Product
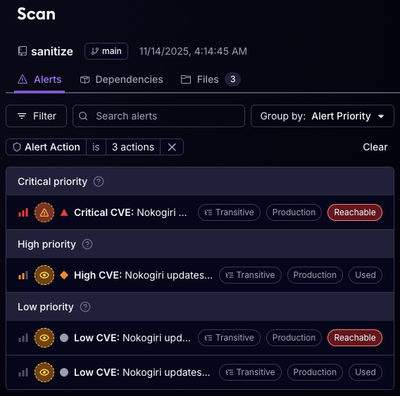
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
@stellarwp/archivist
Advanced tools
A Bun-based tool for archiving web content as LLM context using Pure.md API
![]()
![]()
A Bun-based TypeScript tool for archiving web content to use as LLM context. Uses Pure.md API to extract clean markdown from websites with intelligent file naming.
# Install globally with npm
npm install -g @stellarwp/archivist
# Or install globally with Bun
bun add -g @stellarwp/archivist
# Add to your project with npm
npm install @stellarwp/archivist
# Or add with Bun
bun add @stellarwp/archivist
git clone https://github.com/stellarwp/archivist.git
cd archivist
bun install
# Initialize configuration
archivist init
# Run the crawler
archivist crawl
# View help
archivist --help
When using Bun, the binary is not added to PATH automatically. You have several options:
# Option 1: Use bun run
bun run archivist init
bun run archivist crawl
# Option 2: Use bunx
bunx archivist init
bunx archivist crawl
# Option 3: Add to package.json scripts
# In your package.json:
{
"scripts": {
"archive": "archivist crawl",
"archive:init": "archivist init"
}
}
# Then run:
bun run archive
With npm, the binary is automatically available:
# Via npx
npx archivist init
npx archivist crawl
# Or if installed globally
archivist init
archivist crawl
Set up your Pure.md API key (optional but recommended):
export PURE_API_KEY=your_api_key_here
Initialize configuration:
# Global installation
archivist init
# As dependency with Bun
bun run archivist init
# As dependency with npm
npx archivist init
Edit archivist.config.json with your URLs
Run the crawler:
# Global installation
archivist crawl
# As dependency with Bun
bun run archivist crawl
# As dependency with npm
npx archivist crawl
{
"archives": [
{
"name": "Example Site Archive",
"sources": [
{
"url": "https://example.com",
"name": "Example Site",
"depth": 1
}
],
"output": {
"directory": "./archive/example",
"format": "markdown",
"fileNaming": "url-based"
}
}
],
"crawl": {
"maxConcurrency": 3,
"delay": 1000,
"userAgent": "Archivist/0.1.0-beta.6",
"timeout": 30000
},
"pure": {
"apiKey": "your-api-key-here"
}
}
Each archive in the archives array has:
Sources can be:
"https://example.com""explorer" (default) or "pagination"markdown, html, or jsonurl-based, title-based, or hash-basedFor more complete examples, check out the examples directory.
{
"archives": [
{
"name": "API Documentation",
"sources": [
"https://docs.example.com/api-reference",
"https://docs.example.com/tutorials"
],
"output": {
"directory": "./archive/api-docs",
"format": "markdown",
"fileNaming": "title-based"
}
}
],
"crawl": {
"maxConcurrency": 3,
"delay": 1000
}
}
{
"archives": [
{
"name": "Documentation Site",
"sources": {
"url": "https://docs.example.com",
"depth": 2
},
"output": {
"directory": "./archive/docs",
"format": "markdown",
"fileNaming": "url-based"
}
},
{
"name": "Blog Posts",
"sources": "https://blog.example.com",
"output": {
"directory": "./archive/blog",
"format": "json",
"fileNaming": "title-based"
}
}
],
"crawl": {
"maxConcurrency": 5,
"delay": 500
}
}
{
"archives": [
{
"name": "Technical Documentation",
"sources": [
{
"url": "https://docs.example.com/api",
"depth": 2
},
{
"url": "https://docs.example.com/guides",
"depth": 1
}
],
"output": {
"directory": "./archive/technical",
"format": "markdown",
"fileNaming": "url-based"
}
},
{
"name": "Blog Archive",
"sources": [
"https://blog.example.com/2024/01",
"https://blog.example.com/2024/02",
"https://blog.example.com/2024/03"
],
"output": {
"directory": "./archive/blog-2024",
"format": "json",
"fileNaming": "title-based"
}
}
],
"crawl": {
"maxConcurrency": 3,
"delay": 2000,
"userAgent": "Archivist/0.1.0-beta.6"
},
"pure": {
"apiKey": "your-api-key"
}
}
Use a page as a link collector to crawl all documentation pages:
{
"archives": [
{
"name": "API Reference",
"sources": {
"url": "https://docs.example.com/api/index",
"depth": 0,
"includePatterns": ["*/api/v1/*"]
},
"output": {
"directory": "./archive/api-reference",
"format": "markdown"
}
}
]
}
In this example:
/api/index is used only to collect linksdepth: 0 means the index page itself won't be archivedincludePatterns pattern will be crawledControl which links are followed during crawling with include and exclude patterns. Archivist supports both minimatch glob patterns (recommended) and regular expressions (for backward compatibility).
Use familiar glob patterns like those used in .gitignore files:
{
"archives": [
{
"name": "Filtered Documentation",
"sources": {
"url": "https://docs.example.com",
"depth": 2,
"includePatterns": [
"*/api/*", // Match any URL with /api/ in the path
"**/guide/**", // Match /guide/ at any depth
"*.html", // Match HTML files
"*.{md,mdx}" // Match .md or .mdx files
],
"excludePatterns": [
"*.pdf", // Exclude PDF files
"*/private/*", // Exclude /private/ paths
"**/test/**", // Exclude /test/ at any depth
"*/v1/*" // Exclude version 1 API
]
},
"output": {
"directory": "./archive/filtered-docs"
}
}
]
}
Common minimatch patterns:
* - Matches any string except path separators** - Matches any string including path separators? - Matches any single character[abc] - Matches any character in the brackets{a,b,c} - Matches any of the comma-separated patterns*.ext - Matches files with the specified extensionFor more complex matching, use regular expressions:
{
"archives": [
{
"name": "Filtered Documentation",
"sources": {
"url": "https://docs.example.com",
"depth": 2,
"includePatterns": [
"https://docs\\.example\\.com/api/.*",
"https://docs\\.example\\.com/guides/.*"
],
"excludePatterns": [
".*\\.pdf$",
".*/archive/.*",
".*/deprecated/.*"
]
},
"output": {
"directory": "./archive/filtered-docs"
}
}
]
}
"includePatterns": ["*.{html,htm,md,mdx}"],
"excludePatterns": ["*.{pdf,zip,mp4,avi}"]
"includePatterns": ["*/v2/*", "*/v3/*"],
"excludePatterns": ["*/v1/*", "*/beta/*", "*/deprecated/*"]
"includePatterns": ["https://docs.example.com/**", "https://api.example.com/**"],
"excludePatterns": ["https://blog.example.com/**"]
"includePatterns": [
"**/api/v[2-3]/*", // Minimatch: v2 or v3 API
"^https://docs\\.example\\.com/.*" // Regex: docs subdomain only
],
"excludePatterns": [
"*/internal/*", // Minimatch: exclude internal
".*\\.(pdf|zip)$" // Regex: exclude downloads
]
Pattern behavior:
Archivist supports different strategies for processing sources, allowing you to handle various website structures including paginated content.
The explorer strategy extracts all links from a page at once. This is the default behavior and ideal for:
{
"sources": {
"url": "https://docs.example.com/index",
"strategy": "explorer",
"linkSelector": "a.doc-link",
"includePatterns": ["*/api/*", "*/guides/*"]
}
}
The pagination strategy follows paginated content across multiple pages. Perfect for:
Use when page URLs follow a predictable pattern:
{
"sources": {
"url": "https://blog.example.com/posts",
"strategy": "pagination",
"pagination": {
"pagePattern": "https://blog.example.com/posts/page/{page}",
"startPage": 1,
"maxPages": 10
}
}
}
Use when pagination uses URL query parameters:
{
"sources": {
"url": "https://forum.example.com/topics",
"strategy": "pagination",
"pagination": {
"pageParam": "page",
"startPage": 1,
"maxPages": 20
}
}
}
Use when pages have "Next" or "Older Posts" links:
{
"sources": {
"url": "https://news.example.com/archive",
"strategy": "pagination",
"pagination": {
"nextLinkSelector": "a.next-page, a[rel='next']",
"maxPages": 50
}
}
}
{page} placeholder for page numbers{
"archives": [{
"name": "Tech Blog Archive",
"sources": {
"url": "https://techblog.example.com",
"strategy": "pagination",
"pagination": {
"pagePattern": "https://techblog.example.com/page/{page}",
"startPage": 1,
"maxPages": 25
},
"includePatterns": ["*/2024/*", "*/2023/*"],
"excludePatterns": ["*/draft/*"]
},
"output": {
"directory": "./archive/blog",
"format": "markdown"
}
}]
}
{
"archives": [{
"name": "API Reference",
"sources": {
"url": "https://api.example.com/docs/endpoints",
"strategy": "pagination",
"pagination": {
"pageParam": "offset",
"startPage": 0,
"maxPages": 10
}
},
"output": {
"directory": "./archive/api-docs",
"format": "json"
}
}]
}
{
"archives": [{
"name": "Support Forum",
"sources": {
"url": "https://forum.example.com/category/help",
"strategy": "pagination",
"pagination": {
"nextLinkSelector": "a.pagination-next",
"maxPages": 100
}
},
"output": {
"directory": "./archive/forum",
"format": "markdown"
}
}]
}
{
"archives": [{
"name": "Complete Documentation",
"sources": [
{
"url": "https://docs.example.com/index",
"strategy": "explorer",
"linkSelector": "nav a"
},
{
"url": "https://docs.example.com/changelog",
"strategy": "pagination",
"pagination": {
"pageParam": "page",
"maxPages": 5
}
}
],
"output": {
"directory": "./archive/docs"
}
}]
}
{
"archives": [{
"name": "Product Catalog",
"sources": {
"url": "https://shop.example.com/category/electronics",
"strategy": "pagination",
"pagination": {
"pageParam": "p",
"startPage": 1,
"maxPages": 50,
"perPageParam": "per_page"
}
},
"output": {
"directory": "./archive/products",
"format": "json"
}
}]
}
{
"archives": [{
"name": "Search Results Archive",
"sources": {
"url": "https://search.example.com/results?q=javascript",
"strategy": "pagination",
"pagination": {
"pageParam": "start",
"startPage": 0,
"maxPages": 20,
"pageIncrement": 10
}
},
"output": {
"directory": "./archive/search-results"
}
}]
}
{
"archives": [{
"name": "Forum Archive",
"sources": {
"url": "https://forum.example.com/category/general",
"strategy": "pagination",
"pagination": {
"pageParam": "offset",
"startPage": 0,
"maxPages": 100,
"pageIncrement": 20
},
"includePatterns": ["*/topic/*"],
"excludePatterns": ["*/user/*", "*/admin/*"]
},
"output": {
"directory": "./archive/forum"
}
}]
}
{
"archives": [{
"name": "News Archive",
"sources": {
"url": "https://news.example.com/latest",
"strategy": "pagination",
"pagination": {
"nextLinkSelector": "a.load-more-link, button.load-more[onclick*='href']",
"maxPages": 50
}
},
"output": {
"directory": "./archive/news",
"format": "markdown"
}
}]
}
{
"archives": [{
"name": "Photo Gallery",
"sources": {
"url": "https://gallery.example.com/photos",
"strategy": "pagination",
"pagination": {
"nextLinkSelector": "#infinite-scroll-next, .next-batch, noscript a[href*='batch']",
"maxPages": 100
}
},
"output": {
"directory": "./archive/gallery",
"format": "json"
}
}]
}
{
"archives": [{
"name": "API Documentation",
"sources": {
"url": "https://api.example.com/docs/reference",
"strategy": "pagination",
"pagination": {
"pageParam": "section",
"startPage": 1,
"maxPages": 10
}
},
"output": {
"directory": "./archive/api-docs"
}
}]
}
{
"archives": [{
"name": "Blog Archive 2024",
"sources": {
"url": "https://blog.example.com/2024/01",
"strategy": "pagination",
"pagination": {
"pagePattern": "https://blog.example.com/2024/01/page/{page}",
"startPage": 1,
"maxPages": 25
},
"includePatterns": ["*/2024/01/*"],
"excludePatterns": ["*/tag/*", "*/author/*"]
},
"output": {
"directory": "./archive/blog-2024-01"
}
}]
}
{
"archives": [{
"name": "Complex Site Archive",
"sources": {
"url": "https://complex.example.com/content",
"strategy": "pagination",
"pagination": {
"nextLinkSelector": "a.next, a[rel='next'], .pagination a:last-child, button.more",
"maxPages": 75
}
},
"output": {
"directory": "./archive/complex-site"
}
}]
}
Choose the Right Strategy:
pagePattern when URLs follow a predictable patternpageParam for query parameter-based paginationnextLinkSelector for following "Next" or "Load More" linksSelector Optimization:
Performance Considerations:
maxPages limits to avoid infinite loopsdelay between requests to respect rate limitsmaxConcurrency based on site capacityCommon Patterns:
pageParam: "offset" with pageIncrementpageParam: "page" or pageParam: "p"nextLinkSelector: "button.load-more, a.load-more"Debugging:
maxPages values during testingArchivist can be used programmatically in your Node.js/Bun applications:
import { initializeContainer, appContainer } from '@stellarwp/archivist';
import { WebCrawlerService, ConfigService } from '@stellarwp/archivist';
// Initialize the DI container
initializeContainer();
// Get services
const configService = appContainer.resolve(ConfigService);
const webCrawler = appContainer.resolve(WebCrawlerService);
// Initialize configuration
configService.initialize({
archives: [{
name: "My Archive",
sources: ["https://example.com"],
output: {
directory: "./output",
format: "markdown"
}
}],
crawl: {
maxConcurrency: 3,
delay: 1000
}
});
// Collect URLs first
await webCrawler.collectAllUrls();
// Display collected URLs
webCrawler.displayCollectedUrls();
// Start crawling
await webCrawler.crawlAll({ clean: true });
The main service for orchestrating web crawling operations.
Methods:
collectAllUrls(): Promise<void> - Collects URLs from all configured archivesdisplayCollectedUrls(): void - Displays collected URLs to consolecrawlAll(options?: { clean?: boolean }): Promise<void> - Crawls all collected URLsgetCollectedLinksReport(): string - Returns a summary report of collected linksManages application configuration.
Methods:
initialize(config: ArchivistConfig, configPath?: string): void - Initialize configurationgetArchives(): ArchiveConfig[] - Get all archive configurationsgetCrawlConfig(): CrawlConfig - Get crawl-specific settingsgetPureApiKey(): string | undefined - Get Pure.md API keyupdateConfig(updates: Partial<ArchivistConfig>): void - Update configurationTracks crawling state and progress.
Methods:
initializeArchive(archiveName: string): void - Initialize state for an archiveaddToQueue(archiveName: string, url: string): void - Add URL to crawl queuemarkVisited(archiveName: string, url: string): void - Mark URL as visitedgetTotalUrlCount(): number - Get total URL count across all archivesAs of v0.1.0-beta.7, Archivist will always collect and display all URLs before crawling, giving you a chance to review and confirm. This includes:
Collecting URLs from 1 archive(s)...
Collecting URLs for archive: Tech Blog Archive
----------------------------------------
Collecting from https://techblog.example.com (pagination strategy)
→ Found 150 URLs
Found 150 URLs to crawl:
==================================================
1. https://techblog.example.com/post/1
2. https://techblog.example.com/post/2
...
150. https://techblog.example.com/post/150
==================================================
Total URLs to be processed: 150
Do you want to proceed with the crawl? (yes/no):
This helps you:
# Initialize a new configuration file
archivist init
# Run the crawler with default config
archivist crawl
# Specify a custom config file
archivist crawl --config ./custom-config.json
# Override output directory
archivist crawl --output ./my-archive
# Override output format
archivist crawl --format json
# Provide Pure.md API key via CLI
archivist crawl --pure-key your_key_here
# Enable debug logging
archivist crawl --debug
# Dry run - only collect and display URLs without crawling
archivist crawl --dry-run
# Skip confirmation prompt
archivist crawl --no-confirm
# Clean output directories before crawling
archivist crawl --clean
# Clean and skip confirmation
archivist crawl --clean --no-confirm
Creates clean markdown files with metadata headers:
# Page Title
**URL:** https://example.com/page
**Crawled:** 2024-01-01T12:00:00Z
**Content Length:** 5432 characters
**Links Found:** 23
---
Page content here...
---
## Links
- https://example.com/link1
- https://example.com/link2
Structured data format for programmatic use:
{
"url": "https://example.com/page",
"title": "Page Title",
"content": "Page content...",
"metadata": {
"crawledAt": "2024-01-01T12:00:00Z",
"contentLength": 5432,
"links": ["https://example.com/link1", "..."]
}
}
Self-contained HTML with metadata:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
<meta name="source-url" content="https://example.com/page">
<meta name="crawled-at" content="2024-01-01T12:00:00Z">
</head>
<body>
<!-- Content with links preserved -->
</body>
</html>
example-com-docs-api.mdapi-reference-guide-a1b2c3d4.mdf47ac10b58cc4372.mdThis tool uses Pure.md API for clean content extraction when available:
When Pure.md is unavailable or fails, Archivist uses Cheerio for link discovery only:
Configure delays to respect rate limits:
{
"crawl": {
"delay": 10000 // 10 seconds between requests
}
}
Archivist can be used as a GitHub Action for automated archiving without needing to install dependencies.
- uses: stellarwp/archivist@action
with:
config-file: './archivist.config.json'
pure-api-key: ${{ secrets.PURE_API_KEY }}
Note: The GitHub Action requires a JSON config file instead of TypeScript.
See the GitHub Action documentation for detailed usage and examples.
The project also includes example workflows for automated archiving:
on:
schedule:
- cron: '0 2 * * *' # Daily at 2 AM UTC
workflow_dispatch:
jobs:
archive:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: stellarwp/archivist@action
with:
config-file: './archivist.config.json'
pure-api-key: ${{ secrets.PURE_API_KEY }}
For detailed development setup, working with forks, creating custom branches, and contributing guidelines, see our Development Guide.
# Clone and setup
git clone https://github.com/stellarwp/archivist.git
cd archivist
bun install
# Run tests (includes TypeScript type checking)
bun test
# Run only TypeScript type checking
bun run test:types
# Run tests without type checking
bun run test:only
# Run in development mode
bun run dev
archivist/
├── src/
│ ├── cli.ts # CLI entry point
│ ├── crawler.ts # Main crawler logic
│ ├── services/
│ │ └── pure-md.ts # Pure.md API client
│ └── utils/
│ ├── content-formatter.ts # Output formatting
│ ├── file-naming.ts # File naming strategies
│ └── markdown-parser.ts # Markdown parsing
├── tests/
│ ├── unit/ # Unit tests
│ └── integration/ # Integration tests
├── .github/workflows/
│ └── archive.yml # GitHub Actions workflow
├── archivist.config.ts # Configuration schema
└── package.json # Dependencies
delay in crawl settingsmaxConcurrencyselector option firstdepth: 0 to crawl only specific pagestimeout for slow sitesContributions are welcome! Please feel free to submit a Pull Request.
git checkout -b feature/amazing-feature)git commit -m 'feat: Add amazing feature')git push origin feature/amazing-feature)This project is licensed under the MIT License - see the LICENSE file for details.
FAQs
A Bun-based tool for archiving web content as LLM context using Pure.md API
We found that @stellarwp/archivist demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 3 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.