Product
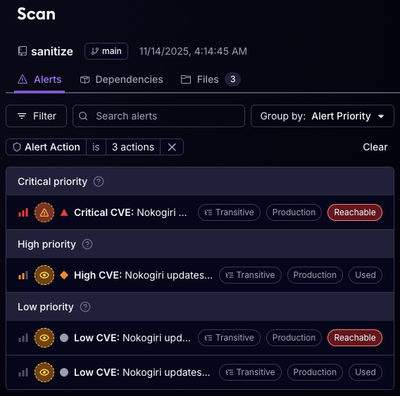
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
While Zalgo text's popularity has waned, I'm still a fan. I also have a need for it. Other Zalgo libraries aren't recent, are a part of a larger set of tools, haven't been audited for security recently, or don't offer a lot of customization options.
The goal of this library is to give a decent set of defaults for en-Zalgo-fy [encoding to Zalgo] and de-Zalgo-fy [decoding from Zalgo] text to various degrees, as well as creating a custom class to dial in specific options.
I want to focus on functionality and periodically check in and update as needed.
random (standard library) is the only dependency required. I've writting this library in python 3.7, but I expect it should work fairly well with a wider set of python versions. The key is my use of random.choices() - if this isn't importable, you'll need to adjust and tweak. I use it to select from the lists of diacritics with replacement.
enzalgofy : takes two keyword arguments (text and intensity).
text expects a string as input - you can feed it from whatever source you want.intensity expects an int from 0-100 (inclusive) and represents a rough percentage of the marks to include on each character. The default is 50. This scales up quite quickly, with values less than 20 being fairly light and values over 75 being very heavy. The differences lower or higher (respectively) from those points have some diminishing returns on legibility.
dezalgofy : takes a zalgo string, converts it to ascii, and then back to utf-8. It ignores all errors. This isn't great overall, since if you're adding text that's accented already, it will return a stripped version of it. To be fair, that problem seems sufficiently complex to solve, and probably benefits from a language specifier and dictionaries, or some ML magic. As it is, it's fairly lean and does the job.
This contains the various diacritics used in creating zalgo text. Currently, it contains:
list. There are currently 40 of these.DOWN_MARKS as intlist. There are currently 46 of these.UP_MARKS as intlist. There are currently 21 of these.MID_MARKS as intThis is a work-in-progress. There are many more overlapping marks to be found in the unicode space. I hope to revisit these soon and include some of the ones specified below:
These python lists can be added to in your script, but you'll have to recalculate the lengths (since length calculation from the module is done at import). Conversely, you can just append the characters to diacritics.py as you see fit, either by adding them to the list or adding them as new lists.
I went with a permissive license (MIT) so feel free to use this any way you want. If you're proud of what you've made with my library, feel free to reach out and I'll try to add your project to a list below. Also, please check the credits section below, which also contributed to my choice to go with the MIT license.
I am utilizing the list of diacritics that was carefully and conveniently laid out by Gregory Neal in his Zalgo implementation. Huge thanks to him for not only being a great programmer, but also using a very permissive MIT license that allows me to use a part of his work for my own. Just because I don't have to credit him doesn't mean I won't.
FAQs
A Python library for a _FULL_ Zalgo experience
We found that zalgolib demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.