
Research
PyPI Package Impersonates SymPy to Deliver Cryptomining Malware
Malicious PyPI package sympy-dev targets SymPy users, a Python symbolic math library with 85 million monthly downloads.
By Kirill Boychenko - Jan 21, 2026
@posthog/plugin-server
Advanced tools

![]()
This service takes care of processing events with plugins and more.
Let's get you developing the plugin server in no time:
Install dependencies and prepare for takeoff by running command yarn.
Start a development instance of PostHog. After all, this is the PostHog Plugin Server, and it works in conjuction with the main server. To avoid interference, disable the plugin server there with setting the PLUGIN_SERVER_IDLE env variable before running. PLUGIN_SERVER_IDLE=true ./bin/start
Make sure that the plugin server is configured correctly (see Configuration). Two settings that you MUST get right are DATABASE_URL and REDIS_URL - they need to be identical between the plugin server and the main server.
If developing the enterprise Kafka + ClickHouse pipeline, set KAFKA_ENABLED to true and provide KAFKA_HOSTS plus CLICKHOUSE_HOST, CLICKHOUSE_DATABASE, CLICKHOUSE_USER, andCLICKHOUSE_PASSWORD.
Otherwise if developing the basic Redis + Postgres pipeline, skip ahead.
Start the plugin server in autoreload mode with yarn start, or in compiled mode with yarn build && yarn start:dist, and develop away!
Run Postgres pipeline tests with yarn test:postgres:{1,2}. Run ClickHouse pipeline tests with yarn test:clickhouse:{1,2}. Run benchmarks with yarn benchmark.
There's a multitude of settings you can use to control the plugin server. Use them as environment variables.
| Name | Description | Default value |
|---|---|---|
| DATABASE_URL | Postgres database URL | 'postgres://localhost:5432/posthog' |
| REDIS_URL | Redis store URL | 'redis://localhost' |
| BASE_DIR | base path for resolving local plugins | '.' |
| WORKER_CONCURRENCY | number of concurrent worker threads | 0 – all cores |
| TASKS_PER_WORKER | number of parallel tasks per worker thread | 10 |
| REDIS_POOL_MIN_SIZE | minimum number of Redis connections to use per thread | 1 |
| REDIS_POOL_MAX_SIZE | maximum number of Redis connections to use per thread | 3 |
| SCHEDULE_LOCK_TTL | how many seconds to hold the lock for the schedule | 60 |
| CELERY_DEFAULT_QUEUE | Celery outgoing queue | 'celery' |
| PLUGINS_CELERY_QUEUE | Celery incoming queue | 'posthog-plugins' |
| PLUGINS_RELOAD_PUBSUB_CHANNEL | Redis channel for reload events | 'reload-plugins' |
| CLICKHOUSE_HOST | ClickHouse host | 'localhost' |
| CLICKHOUSE_DATABASE | ClickHouse database | 'default' |
| CLICKHOUSE_USER | ClickHouse username | 'default' |
| CLICKHOUSE_PASSWORD | ClickHouse password | null |
| CLICKHOUSE_CA | ClickHouse CA certs | null |
| CLICKHOUSE_SECURE | whether to secure ClickHouse connection | false |
| KAFKA_ENABLED | use Kafka instead of Celery to ingest events | false |
| KAFKA_HOSTS | comma-delimited Kafka hosts | null |
| KAFKA_CONSUMPTION_TOPIC | Kafka incoming events topic | 'events_plugin_ingestion' |
| KAFKA_CLIENT_CERT_B64 | Kafka certificate in Base64 | null |
| KAFKA_CLIENT_CERT_KEY_B64 | Kafka certificate key in Base64 | null |
| KAFKA_TRUSTED_CERT_B64 | Kafka trusted CA in Base64 | null |
| KAFKA_PRODUCER_MAX_QUEUE_SIZE | Kafka producer batch max size before flushing | 20 |
| KAFKA_FLUSH_FREQUENCY_MS | Kafka producer batch max duration before flushing | 500 |
| KAFKA_MAX_MESSAGE_BATCH_SIZE | Kafka producer batch max size in bytes before flushing | 900000 |
| DISABLE_WEB | whether to disable web server | true |
| WEB_PORT | port for web server to listen on | 3008 |
| WEB_HOSTNAME | hostname for web server to listen on | '0.0.0.0' |
| LOG_LEVEL | minimum log level | LogLevel.Info |
| SENTRY_DSN | Sentry ingestion URL | null |
| STATSD_HOST | StatsD host - integration disabled if this is not provided | null |
| STATSD_PORT | StatsD port | 8125 |
| STATSD_PREFIX | StatsD prefix | 'plugin-server.' |
| DISABLE_MMDB | whether to disable MMDB IP location capabilities | false |
| INTERNAL_MMDB_SERVER_PORT | port of the internal server used for IP location (0 means random) | 0 |
| DISTINCT_ID_LRU_SIZE | size of persons distinct ID LRU cache | 10000 |
| PLUGIN_SERVER_IDLE | whether to disengage the plugin server, e.g. for development | false |
It's magic! Just bump up version in package.json on the main branch and the new version will be published automatically, with a matching PR to the main PostHog repo created.
You can also use a bump patch/minor/major label on a PR - this will do the above for you when the PR is merged.
Courtesy of GitHub Actions.
The story begins with pluginServer.ts -> startPluginServer, which is the main thread of the plugin server.
This main thread spawns 4 worker threads, managed using Piscina. Each worker thread runs 10 tasks.1
Let's talk about the main thread first. This has:
pubSub: a Redis powered pubSub mechanism for reloading plugins whenever a message is published by the main PostHog app.
server: sets up connections to required DBs and queues(clickhouse, Kafka, Postgres, Redis), via server.ts -> createServer. This is a shared setup between the main and worker threads
fastifyInstance: sets up a web server. Unused for now, but may be used for enabling webhooks in the future.
piscina: this is the thread manager. makePiscina creates the manager, while createWorker creates the worker threads.
scheduleControl: The scheduled job controller. Responsible for adding piscina tasks for scheduled jobs, when the time comes.
The schedule information makes it into server.pluginSchedule via vm.ts -> createPluginConfigVM -> __tasks, which parses for runEvery* tasks, and
then used in src/workers/plugins/setup.ts -> loadSchedule. More about the vm internals in a bit.
jobQueueConsumer: The internal job queue consumer. This enables retries, scheduling jobs in the future (once) (Note: this is the difference between scheduleControl and this internal jobQueue). While scheduleControl is triggered via runEveryMinute, runEveryHour tasks, the jobQueueConsumer deals with meta.jobs.doX(event).runAt(new Date()).
Enqueuing jobs is managed by job-queue-manager.ts, which is backed by a Graphile-worker (graphile-queue.ts)
queue: Wait, another queue?
Side Note about Queues:
Yes, there are a LOT of queues. Each of them serve a separate function. The one we've seen already is the graphile job queue. This is the internal one dealing with job.runAt() tasks.
Then, there's the main ingestion queue, which sends events from PostHog to the plugin server. This is a Celery (backed by Redis) or Kafka queue, depending on the setup (Enterprise/high event volume is Kafka). These are consumed by the queue above, and sent off to the Piscina workers (src/main/ingestion-queues/queue.ts -> ingestEvent). Since all of the "real" stuff happens inside the worker threads, you'll find the specific ingestion code there (src/worker/ingestion/ingest-event.ts). This finally writes things into Postgres.
It's also a good idea to see the producer side of this ingestion queue, which comes from Posthog/posthog/api/capture.py. There's several tasks in this queue, and our plugin server is only interested in one kind of task: posthog.tasks.process_event.process_event_with_plugins.
That's all for the main thread. Onto the workers now: It all begins with worker.ts and createWorker()
server is the same DB connections setup as in the main thread.
What's new here is setupPlugins and createTaskRunner.
setupPlugins: Does loadPluginsFromDB and then loadPlugins (which creates VMs lazily for each plugin+team). TeamID represents a company using plugins, and each team can have it's own set of plugins enabled. The PluginConfig shows which team the config belongs to, the plugin to run, and the VM to run it in.
createTaskRunner: There's some excellent wizardry happening here. makePiscina of piscina.js sets up the workers to run the existing file itself (using __filename in the setup config, returning createWorker(). This createWorker() is a function returning createTaskRunner, which is a curried function, which given {task, args}, returns workerTasks[task](server, args). These worker tasks are available in src/worker/tasks.ts.
TODO: what happens with getPLuginRows, getPluginConfigRows and SetupPlugins.
Q: Where is teamID populated? At event creation time? (in posthog/posthog? row.pk)
TODO
1: What are tasks? - TASKS_PER_WORKER - a Piscina setting (https://github.com/piscinajs/piscina#constructor-new-piscinaoptions) -> concurrentTasksPerWorker
FAQs
PostHog Plugin Server
The npm package @posthog/plugin-server receives a total of 1,561 weekly downloads. As such, @posthog/plugin-server popularity was classified as popular.
We found that @posthog/plugin-server demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 8 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
Malicious PyPI package sympy-dev targets SymPy users, a Python symbolic math library with 85 million monthly downloads.
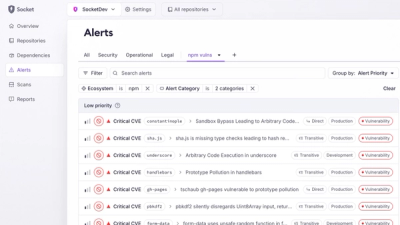
Product
Create and share saved alert views with custom tabs on the org alerts page, making it easier for teams to return to consistent, named filter sets.

Product
Socket’s Rust and Cargo support is now generally available, providing dependency analysis and supply chain visibility for Rust projects.