sanity-plugin-page-tree
This is a Sanity Studio v3 plugin.
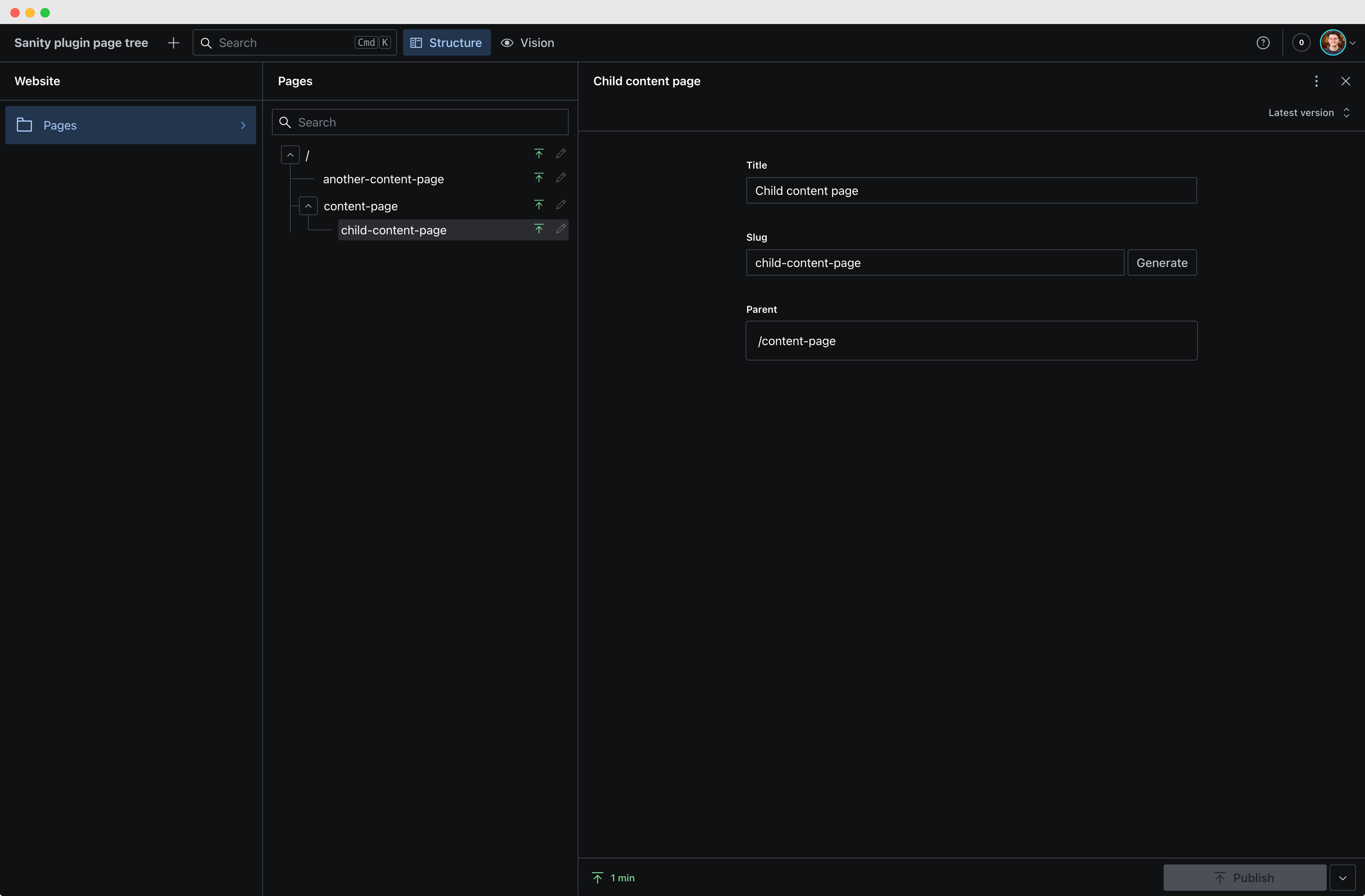
Why?
In many example projects for headless CMSs in general, they typically create a post content type with a property like "slug" and serve the post on a route such as /posts/:slug. This becomes more complex when dealing with multiple page types and a desire to establish a dynamic page tree.
Consider having three different content types: a home page, an overview page, and a content page, and aiming to create the following URL structure:
/ Homepage/about-us Overview Page/about-us/team Content Page/what-we-do Content Page/what-we-do/cases Overview Page/what-we-do/cases/:slug Content Page
Achieving this can be challenging, especially if all the slugs need to be dynamic and editable in the CMS. This package aims to make this easy by providing a page tree view for creating and editing pages. It also includes a page tree input for creating internal page links and methods designed for use on the frontend, helping you effectively resolve urls to ids (in order to retrieve the right content for a route) and vice versa (to resolve internal page links to urls).
Installation
npm i @q42/sanity-plugin-page-tree
Usage in Sanity Studio
Create a page tree config
Create a shared page tree config file and constant to use in your page types and desk structure.
import { PageTreeConfig } from '@q42/sanity-plugin-page-tree';
export const pageTreeConfig: PageTreeConfig = {
rootSchemaType: 'homePage',
pageSchemaTypes: ['homePage', 'contentPage', 'contentChildPage'],
allowedParents: {
contentChildPage: ['contentPage'],
},
apiVersion: '2023-12-08',
titleFieldName: 'title',
baseUrl: 'https://example.com',
};
Create a page type
The definePageType function can be used to wrap your page schema types with the necessary fields (parent (page reference) and slug) for the page tree.
Root page (e.g. home page)
Provide the isRoot option to the definePageType function to mark the page as a root page. This page won't have a parent and slug field.
import { pageTreeConfig } from './page-tree-config';
const _homePageType = defineType({
name: 'homePage',
type: 'document',
title: 'Page',
fields: [
],
});
export const homePageType = definePageType(_homePageType, pageTreeConfig, {
isRoot: true,
});
Other pages (e.g. content page)
import { pageTreeConfig } from './pageTreeConfig';
const _contentPageType = defineType({
name: 'contentPage',
type: 'document',
title: 'Page',
fields: [
],
});
export const contentPageType = definePageType(_contentPageType, pageTreeConfig);
Add page tree to desk structure
Instead of using the default document list for creating and editing pages, you can use the createPageTreeDocumentList function to create a custom page tree document list view and add it to your desk structure.
import { pageTreeConfig } from './page-tree-config';
export const structure = (S: StructureBuilder) =>
S.list()
.title('Website')
.items([
S.listItem()
.title('Pages')
.child(
createPageTreeDocumentList(S, {
config: pageTreeConfig,
extendDocumentList: builder => builder.id('pages').title('Pages').apiVersion(pageTreeConfig.apiVersion),
}),
),
]);
Create internal page links
A link to an internal page is a reference to a page document. The PageTreeField component can be used to render a custom page tree input in the reference field.
import { pageTreeConfig } from './page-tree-config';
const linkField = defineField({
name: 'link',
title: 'Link',
type: 'reference',
to: pageTreeConfig.pageSchemaTypes.map(type => ({ type })),
components: {
field: props => PageTreeField({ ...props, config: pageTreeConfig }),
},
});
Document internationalization
This plugin supports the @sanity/document-internationalization plugin. To enable this, do the setup as documented in the plugin and additionally provide the documentInternationalization option to the page tree configuration file.
import { PageTreeConfig } from '@q42/sanity-plugin-page-tree';
export const pageTreeConfig: PageTreeConfig = {
...,
documentInternationalization: {
supportedLanguages: ['en', 'nl'],
languageField: 'locale',
}
};
Usage on the frontend
In order to retrieve the right content for a specifc route, you need to make "catch all" route. How this is implemented depends on the framework you are using. Below are some examples for a Next.JS and React single page appication using react router.
Regular client
In order to get the page data for the requested path you have to creat a client. Afterwards you can retrieve a list of all the pages with the resolved path and find the correct page metadata.
With this metadata you can retrieve the data of the document yourself.
import { createPageTreeClient } from '@q42/sanity-plugin-page-tree/client';
const pageTreeClient = createPageTreeClient({
config: pageTreeConfig,
client: sanityClient,
});
async function getPageForPath(path: string) {
const allPagesMetadata = await pageTreeClient.getAllPageMetadata();
const page = allPagesMetadata.find(page => page.path === path);
if (!page) {
return;
}
return page;
}
Next.JS Client
For users using the App Router of Next.JS with Server Components, we can benefit from the "Request Memoization" feature.
You can import the dedicated next client:
import { createNextPageTreeClient } from '@q42/sanity-plugin-page-tree/next';
This client provides you with some additional helper methods:
getPageMetadataById useful for retrieving the url when you have a reference to a pagegetPageMetadataByUrl useful for retrieving the id when you have the path
Examples
For full examples, see the following projects:
License
MIT © Q42
Develop & test
For local development and testing you need to link and watch the library and link it to any of the studio example projects.
The basic studio example project, located in examples/studio, is a good starting point.
Link & watch
- Run
npm install in the root directory to install the dependencies.
- Run
npm run link-watch in the root directory.
Example studio
- To run the example studio, go to the
examples/studio directory.
- Run
npx yalc add @q42/sanity-plugin-page-tree && npx yalc link @q42/sanity-plugin-page-tree && npm install
- Run
npm run dev
This plugin uses @sanity/plugin-kit
with default configuration for build & watch scripts.
See Testing a plugin in Sanity Studio
on how to run this plugin with hotreload in the studio.



