WebShotApi.com API client for Python
Capture and store website snapshots effortlessly with our SaaS service.
Use our AI unique algorithm for remove cookies and popup banner before take screenshot.
Save images in popular formats such as JPG, PNG, WEBP and PDF.
Additionally, extract selectors for every HTML element,
complete with coordinates and CSS styles post-browser rendering.
Full documentation about our api you can find in this website Website screenshot API DOCS
Installation
Use the package manager pip to install our client in Python.
pip install webshotapi
OR
pip3 install webshotapi
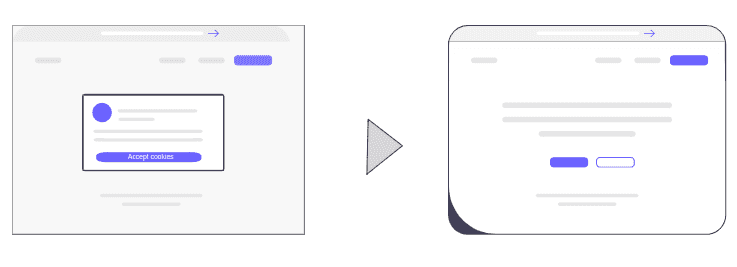
Effortlessly remove annoying cookies pop-ups before capturing stunning screenshots.
Let our advanced AI algorithm transform the way you visualize websites, ensuring a cookie-free snapshot every time! Read more
API KEY
Api key you can generate after register.
https://dashboard.webshotapi.com/api_keys
Usage
Take screenshot and save jpg to file
from webshotapi import Client
if __name__ == "__main__":
try:
TOKEN = 'YOUR TOKEN HERE'
client = Client(TOKEN)
result = client.screenshot(
'https://www.example.com',{
'remove_modals': True,
'no_cache': True
})
if result.save('/tmp/testa.jpg'):
print("File saved")
else:
print("Error with save file")
except Exception as e:
print("Error:")
print(e)
Take screenshot and save PDF to file
You can convert your html page to PDF. For example you can prepare html invoice template and convert that website to PDF
from webshotapi import Client
if __name__ == "__main__":
try:
TOKEN = 'YOUR TOKEN HERE'
client = Client(TOKEN)
result = client.pdf(
'https://www.example.com',{
'no_cache': 1
})
if result.save('/tmp/test.pdf'):
print("File saved")
else:
print("Error with save file")
except Exception as e:
print("Error:")
print(e)
Extract words map and HTML elements with css styles after rendering
Revolutionize your web development experience with our unparalleled software. Extract all selectors for HTML elements, complete with CSS styles, post-browser rendering. Furthermore, delve into the intricate details by extracting words along with their precise position data (x, y, width, height, offset from the previous word). This invaluable information allows you to construct a comprehensive words map of the entire website. Elevate your understanding and efficiency in website analysis and development like never before!
Sample script:
from webshotapi import Client
if __name__ == "__main__":
try:
TOKEN = 'YOUR TOKEN HERE'
client = Client(TOKEN)
result = client.extract('https://www.example.com',{
'no_cache': 1,
'extract_selectors': 1,
'extract_style': 1,
'extract_words': 1,
'extract_html': 1,
'extract_text': 1
})
print(result.data())
except Exception as e:
print("Error:")
print(e)
Results
{
"selectors": [
{
"xpath": "/html[1]",
"css_selector": "html",
"x": 0,
"y": 0,
"w": 1920,
"h": 413,
"style": {
"visibility": "visible",
"display": "block",
"fontWeight": "400",
"backgroundImage": "none",
"backgroundColor": "rgba(0, 0, 0, 0)",
"cursor": "auto",
"fontSize": "16px",
"color": "rgb(0, 0, 0)",
"position": "static",
"textDecoration": "none solid rgb(0, 0, 0)",
"textDecorationLine": "none",
"textDecorationColor": "rgb(0, 0, 0)",
"textDecorationStyle": "solid",
"textDecorationThickness": "auto",
"bottom": "auto",
"top": "auto",
"left": "auto",
"right": "auto",
"zIndex": "auto",
"opacity": "1",
"backgroundRepeat": "repeat",
"borderWidth": "0px",
"textAlign": "start",
"marginLeft": "0px",
"marginRight": "0px",
"marginTop": "0px",
"marginBottom": "0px",
"paddingLeft": "0px",
"paddingRight": "0px",
"paddingTop": "0px",
"paddingBottom": "0px",
"overflow": "visible",
"textIndent": "0px",
"textTransform": "none",
"letterSpacing": "normal",
"fontFamily": "\"Times New Roman\""
},
"attributes": {}
}
],
"words": [
{
"word": "permission.",
"position": {
"x": 660,
"y": 231,
"w": 92,
"h": 19
},
"word_index": 26,
"xpath": "/html[1]/body[1]/div[1]/p[1]",
"offset": 145
}
],
"page_properties": {
"viewport": {
"width": 1920,
"height": 1080
},
"document": {
"width": 1920,
"height": 1080
}
},
"html": "<!doctype html><html lang='en' dir='ltr'><head><base hr...",
"text": "Welcome in our page\nToday is Monday...",
"screenshot_url": "https://api.webshotapi.com/v1/screenshot/?token=....&width=1920&height=960",
"status_code": 200
}
API docs
Full documentation about our api you can find in this website API DOCS
About our service
You can use our service with free plan with 100 free requests
License
MIT



