examples section.
Installation
You can install StructuredDataProfiling by using pip:
pip install structured-profiling
Quickstart
You can import the profiler using
from structured_data_profiling.profiler import DatasetProfiler
You can import the profiler using
profiler = DatasetProfiler('./csv_path.csv')
The presence of a primary key (for example to define relations between tables or sequences) can be specified by using the argument primary key containing a single or multiple column names.
To start the profiling scripts, you can run the profile() method
profiler.profile()
The method generate_expectations() outputs the results of the profiling process converted into data expectations. Please note, the method requires the existence of a local great_expectations project.
If you haven't done so please run great_expectations init in your working directory.
profiler.generate_expectations()
The expectations are generated in a JSON format using the great_expectation schema. The method will also create data docs using the rendered provided by the great_expectations library.
These docs can be found in the local folder great_expectations/uncommitted/data_docs.
Profiling outputs
The profiler generates 3 json files describing the ingested dataset. These json files contain information about:
- column_profiles: it contains the statistical characterisation of the dataset columns.
- dataset_profile: it highlights issues and limitations affecting the dataset.
- tests: it contains the data tests found by the profiler.
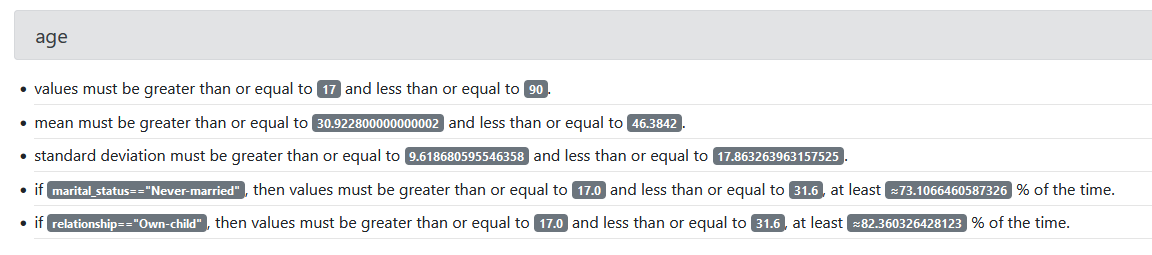
The process of generating expectations makes use of the great_expectations library to produce an HTML file contaning data docs. An example of data doc for a given column can be seen in the image below.
Examples
You can find a couple of notebook examples in the examples folder.
To-dos
Disclaimer: this library is still at a very early stage. Among other things, we still need to:



