Research
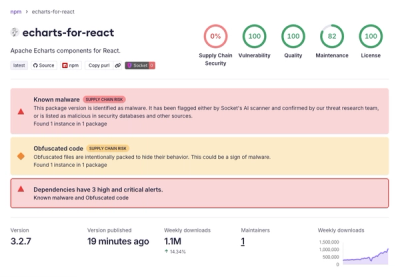
Active Supply Chain Attack Compromises @antv Packages on npm
Active npm supply chain attack compromises @antv packages in a fast-moving malicious publish wave tied to Mini Shai-Hulud.
By Socket Research Team - May 19, 2026
ai-gateway-lite
Advanced tools
Lightweight AI gateway for multi-provider routing, fallback, budget control and usage logging.
Lightweight AI gateway for Node.js — route requests across multiple LLM providers, failover automatically, control budgets, and log every call. Zero runtime dependencies.
![]()
![]()
English | 中文
If you're calling multiple LLM providers (OpenAI, Anthropic, OpenRouter, etc.) you need to solve the same problems every time:
ai-gateway-lite solves all four in a single, zero-dependency TypeScript library.
| Feature | Description |
|---|---|
| Multi-provider routing | Route by taskType, feature, userTier, or any combination. Priority-based matching. |
| Automatic fallback | Define fallback chains triggered by timeout, rate_limit, provider_error, or budget_exceeded. |
| Budget control | Per-request, hourly, daily, or monthly token/cost limits. Soft (warn) or hard (block) enforcement. |
| Streaming (SSE) | First-class chatStream() with AsyncIterable<StreamChunk> for all providers. |
| Cost estimation | Built-in pricing table for OpenAI & Anthropic models. Register custom model pricing. |
| Retry with backoff | Configurable per-provider retry with exponential backoff. Only retries on 429/502/503/504. |
| Config validation | Field-level validation on load with clear error paths. |
| Typed errors | GatewayError with kind, httpStatus, retryable flag, and automatic HTTP status classification. |
| Usage logging | Every request produces a structured UsageLog. Plug in your own handler. |
| Zero dependencies | Uses native fetch — no openai, @anthropic-ai/sdk, or other SDK required. |
npm install ai-gateway-lite
1. Set your API keys as environment variables (or load them however you prefer):
export OPENAI_API_KEY=sk-...
export ANTHROPIC_API_KEY=sk-ant-...
2. Create config files in your project (see Configuration for full schema):
your-project/
config/
gateway.providers.json
gateway.routes.json
gateway.budgets.json
3. Use it:
import { Gateway, loadConfig } from "ai-gateway-lite";
const config = await loadConfig("./config");
const gateway = new Gateway({
config,
onUsageLog: (log) => console.log(log),
});
const response = await gateway.chat({
messages: [{ role: "user", content: "Explain quantum computing in one sentence." }],
taskType: "chat",
});
console.log(response.content);
console.log(`Cost: $${response.estimatedCostUsd.toFixed(4)}`);
Or skip config files entirely and pass objects directly:
import { Gateway, loadConfigFromObjects } from "ai-gateway-lite";
const config = loadConfigFromObjects({
providers: [
{ name: "openai", provider: "openai", models: ["gpt-4o-mini"], auth: { type: "apiKey", envVar: "OPENAI_API_KEY" } },
],
routes: {
rules: [{ name: "default", priority: 0, match: {}, target: { provider: "openai" } }],
},
budgets: [],
});
const gateway = new Gateway({ config });
const res = await gateway.chat({ messages: [{ role: "user", content: "Hi!" }] });
const stream = await gateway.chatStream({
messages: [{ role: "user", content: "Write a haiku about TypeScript." }],
});
for await (const chunk of stream.stream) {
process.stdout.write(chunk.delta);
}
const summary = await stream.getUsageSummary();
console.log(`\n\nTokens: ${summary.totalTokens}, Cost: $${summary.estimatedCostUsd.toFixed(4)}`);
git clone https://github.com/your-username/ai-gateway-lite.git
cd ai-gateway-lite
npm install
cp .env.example .env # add your API keys
npm run demo
The server starts at http://localhost:3170 with three endpoints:
| Method | Path | Description |
|---|---|---|
POST | /v1/chat | Non-streaming chat completion |
POST | /v1/chat/stream | SSE streaming chat completion |
GET | /health | Health check + provider list |
curl -X POST http://localhost:3170/v1/chat \
-H "Content-Type: application/json" \
-d '{"messages":[{"role":"user","content":"Hello!"}],"taskType":"chat"}'
Three JSON files control the gateway behavior:
gateway.providers.json — Provider Registry[
{
"name": "openai-main",
"provider": "openai",
"models": ["gpt-4o", "gpt-4o-mini"],
"defaultModel": "gpt-4o-mini",
"timeoutMs": 30000,
"retry": { "maxAttempts": 2, "backoffMs": 1000 },
"auth": { "type": "apiKey", "envVar": "OPENAI_API_KEY" }
},
{
"name": "anthropic-main",
"provider": "anthropic",
"models": ["claude-sonnet-4-20250514"],
"defaultModel": "claude-sonnet-4-20250514",
"timeoutMs": 60000,
"auth": { "type": "apiKey", "envVar": "ANTHROPIC_API_KEY" }
}
]
gateway.routes.json — Routing Rules & Fallback Chains{
"rules": [
{
"name": "premium-complex",
"priority": 100,
"match": { "taskType": "complex", "userTier": "premium" },
"target": {
"provider": "anthropic-main",
"model": "claude-sonnet-4-20250514",
"fallbackChain": "complex-fallback"
}
},
{
"name": "default-chat",
"priority": 10,
"match": {},
"target": { "provider": "openai-main", "model": "gpt-4o-mini" }
}
],
"fallbackChains": [
{
"name": "complex-fallback",
"steps": [
{ "provider": "anthropic-main" },
{ "provider": "openai-main", "model": "gpt-4o", "when": ["timeout", "provider_error"] },
{ "provider": "openrouter-fallback", "when": ["timeout", "rate_limit", "provider_error"] }
]
}
]
}
gateway.budgets.json — Budget Policies[
{
"name": "global-daily",
"scope": { "type": "global" },
"window": "day",
"limits": { "maxTotalTokens": 1000000, "maxCostUsd": 10.0, "warnAt": 0.8 },
"enforcement": "hard"
}
]
Request → Match rules (by taskType / feature / userTier)
→ Pick highest-priority match
→ Resolve provider + model
→ If fallback chain defined:
Try step 1 → fail? → classify error
→ Try step 2 (if trigger matches `when`) → ...
→ Budget check (pre-call) → Execute → Budget record (post-call)
→ Log UsageLog → Return GatewayResponse
Gatewayconst gateway = new Gateway({
config: GatewayConfig,
onUsageLog?: (log: UsageLog) => void,
customProviders?: Record<string, ProviderFactory>,
});
gateway.chat(request: GatewayRequest): Promise<GatewayResponse>
gateway.chatStream(request: GatewayRequest): Promise<GatewayStreamResponse>
gateway.listProviders(): string[]
GatewayRequestinterface GatewayRequest {
messages: ChatMessage[];
model?: string; // override route's model
taskType?: string; // routing dimension
feature?: string; // routing dimension
userTier?: string; // routing dimension
maxTokens?: number;
temperature?: number;
}
GatewayResponseinterface GatewayResponse {
requestId: string;
provider: string;
model: string;
content: string;
inputTokens: number;
outputTokens: number;
totalTokens: number;
estimatedCostUsd: number;
latencyMs: number;
fallbackTriggered: boolean;
fallbackFrom?: string;
}
import { Gateway, loadConfig } from "ai-gateway-lite";
import type { Provider, ProviderRequestOptions, ProviderResult } from "ai-gateway-lite";
class MyProvider implements Provider {
readonly name = "my-provider";
readonly family = "custom";
async chat(options: ProviderRequestOptions): Promise<ProviderResult> {
// your implementation
}
}
const gateway = new Gateway({
config: await loadConfig("./config"),
customProviders: {
custom: (config) => new MyProvider(),
},
});
import { registerModelPricing } from "ai-gateway-lite";
registerModelPricing("my-custom-model", {
inputPer1kTokens: 0.001,
outputPer1kTokens: 0.002,
});
import { GatewayError } from "ai-gateway-lite";
try {
await gateway.chat(request);
} catch (err) {
if (err instanceof GatewayError) {
console.log(err.kind); // "provider_timeout" | "provider_rate_limit" | "budget_exceeded" | ...
console.log(err.httpStatus); // 504, 429, etc.
console.log(err.retryable); // true/false
console.log(err.toJSON()); // serializable payload
}
}
src/
types/ Type definitions
providers/ Provider interface + OpenAI, Anthropic, OpenRouter adapters + retry logic
config/ Config loader + field-level validator
routing/ Route matcher + fallback chain executor
budget/ In-memory budget tracker + guard
pricing/ Model pricing table + cost estimator
logging/ Usage logger with pluggable handler
errors/ GatewayError with HTTP status classification
gateway.ts Main Gateway class
index.ts Public API exports
demo/
server.ts Local HTTP demo server
*.json Example configuration files
| Provider | Family | Streaming | Auth |
|---|---|---|---|
| OpenAI | openai | Yes | Bearer token via OPENAI_API_KEY |
| Anthropic | anthropic | Yes | x-api-key header via ANTHROPIC_API_KEY |
| OpenRouter | openrouter | Yes | Bearer token via OPENROUTER_API_KEY |
npm run typecheck # TypeScript strict check
npm test # Run all 84 tests
npm run test:watch # Watch mode
npm run build # Build JS bundle + declarations
npm run demo # Start demo server
FAQs
Lightweight AI gateway for multi-provider routing, fallback, budget control and usage logging.
We found that ai-gateway-lite demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Research
Active npm supply chain attack compromises @antv packages in a fast-moving malicious publish wave tied to Mini Shai-Hulud.
Security News
/Research
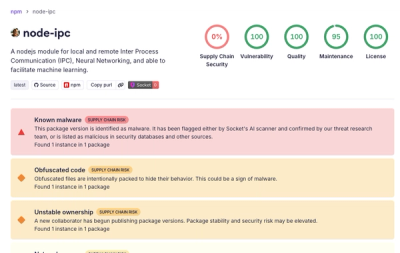
Socket detected malicious node-ipc versions with obfuscated stealer/backdoor behavior in a developing npm supply chain attack.

Security News
TeamPCP and BreachForums are promoting a Shai-Hulud supply chain attack contest with a $1,000 prize for the biggest package compromise.