
Product
Announcing Socket Certified Patches: One-Click Fixes for Vulnerable Dependencies
A safer, faster way to eliminate vulnerabilities without updating dependencies
By Mikola Lysenko, Jordan Harband, Jonah Ghebremichael - Nov 18, 2025
@juspay/neurolink
Advanced tools
AI toolkit with multi-provider support for OpenAI, Amazon Bedrock, and Google Vertex AI
![]()
![]()
![]()
Production-ready AI toolkit with multi-provider support, automatic fallback, and full TypeScript integration. Now with a professional CLI!
NeuroLink provides a unified interface for AI providers (OpenAI, Amazon Bedrock, Google Vertex AI) with intelligent fallback, streaming support, and type-safe APIs. Available as both a programmatic SDK and a professional CLI tool. Extracted from production use at Juspay.
# Install globally for CLI usage
npm install -g @juspay/neurolink
# Or use directly with npx (no installation required)
npx @juspay/neurolink generate-text "Hello, AI!"
# Or install globally
npm install -g @juspay/neurolink
neurolink generate-text "Write a haiku about programming"
neurolink status --verbose
npm install @juspay/neurolink ai @ai-sdk/amazon-bedrock @ai-sdk/openai @ai-sdk/google-vertex zod
import { createBestAIProvider } from '@juspay/neurolink';
// Auto-selects best available provider
const provider = createBestAIProvider();
const result = await provider.generateText({
prompt: "Hello, AI!"
});
console.log(result.text);
No installation required! Experience NeuroLink's capabilities through our comprehensive visual ecosystem:
| Feature | Screenshot | Description |
|---|---|---|
| Main Interface |  | Complete web interface showing all features |
| AI Generation Results |  | Real AI content generation in action |
| Business Use Cases |  | Professional business applications |
| Creative Tools |  | Creative content generation |
| Developer Tools |  | Code generation and API docs |
| Analytics & Monitoring |  | Real-time provider analytics |
| Command | Screenshot | Description |
|---|---|---|
| CLI Help Overview |  | Complete command reference |
| Provider Status Check |  | All provider connectivity verified |
| Text Generation |  | Real AI haiku generation with JSON |
| Auto Provider Selection |  | Automatic provider selection working |
| Batch Processing |  | Multi-prompt processing with results |
📁 View complete visual documentation including all screenshots, videos, and interactive examples.
🔄 Multi-Provider Support - OpenAI, Amazon Bedrock, Google Vertex AI ⚡ Automatic Fallback - Seamless provider switching on failures 📡 Streaming & Non-Streaming - Real-time responses and standard generation 🎯 TypeScript First - Full type safety and IntelliSense support 🛡️ Production Ready - Extracted from proven production systems 🔧 Zero Config - Works out of the box with environment variables
# npm
npm install @juspay/neurolink ai @ai-sdk/amazon-bedrock @ai-sdk/openai @ai-sdk/google-vertex zod
# yarn
yarn add @juspay/neurolink ai @ai-sdk/amazon-bedrock @ai-sdk/openai @ai-sdk/google-vertex zod
# pnpm (recommended)
pnpm add @juspay/neurolink ai @ai-sdk/amazon-bedrock @ai-sdk/openai @ai-sdk/google-vertex zod
# Choose one or more providers
export OPENAI_API_KEY="sk-your-openai-key"
export AWS_ACCESS_KEY_ID="your-aws-key"
export AWS_SECRET_ACCESS_KEY="your-aws-secret"
export GOOGLE_APPLICATION_CREDENTIALS="path/to/service-account.json"
import { createBestAIProvider } from '@juspay/neurolink';
const provider = createBestAIProvider();
// Basic generation
const result = await provider.generateText({
prompt: "Explain TypeScript generics",
temperature: 0.7,
maxTokens: 500
});
console.log(result.text);
console.log(`Used: ${result.provider}`);
import { createBestAIProvider } from '@juspay/neurolink';
const provider = createBestAIProvider();
const result = await provider.streamText({
prompt: "Write a story about AI",
temperature: 0.8,
maxTokens: 1000
});
// Handle streaming chunks
for await (const chunk of result.textStream) {
process.stdout.write(chunk);
}
import { AIProviderFactory } from '@juspay/neurolink';
// Use specific provider
const openai = AIProviderFactory.createProvider('openai', 'gpt-4o');
const bedrock = AIProviderFactory.createProvider('bedrock', 'claude-3-7-sonnet');
// With fallback
const { primary, fallback } = AIProviderFactory.createProviderWithFallback(
'bedrock', 'openai'
);
NeuroLink includes a professional CLI tool that provides all SDK functionality through an elegant command-line interface.
# Use directly without installation
npx @juspay/neurolink --help
npx @juspay/neurolink generate-text "Hello, AI!"
npx @juspay/neurolink status
# Install globally for convenient access
npm install -g @juspay/neurolink
# Then use anywhere
neurolink --help
neurolink generate-text "Write a haiku about programming"
neurolink status --verbose
# Add to project and use via npm scripts
npm install @juspay/neurolink
npx neurolink generate-text "Explain TypeScript"
generate-text <prompt> - Core Text Generation# Basic text generation
neurolink generate-text "Explain quantum computing"
# With provider selection
neurolink generate-text "Write a story" --provider openai
# With temperature and token control
neurolink generate-text "Creative writing" --temperature 0.9 --max-tokens 1000
# JSON output for scripting
neurolink generate-text "Summary of AI" --format json
Output Example:
🤖 Generating text...
✅ Text generated successfully!
Quantum computing represents a revolutionary approach to information processing...
ℹ️ 127 tokens used
stream <prompt> - Real-time Streaming# Stream text generation in real-time
neurolink stream "Tell me a story about robots"
# With provider selection
neurolink stream "Explain machine learning" --provider vertex --temperature 0.8
Output Example:
🔄 Streaming from auto provider...
Once upon a time, in a world where technology had advanced beyond...
[text streams in real-time as it's generated]
batch <file> - Process Multiple Prompts# Create a file with prompts (one per line)
echo -e "Write a haiku\nExplain gravity\nDescribe the ocean" > prompts.txt
# Process all prompts
neurolink batch prompts.txt
# Save results to JSON file
neurolink batch prompts.txt --output results.json
# Add delay between requests (rate limiting)
neurolink batch prompts.txt --delay 2000
Output Example:
📦 Processing 3 prompts...
✅ 1/3 completed
✅ 2/3 completed
✅ 3/3 completed
✅ Results saved to results.json
status - Provider Diagnostics# Check all provider connectivity
neurolink status
# Verbose output with detailed information
neurolink status --verbose
Output Example:
🔍 Checking AI provider status...
✅ openai: ✅ Working (234ms)
✅ bedrock: ✅ Working (456ms)
❌ vertex: ❌ Authentication failed
📊 Summary: 2/3 providers working
get-best-provider - Auto-selection Testing# Test which provider would be auto-selected
neurolink get-best-provider
Output Example:
🎯 Finding best provider...
✅ Best provider: bedrock
--help, -h - Show help information--version, -v - Show version number--provider <name> - Choose provider: auto (default), openai, bedrock, vertex--temperature <number> - Creativity level: 0.0 (focused) to 1.0 (creative), default: 0.7--max-tokens <number> - Maximum tokens to generate, default: 500--format <type> - Output format: text (default) or json--output <file> - Save results to JSON file--delay <ms> - Delay between requests in milliseconds, default: 1000--verbose, -v - Show detailed diagnostic information# Generate creative content with high temperature
neurolink generate-text "Write a sci-fi story opening" \
--provider openai \
--temperature 0.9 \
--max-tokens 1000 \
--format json > story.json
# Check what was generated
cat story.json | jq '.content'
# Create prompts file
cat > content-prompts.txt << EOF
Write a product description for AI software
Create a social media post about technology
Draft an email about our new features
Write a blog post title about machine learning
EOF
# Process all prompts and save results
neurolink batch content-prompts.txt \
--output content-results.json \
--provider bedrock \
--delay 2000
# Extract just the content
cat content-results.json | jq -r '.[].response'
# Check provider status (useful for monitoring scripts)
neurolink status --format json > status.json
# Parse results in scripts
working_providers=$(cat status.json | jq '[.[] | select(.status == "working")] | length')
echo "Working providers: $working_providers"
#!/bin/bash
# AI-powered commit message generator
# Get git diff
diff=$(git diff --cached --name-only)
if [ -z "$diff" ]; then
echo "No staged changes found"
exit 1
fi
# Generate commit message
commit_msg=$(neurolink generate-text \
"Generate a concise git commit message for these changes: $diff" \
--max-tokens 50 \
--temperature 0.3)
echo "Suggested commit message:"
echo "$commit_msg"
# Optionally auto-commit
read -p "Use this commit message? (y/N): " -n 1 -r
if [[ $REPLY =~ ^[Yy]$ ]]; then
git commit -m "$commit_msg"
fi
The CLI uses the same environment variables as the SDK:
# Set up your providers (same as SDK)
export OPENAI_API_KEY="sk-your-key"
export AWS_ACCESS_KEY_ID="your-aws-key"
export AWS_SECRET_ACCESS_KEY="your-aws-secret"
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/service-account.json"
# Test configuration
neurolink status
| Feature | CLI | SDK |
|---|---|---|
| Text Generation | ✅ generate-text | ✅ generateText() |
| Streaming | ✅ stream | ✅ streamText() |
| Provider Selection | ✅ --provider flag | ✅ createProvider() |
| Batch Processing | ✅ batch command | ✅ Manual implementation |
| Status Monitoring | ✅ status command | ✅ Manual testing |
| JSON Output | ✅ --format json | ✅ Native objects |
| Automation | ✅ Perfect for scripts | ✅ Perfect for apps |
| Learning Curve | 🟢 Low | 🟡 Medium |
src/routes/api/chat/+server.ts)import { createBestAIProvider } from '@juspay/neurolink';
import type { RequestHandler } from './$types';
export const POST: RequestHandler = async ({ request }) => {
try {
const { message } = await request.json();
const provider = createBestAIProvider();
const result = await provider.streamText({
prompt: message,
temperature: 0.7,
maxTokens: 1000
});
return new Response(result.toReadableStream(), {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache'
}
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
status: 500,
headers: { 'Content-Type': 'application/json' }
});
}
};
src/routes/chat/+page.svelte)<script lang="ts">
let message = '';
let response = '';
let isLoading = false;
async function sendMessage() {
if (!message.trim()) return;
isLoading = true;
response = '';
try {
const res = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message })
});
if (!res.body) throw new Error('No response');
const reader = res.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
response += decoder.decode(value, { stream: true });
}
} catch (error) {
response = `Error: ${error.message}`;
} finally {
isLoading = false;
}
}
</script>
<div class="chat">
<input bind:value={message} placeholder="Ask something..." />
<button on:click={sendMessage} disabled={isLoading}>
{isLoading ? 'Sending...' : 'Send'}
</button>
{#if response}
<div class="response">{response}</div>
{/if}
</div>
app/api/ai/route.ts)import { createBestAIProvider } from '@juspay/neurolink';
import { NextRequest, NextResponse } from 'next/server';
export async function POST(request: NextRequest) {
try {
const { prompt, ...options } = await request.json();
const provider = createBestAIProvider();
const result = await provider.generateText({
prompt,
temperature: 0.7,
maxTokens: 1000,
...options
});
return NextResponse.json({
text: result.text,
provider: result.provider,
usage: result.usage
});
} catch (error) {
return NextResponse.json(
{ error: error.message },
{ status: 500 }
);
}
}
components/AIChat.tsx)'use client';
import { useState } from 'react';
export default function AIChat() {
const [prompt, setPrompt] = useState('');
const [result, setResult] = useState<string>('');
const [loading, setLoading] = useState(false);
const generate = async () => {
if (!prompt.trim()) return;
setLoading(true);
try {
const response = await fetch('/api/ai', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt })
});
const data = await response.json();
setResult(data.text);
} catch (error) {
setResult(`Error: ${error.message}`);
} finally {
setLoading(false);
}
};
return (
<div className="space-y-4">
<div className="flex gap-2">
<input
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
placeholder="Enter your prompt..."
className="flex-1 p-2 border rounded"
/>
<button
onClick={generate}
disabled={loading}
className="px-4 py-2 bg-blue-500 text-white rounded disabled:opacity-50"
>
{loading ? 'Generating...' : 'Generate'}
</button>
</div>
{result && (
<div className="p-4 bg-gray-100 rounded">
{result}
</div>
)}
</div>
);
}
import express from 'express';
import { createBestAIProvider, AIProviderFactory } from '@juspay/neurolink';
const app = express();
app.use(express.json());
// Simple generation endpoint
app.post('/api/generate', async (req, res) => {
try {
const { prompt, options = {} } = req.body;
const provider = createBestAIProvider();
const result = await provider.generateText({
prompt,
...options
});
res.json({
success: true,
text: result.text,
provider: result.provider
});
} catch (error) {
res.status(500).json({
success: false,
error: error.message
});
}
});
// Streaming endpoint
app.post('/api/stream', async (req, res) => {
try {
const { prompt } = req.body;
const provider = createBestAIProvider();
const result = await provider.streamText({ prompt });
res.setHeader('Content-Type', 'text/plain');
res.setHeader('Cache-Control', 'no-cache');
for await (const chunk of result.textStream) {
res.write(chunk);
}
res.end();
} catch (error) {
res.status(500).json({ error: error.message });
}
});
app.listen(3000, () => {
console.log('Server running on http://localhost:3000');
});
import { useState, useCallback } from 'react';
interface AIOptions {
temperature?: number;
maxTokens?: number;
provider?: string;
}
export function useAI() {
const [loading, setLoading] = useState(false);
const [error, setError] = useState<string | null>(null);
const generate = useCallback(async (
prompt: string,
options: AIOptions = {}
) => {
setLoading(true);
setError(null);
try {
const response = await fetch('/api/ai', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt, ...options })
});
if (!response.ok) {
throw new Error(`Request failed: ${response.statusText}`);
}
const data = await response.json();
return data.text;
} catch (err) {
const message = err instanceof Error ? err.message : 'Unknown error';
setError(message);
return null;
} finally {
setLoading(false);
}
}, []);
return { generate, loading, error };
}
// Usage
function MyComponent() {
const { generate, loading, error } = useAI();
const handleClick = async () => {
const result = await generate("Explain React hooks", {
temperature: 0.7,
maxTokens: 500
});
console.log(result);
};
return (
<button onClick={handleClick} disabled={loading}>
{loading ? 'Generating...' : 'Generate'}
</button>
);
}
createBestAIProvider(requestedProvider?, modelName?)Creates the best available AI provider based on environment configuration.
const provider = createBestAIProvider();
const provider = createBestAIProvider('openai'); // Prefer OpenAI
const provider = createBestAIProvider('bedrock', 'claude-3-7-sonnet');
createAIProviderWithFallback(primary, fallback, modelName?)Creates a provider with automatic fallback.
const { primary, fallback } = createAIProviderWithFallback('bedrock', 'openai');
try {
const result = await primary.generateText({ prompt });
} catch {
const result = await fallback.generateText({ prompt });
}
createProvider(providerName, modelName?)Creates a specific provider instance.
const openai = AIProviderFactory.createProvider('openai', 'gpt-4o');
const bedrock = AIProviderFactory.createProvider('bedrock', 'claude-3-7-sonnet');
const vertex = AIProviderFactory.createProvider('vertex', 'gemini-2.5-flash');
All providers implement the same interface:
interface AIProvider {
generateText(options: GenerateTextOptions): Promise<GenerateTextResult>;
streamText(options: StreamTextOptions): Promise<StreamTextResult>;
}
interface GenerateTextOptions {
prompt: string;
temperature?: number;
maxTokens?: number;
systemPrompt?: string;
}
interface GenerateTextResult {
text: string;
provider: string;
model: string;
usage?: {
promptTokens: number;
completionTokens: number;
totalTokens: number;
};
}
gpt-4o (default)gpt-4o-minigpt-4-turboclaude-3-7-sonnet (default)claude-3-5-sonnetclaude-3-haikugemini-2.5-flash (default)claude-4.0-sonnetexport OPENAI_API_KEY="sk-your-key-here"
⚠️ CRITICAL: Anthropic Models Require Inference Profile ARN
For Anthropic Claude models in Bedrock, you MUST use the full inference profile ARN, not simple model names:
export AWS_ACCESS_KEY_ID="your-access-key"
export AWS_SECRET_ACCESS_KEY="your-secret-key"
export AWS_REGION="us-east-2"
# ✅ CORRECT: Use full inference profile ARN for Anthropic models
export BEDROCK_MODEL="arn:aws:bedrock:us-east-2:<account_id>:inference-profile/us.anthropic.claude-3-7-sonnet-20250219-v1:0"
# ❌ WRONG: Simple model names cause "not authorized to invoke this API" errors
# export BEDROCK_MODEL="anthropic.claude-3-sonnet-20240229-v1:0"
# Claude 3.7 Sonnet (Latest - Recommended)
BEDROCK_MODEL="arn:aws:bedrock:us-east-2:<account_id>:inference-profile/us.anthropic.claude-3-7-sonnet-20250219-v1:0"
# Claude 3.5 Sonnet
BEDROCK_MODEL="arn:aws:bedrock:us-east-2:<account_id>:inference-profile/us.anthropic.claude-3-5-sonnet-20241022-v2:0"
# Claude 3 Haiku
BEDROCK_MODEL="arn:aws:bedrock:us-east-2:<account_id>:inference-profile/us.anthropic.claude-3-haiku-20240307-v1:0"
For temporary credentials (common in development):
export AWS_SESSION_TOKEN="your-session-token" # Required for temporary credentials
NeuroLink supports three authentication methods for Google Vertex AI:
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/service-account.json"
export GOOGLE_VERTEX_PROJECT="your-project-id"
export GOOGLE_VERTEX_LOCATION="us-central1"
export GOOGLE_SERVICE_ACCOUNT_KEY='{"type":"service_account","project_id":"your-project",...}'
export GOOGLE_VERTEX_PROJECT="your-project-id"
export GOOGLE_VERTEX_LOCATION="us-central1"
export GOOGLE_AUTH_CLIENT_EMAIL="service-account@project.iam.gserviceaccount.com"
export GOOGLE_AUTH_PRIVATE_KEY="-----BEGIN PRIVATE KEY-----\nMIIE..."
export GOOGLE_VERTEX_PROJECT="your-project-id"
export GOOGLE_VERTEX_LOCATION="us-central1"
# Required
OPENAI_API_KEY="sk-your-openai-api-key"
# Optional
OPENAI_MODEL="gpt-4o" # Default model to use
# Required
AWS_ACCESS_KEY_ID="your-aws-access-key"
AWS_SECRET_ACCESS_KEY="your-aws-secret-key"
# Optional
AWS_REGION="us-east-2" # Default: us-east-2
AWS_SESSION_TOKEN="your-session-token" # Required for temporary credentials
BEDROCK_MODEL_ID="anthropic.claude-3-7-sonnet-20250219-v1:0" # Default model
# Required (choose one authentication method)
# Method 1: Service Account File
GOOGLE_APPLICATION_CREDENTIALS="/path/to/service-account.json"
# Method 2: Service Account JSON String
GOOGLE_SERVICE_ACCOUNT_KEY='{"type":"service_account",...}'
# Method 3: Individual Environment Variables
GOOGLE_AUTH_CLIENT_EMAIL="service-account@project.iam.gserviceaccount.com"
GOOGLE_AUTH_PRIVATE_KEY="-----BEGIN PRIVATE KEY-----\nMIIE..."
# Required for all methods
GOOGLE_VERTEX_PROJECT="your-gcp-project-id"
# Optional
GOOGLE_VERTEX_LOCATION="us-east5" # Default: us-east5
VERTEX_MODEL_ID="claude-sonnet-4@20250514" # Default model
# Provider Selection (optional)
DEFAULT_PROVIDER="bedrock" # Primary provider preference
FALLBACK_PROVIDER="openai" # Fallback provider
# Application Settings
PUBLIC_APP_ENVIRONMENT="dev" # dev, staging, production
ENABLE_STREAMING="true" # Enable streaming responses
ENABLE_FALLBACK="true" # Enable automatic fallback
# Debug and Logging
NEUROLINK_DEBUG="true" # Enable debug logging
LOG_LEVEL="info" # error, warn, info, debug
# Copy this to your .env file and fill in your credentials
# OpenAI
OPENAI_API_KEY=sk-your-openai-key-here
OPENAI_MODEL=gpt-4o
# Amazon Bedrock
AWS_ACCESS_KEY_ID=your-aws-access-key
AWS_SECRET_ACCESS_KEY=your-aws-secret-key
AWS_REGION=us-east-2
BEDROCK_MODEL_ID=anthropic.claude-3-7-sonnet-20250219-v1:0
# Google Vertex AI (choose one method)
# Method 1: File path
GOOGLE_APPLICATION_CREDENTIALS=/path/to/your/service-account.json
# Method 2: JSON string (uncomment to use)
# GOOGLE_SERVICE_ACCOUNT_KEY={"type":"service_account","project_id":"your-project",...}
# Method 3: Individual variables (uncomment to use)
# GOOGLE_AUTH_CLIENT_EMAIL=service-account@your-project.iam.gserviceaccount.com
# GOOGLE_AUTH_PRIVATE_KEY="-----BEGIN PRIVATE KEY-----\nYOUR_PRIVATE_KEY_HERE\n-----END PRIVATE KEY-----"
# Required for all Google Vertex AI methods
GOOGLE_VERTEX_PROJECT=your-gcp-project-id
GOOGLE_VERTEX_LOCATION=us-east5
VERTEX_MODEL_ID=claude-sonnet-4@20250514
# Application Settings
DEFAULT_PROVIDER=auto
ENABLE_STREAMING=true
ENABLE_FALLBACK=true
NEUROLINK_DEBUG=false
import { AIProviderFactory } from '@juspay/neurolink';
// Environment-based provider selection
const isDev = process.env.NODE_ENV === 'development';
const provider = isDev
? AIProviderFactory.createProvider('openai', 'gpt-4o-mini') // Cheaper for dev
: AIProviderFactory.createProvider('bedrock', 'claude-3-7-sonnet'); // Production
// Multiple providers for different use cases
const providers = {
creative: AIProviderFactory.createProvider('openai', 'gpt-4o'),
analytical: AIProviderFactory.createProvider('bedrock', 'claude-3-7-sonnet'),
fast: AIProviderFactory.createProvider('vertex', 'gemini-2.5-flash')
};
async function generateCreativeContent(prompt: string) {
return await providers.creative.generateText({
prompt,
temperature: 0.9,
maxTokens: 2000
});
}
const cache = new Map<string, { text: string; timestamp: number }>();
const CACHE_DURATION = 5 * 60 * 1000; // 5 minutes
async function cachedGenerate(prompt: string) {
const key = prompt.toLowerCase().trim();
const cached = cache.get(key);
if (cached && Date.now() - cached.timestamp < CACHE_DURATION) {
return { ...cached, fromCache: true };
}
const provider = createBestAIProvider();
const result = await provider.generateText({ prompt });
cache.set(key, { text: result.text, timestamp: Date.now() });
return { text: result.text, fromCache: false };
}
async function processBatch(prompts: string[]) {
const provider = createBestAIProvider();
const chunkSize = 5;
const results = [];
for (let i = 0; i < prompts.length; i += chunkSize) {
const chunk = prompts.slice(i, i + chunkSize);
const chunkResults = await Promise.allSettled(
chunk.map(prompt => provider.generateText({ prompt, maxTokens: 500 }))
);
results.push(...chunkResults);
// Rate limiting
if (i + chunkSize < prompts.length) {
await new Promise(resolve => setTimeout(resolve, 1000));
}
}
return results.map((result, index) => ({
prompt: prompts[index],
success: result.status === 'fulfilled',
result: result.status === 'fulfilled' ? result.value : result.reason
}));
}
ValidationException: Your account is not authorized to invoke this API operation.
bedrock:InvokeModel permissionsError: Cannot find API key for OpenAI provider
Cannot find package '@google-cloud/vertexai' imported from...
npm install @google-cloud/vertexaiThe security token included in the request is expired
import { createBestAIProvider } from '@juspay/neurolink';
async function robustGenerate(prompt: string, maxRetries = 3) {
let attempt = 0;
while (attempt < maxRetries) {
try {
const provider = createBestAIProvider();
return await provider.generateText({ prompt });
} catch (error) {
attempt++;
console.error(`Attempt ${attempt} failed:`, error.message);
if (attempt >= maxRetries) {
throw new Error(`Failed after ${maxRetries} attempts: ${error.message}`);
}
// Exponential backoff
await new Promise(resolve =>
setTimeout(resolve, Math.pow(2, attempt) * 1000)
);
}
}
}
async function generateWithFallback(prompt: string) {
const providers = ['bedrock', 'openai', 'vertex'];
for (const providerName of providers) {
try {
const provider = AIProviderFactory.createProvider(providerName);
return await provider.generateText({ prompt });
} catch (error) {
console.warn(`${providerName} failed:`, error.message);
if (error.message.includes('API key') || error.message.includes('credentials')) {
console.log(`${providerName} not configured, trying next...`);
continue;
}
}
}
throw new Error('All providers failed or are not configured');
}
// Provider not configured
if (error.message.includes('API key')) {
console.error('Provider API key not set');
}
// Rate limiting
if (error.message.includes('rate limit')) {
console.error('Rate limit exceeded, implement backoff');
}
// Model not available
if (error.message.includes('model')) {
console.error('Requested model not available');
}
// Network issues
if (error.message.includes('network') || error.message.includes('timeout')) {
console.error('Network connectivity issue');
}
Choose Right Models for Use Case
// Fast responses for simple tasks
const fast = AIProviderFactory.createProvider('vertex', 'gemini-2.5-flash');
// High quality for complex tasks
const quality = AIProviderFactory.createProvider('bedrock', 'claude-3-7-sonnet');
// Cost-effective for development
const dev = AIProviderFactory.createProvider('openai', 'gpt-4o-mini');
Streaming for Long Responses
// Use streaming for better UX on long content
const result = await provider.streamText({
prompt: "Write a detailed article...",
maxTokens: 2000
});
Appropriate Token Limits
// Set reasonable limits to control costs
const result = await provider.generateText({
prompt: "Summarize this text",
maxTokens: 150 // Just enough for a summary
});
We welcome contributions! Here's how to get started:
git clone https://github.com/juspay/neurolink
cd neurolink
pnpm install
pnpm test # Run all tests
pnpm test:watch # Watch mode
pnpm test:coverage # Coverage report
pnpm build # Build the library
pnpm check # Type checking
pnpm lint # Lint code
MIT © Juspay Technologies
Built with ❤️ by Juspay Technologies
FAQs
Universal AI Development Platform with working MCP integration, multi-provider support, and professional CLI. Built-in tools operational, 58+ external MCP servers discoverable. Connect to filesystem, GitHub, database operations, and more. Build, test, and
We found that @juspay/neurolink demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 7 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
A safer, faster way to eliminate vulnerabilities without updating dependencies
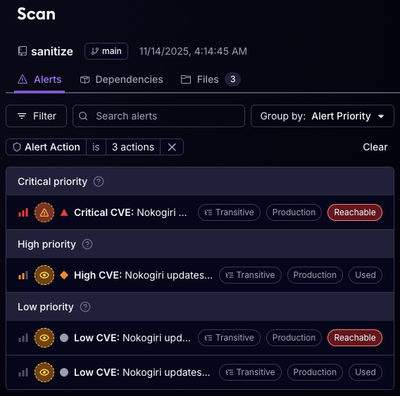
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.