━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
TABLE DETECTION IN IMAGES AND OCR TO CSV
Eric Ihli
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Table of Contents
─────────────────
- Overview
- Requirements
- Demo
- Modules
1 Overview
══════════
This python package contains modules to help with finding and
extracting tabular data from a PDF or image into a CSV format.
Given an image that contains a table…
file:resources/examples/example-page.png
Extract the the text into a CSV format…
┌────
│ PRIZE,ODDS 1 IN:,# OF WINNERS*
│ $3,9.09,"282,447"
│ $5,16.66,"154,097"
│ $7,40.01,"64,169"
│ $10,26.67,"96,283"
│ $20,100.00,"25,677"
│ $30,290.83,"8,829"
│ $50,239.66,"10,714"
│ $100,919.66,"2,792"
│ $500,"6,652.07",386
│ "$40,000","855,899.99",3
│ 1,i223,
│ Toa,,
│ ,,
│ ,,"* Based upon 2,567,700"
└────
2 Requirements
══════════════
Along with the python requirements that are listed in setup.py and
that are automatically installed when installing this package through
pip, there are a few external requirements for some of the modules.
I haven’t looked into the minimum required versions of these
dependencies, but I’ll list the versions that I’m using.
• pdfimages' 20.09.0 of [Poppler] • tesseract' 5.0.0 of [Tesseract]
• `mogrify' 7.0.10 of [ImageMagick]
[Poppler] https://poppler.freedesktop.org/
[Tesseract] https://github.com/tesseract-ocr/tesseract
[ImageMagick] https://imagemagick.org/index.php
3 Demo
══════
There is a demo module that will download an image given a URL and try
to extract tables from the image and process the cells into a CSV. You
can try it out with one of the images included in this repo.
That will run against the following image:
file:resources/test_data/simple.png
The following should be printed to your terminal after running the
above commands.
┌────
│ Running extract_tables.main([/tmp/demo_p9on6m8o/simple.png]).
│ Extracted the following tables from the image:
│ [('/tmp/demo_p9on6m8o/simple.png', ['/tmp/demo_p9on6m8o/simple/table-000.png'])]
│ Processing tables for /tmp/demo_p9on6m8o/simple.png.
│ Processing table /tmp/demo_p9on6m8o/simple/table-000.png.
│ Extracted 18 cells from /tmp/demo_p9on6m8o/simple/table-000.png
│ Cells:
│ /tmp/demo_p9on6m8o/simple/cells/000-000.png: Cell
│ /tmp/demo_p9on6m8o/simple/cells/000-001.png: Format
│ /tmp/demo_p9on6m8o/simple/cells/000-002.png: Formula
│ ...
│
│ Here is the entire CSV output:
│
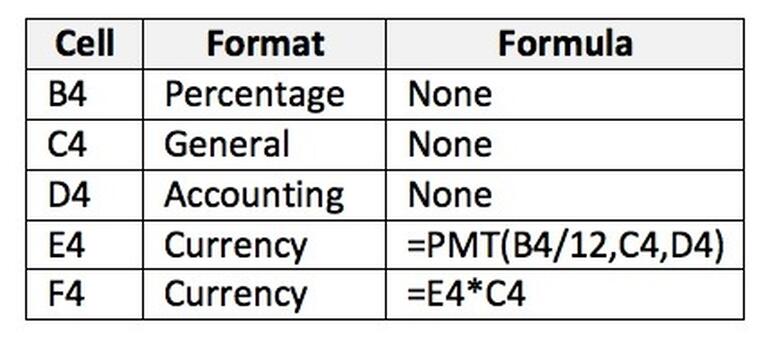
│ Cell,Format,Formula
│ B4,Percentage,None
│ C4,General,None
│ D4,Accounting,None
│ E4,Currency,"=PMT(B4/12,C4,D4)"
│ F4,Currency,=E4*C4
└────
4 Modules
═════════
The package is split into modules with narrow focuses.
• pdf_to_images' uses Poppler and ImageMagick to extract images from a PDF. • extract_tables' finds and extracts table-looking things from an
image.
• extract_cells' extracts and orders cells from a table. • ocr_image' uses Tesseract to OCR the text from an image of a cell.
• ocr_to_csv' converts into a CSV the directory structure that ocr_image' outputs.
The outputs of a previous module can be used by a subsequent module so
that they can be chained together to create the entire workflow, as
demonstrated by the following shell script.
┌────
│ #!/bin/sh
│
│ PDF=$1
│
│ python -m table_ocr.pdf_to_images $PDF | grep .png > /tmp/pdf-images.txt
│ cat /tmp/pdf-images.txt | xargs -I{} python -m table_ocr.extract_tables {} | grep table > /tmp/extracted-tables.txt
│ cat /tmp/extracted-tables.txt | xargs -I{} python -m table_ocr.extract_cells {} | grep cells > /tmp/extracted-cells.txt
│ cat /tmp/extracted-cells.txt | xargs -I{} python -m table_ocr.ocr_image {}
│
│ for image in $(cat /tmp/extracted-tables.txt); do
│ dir=$(dirname $image)
│ python -m table_ocr.ocr_to_csv $(find $dir/cells -name "*.txt")
│ done
└────
The package was written in a [literate programming] style. The source
code at
https://eihli.github.io/image-table-ocr/pdf_table_extraction_and_ocr.html
is meant to act as the documentation and reference material.
[literate programming]
https://en.wikipedia.org/wiki/Literate_programming




{kind=link}