
Product
Announcing Socket Certified Patches: One-Click Fixes for Vulnerable Dependencies
A safer, faster way to eliminate vulnerabilities without updating dependencies
By Mikola Lysenko, Jordan Harband, Jonah Ghebremichael - Nov 18, 2025
Harvestman is a very simple, lightweight web crawler for Quick'n'Dirty™ web scraping.
It's quite useful for scraping search result pages:
require 'harvestman'
Harvestman.crawl 'http://www.foo.com/bars?page=*', (1..5) do
price = css 'div.item-price a'
...
end
[!] Warning: this gem is in alpha stage (no tests), don't use it for anything serious.
Via command line:
$ gem install harvestman
Harvestman is fairly simple to use: you specify the URL to crawl and pass in a block.
Inside the block you can call the css (or xpath) method to search the HTML document and get the inner text inside each node.
See Nokogiri for more information.
Harvestman.crawl "http://www.24pullrequests.com" do
headline = xpath "//h3"
catchy_phrase = css "div.visible-phone h3"
puts "Headline: #{headline}"
puts "Catchy phrase: #{catchy_phrase}"
end
Harvestman assumes there's only one node at the path you passed to the css.
If there is more than one node at that path, you can pass in an additional block.
Harvestman.crawl 'http://en.wikipedia.org/wiki/Main_Page' do
# Print today's featured article
tfa = css "div#mp-tfa"
puts "Today's featured article: #{tfa}"
# Print all the sister projects
sister_projects = []
css "div#mp-sister b" do
sister_projects << css("a")
end
puts "Sister projects:"
sister_projects.each { |sp| puts "- #{sp}" }
end
Note that inside the block we use css("a") and not css("div#mp-sister b a"). Calls to css or xpath here assume div#mp-sister b is the parent node.
If you want to crawl a group of similar pages (eg: search results, as shown above), you can insert a * somewhere in the URL string and it will be replaced by each element in the second argument.
require 'harvestman'
Harvestman.crawl 'http://www.etsy.com/browse/vintage-category/electronics/*', (1..3) do
css "div.listing-hover" do
title = css "div.title a"
price = css "span.listing-price"
puts "* #{title} (#{price})"
end
end
The above code is going to crawl Etsy's electronics category pages (from 1 to 3) and output every item's title and price. Here we're using a range (1..3) but you could've passed an array with search queries:
"http://www.site.com?query=*", ["dogs", "cats", "birds"]
When using the * feature described above, each page is run inside a separate thread. You can disable multithreading by passing an additional argument :plain to the crawl method, like this:
require 'harvestman'
Harvestman.crawl 'http://www.store.com/products?page=*', (1..99), :plain do
...
end
Needless to say, this will greatly decrease performance.
See LICENSE.txt
FAQs
Unknown package
We found that harvestman demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
A safer, faster way to eliminate vulnerabilities without updating dependencies
Product
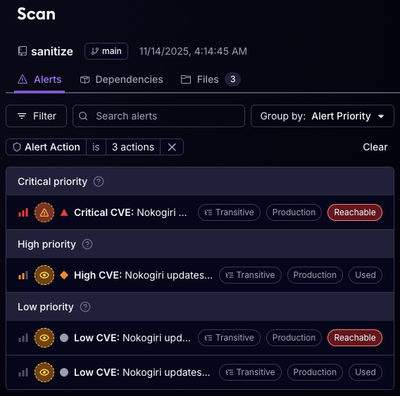
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.