Product
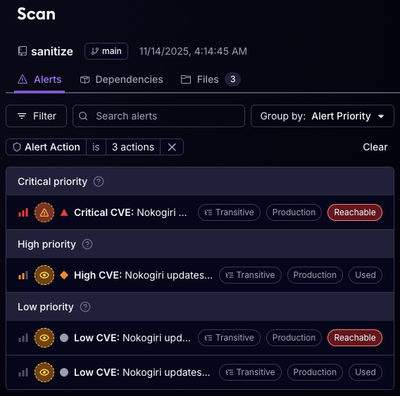
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
accessible-pipeline
Advanced tools

Accessibility on CI, made easy.
Some accessibility issues can be caught automatically. Things like correct labels, regions, and colour contrast are things that are important to a large amount of users. Still, keeping track of them can get out of hand. Even if a project is "made accessible" at one instant in time, there is no guarantee that issues will not creep back in. For those cases, automated accessibility checks can help!
Getting accessibility checks running consistently is hard. Well, not hard, but perhaps a mix of daunting and undocumented. This project tries to change that. We use the established AxE engine in Puppetteer, and we handle a lot of the crawling of pages. By providing a manifest of routes, and a starting URL, you should be able to get a good overview of your pages.
Furthermore, having a solid series of scripts does not say much about running it in CI. Documentation, automation, and concrete references are all things that we want to provide, to make setting up these checks straightforward.
You will need node and npm. Npm typically comes installed with Node. We recommend using a version manager to install node. It makes working in different projects easier.
If you want to dive into the code and develop changes, please refer to the Development section.
If you want to run the module (for example, to check a website), then follow the instructions here.
Install the package:
npx is a utility provided by npm, that allows you to run scripts directly, without installing them globally. If you have npm installed, you most likely have npx already.
In a terminal, run:
npx accessible-pipeline run https://example.com --ci
After the script is done, you can view the report:
npx accessible-pipeline view --file report-XYZ.json
npm install -g accessible-pipeline
Run the crawler with a url:
accessible-pipeline run https://example.com --ci
View a stored report:
accessible-pipeline view --file report-XYZ.json
By default, a maximum of 20 pages are crawled, to avoid accidentally bombing a site. Be careful not to set this value too high.
To change the maximum number of pages crawled to 40:
accessible-pipeline run https://example.com --pageLimit 40
The Report is a JSON list of the AxE results. Each entry has a list of violations, passes etc. It also has a url.
You can use this JSON file to output to any final format you want. The example one uses the CLI, but you could also build a static site on top of that, or serve it with a server as an API.
If you want to inspect which pages where visited, and what the options were, the program outputs its state as state-{POSIX_TIME}.json. It gives a good overview, and could be used to pin down bugs or new heuristics.
Generally, if you want to debug some state and errors consider running without the reporter, by specifying --ci. This will give you the "raw" output JSON on the console.
You can also set the logging level with LOG_LEVEL. The default is "info", which outputs operational information. Consider debug or trace to get more insight into the various loops and decisions:
LOG_LEVEL=debug accessible-pipeline run https://example.com --ci
If you are running with --ci (but not --streaming, which relies on the JSON console log) and want a more readable console output, then you can specify DEBUG_LOG_PRETTY=true on the cli.
This can be useful if you are trying to debug a specific page on your own machine:
# Will have more human-readable output, but not the reporter
DEBUG_LOG_PRETTY=true accessible-pipeline run https://example.com --ci
# Will exit with an error, because --streaming is meant to forward the logs somewhere for a computer to parse, and it would be undefined behaviour
DEBUG_LOG_PRETTY=true accessible-pipeline run https://example.com --ci --streaming
Make sure you follow the Getting Started instructions above.
Then, clone this repository on GitHub.
Finally, you can install the local dependencies, and run the tests:
npm ci
npm test
When developing, it might help to run tests in watch mode:
npm test -- --watch
The main source files are found under src/. You can read the architecture notes below, to learn more about where everything goes.
runviewThey are made to be independent.
You can pipe one into the other, communicating with a common format via --streaming:
accessible-pipeline run https://example.com --ci --streaming | accessible-pipeline view --streaming
Adding --ci to run means that it will run without a "pretty" reporter, and rather output the raw console logs (formatted as NDJSON, using pino).
On the other hand, if you run run standalone (without --ci), then we assume that you might be interested in a readable output. For that reason, the reporter (view) is integrated, essentially automating the commands above:
run is invokedrun --ci --streaming, and forwarding the other optionsview --streamingRegardless of how you invoke run, the final state and report are written to a file.
This allows you to consume the reports in other ways, such as by building a static site, running accessible-pipeline view --file, or however you wish!
The main documentation so far was about CLI use.
Typically, building things on top of the reports is possible by reading in the output report-xyz.json file.
For more integrated use cases, however, we also provide a programmatic API.
It exposes the core run loop, without touching the filesystem.
You can use it via the runCore function:
import {runCore} from 'accessible-pipeline';
async function main() {
const url = new URL('https://example.com/');
const {results, state} = await runCore(url, {
/* Options */
});
// Some time later...
// Do something with results here
}
You can find a full example under examples/programmatic-use.js;
Where the types are:
async function runCore(
rootURL: URL,
opts: Options
): Promise<{
results: AxeResults[];
state: State;
}>;
type Options = {
/* The maximum number of pages to visit */
pageLimit: number;
/* The maximum number of retries for a failing page */
maxRetries?: number;
/* Whether to ignore links of the shape https://example.com#my-id */
ignoreFragmentLinks?: boolean;
/* A list of extensions to ignore, skipping pages */
ignoreExtensions?: Array<string>;
/* Wheter to ignore links of the shape https://example.com/?a=b */
ignoreQueryParams?: boolean;
/* A path to a route manifest file, used to de-duplicate visited pages and routes */
routeManifestPath?: string;
/* Whether to expose the streaming logging API, used for advanced, "live" reporters */
streaming?: boolean;
};
Our own main "CLI" runner, is written on top of runCore.
In the future, we might provide an async iterator API, that allows you to process each page of results as they come in, instead of having to wait for the full set.
We have a dedicated Contributing guide. If you are interested in contributing to the project, please read it and let us know!
Any person contributing to this project is required to abide by our Code of Conduct.
Thanks to Deque, for axe-core and axe-puppeteer
FAQs
Acessibility checks in CI, made easy
We found that accessible-pipeline demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.