Product
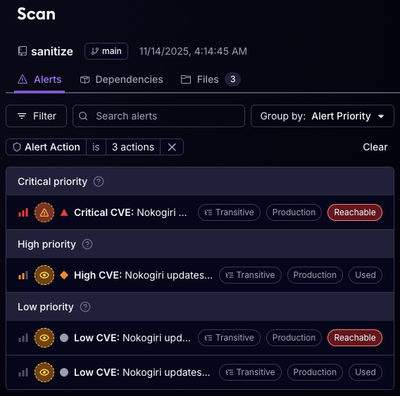
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
chinese-lexicon
Advanced tools
Chinese lexicon containing definitions, character origins, and statistics
This repository is a lexicon of Chinese combining the following features:
It can be installed using npm:
npm install chinese-lexicon
This project was built for and is used by Dong Chinese.
getEntries(word)Returns an array of dictionary entries for a Chinese word.
> getEntries("觉")
[
{
simp: '觉',
trad: '覺',
definitions: ['to feel', 'to find that', 'thinking', 'awake', 'aware'],
pinyin: 'jué',
searchablePinyin: 'jue',
simpEtymology: {
notes: 'Phonosemantic compound. 见 represents the meaning and 学 represents the sound. Simplified form of 學. Only the top part of 学 is used, which prevents the character from being too crowded.',
definition: 'think; perceive; sleep',
components: [/* ... */]
},
tradEtymology: {
notes: 'Phonosemantic compound. 見 represents the meaning and 學 represents the sound. Only the top part of 學 is used, which prevents the character from being too crowded.',
definition: 'think; perceive; sleep',
components: [/* ... */]
},
statistics: {
hskLevel: 1,
movieWordCount: 1125,
movieWordCountPercent: 0.00003353552422552613,
movieWordRank: 2200,
movieWordContexts: 880,
movieWordContextsPercent: 0.14095787281755567,
bookWordCount: 1408448,
bookWordCountPercent: 0.00008505090178761059,
bookWordRank: 1714,
movieCharCount: 81155,
movieCharCountPercent: 0.001732559764772375,
movieCharRank: 93,
movieCharContexts: 6180,
movieCharContextsPercent: 0.9899086977414705,
bookCharCount: 132041,
bookCharCountPercent: 0.0006823682596606341,
bookCharRank: 327,
pinyinFrequency: 1032
}
},
{
simp: '觉',
trad: '覺',
definitions: ['a nap', 'a sleep', 'CL:場|场[cháng]'],
pinyin: 'jiào',
searchablePinyin: 'jiao',
simpEtymology: {
// ...
},
tradEtymology: {
// ...
},
statistics: {
// ...
}
}
]
An entry object can have the following properties:
simp: The word in simplified characterstrad: The word in traditional charactersdefinitions: An array of definitions (comes from CC-CEDICT)pinyin: The pronunciation of the word in pinyinsearchablePinyin: The pinyin with the tones stripped out, used for text searchsimpEtymology: The etymology of the simplified character. See the getEtymology(character) section for details.tradEtymology: The etymology of the traditional character, if it is different from the simplified character.statistics: Numerical information about this word:
hskLevel: The HSK level (1-6) in which the characters in this word are introduced. 7 if the character is not in the HSK word list.movieWordCount: The number of instances of this word in the movie subtitles corpus SUBTLEX-CH.movieWordCountPercent: The movieWordCount divided by the total number of words in the movie subtitles corpus.movieWordRank: The frequency rank of this word in the movie subtitles. (e.g. a rank of 10 means it is the 10th most common word)movieWordContexts: The number of distinct movies that contain this word in the subtitles.movieWordContextsPercent: The movieWordContexts divided by the total number of movies in the corpus, i.e. the percentage of movies that contain this word.movieChar*: Same as movieWord* properties but for individual characters instead of words.bookWord* : Same as movieWord* properties, but using the BLCU Chinese Corpus for written text.bookChar*: Same as movieChar* properties, but using Jun Da's corpus of books.pinyinFrequency: The frequency of a certain pronunciation of a character, from the kHanyuPinlu field of the UniHan database. For example, 觉 is usually pronounced "jué" (1032), but sometimes pronounced "jiào" (179). The ratio of these mean that 觉 is pronounced as "jué" 1032 / 179 = 5.765 times as often as "jiào".getEtymology(character)Returns the etymology of a character.
> getEtymology("妈")
{
notes: 'Phonosemantic compound. 女 represents the meaning and 马 represents the sound. ',
definition: 'mother',
components: [{
type: 'meaning',
char: '女',
fragment: [0, 3]
},
{
type: 'sound',
char: '马',
fragment: [3]
}
]
}
The etymology object can have the following properties:
notes: General explanation of the origin and formation of the character.definition: Meaning of the charactercomponents: List of the individual parts of the character. Each component can have the following properties:
type: Type of component. Can be one of
meaning: hints at the meaning of the character, e.g. the 女 (woman) component in 妈 (mother)sound: hints at the sound of the character, e.g. the 马 (mǎ) component in 妈 (mā).iconic: pictographic or ideographic component, a picture or abstract representation of an idea, e.g. the hand (爪) picking fruit from a tree (木) in 采 (pick; pluck; gather)simplified: part of simplified character that abbreviates a traditional character to reduce the number of strokes, e.g. the 又 component in the simplified character 汉 is a shorthand of the 堇 component in the traditional character 漢.deleted: part of a traditional character that was deleted in the simplified version to reduce the number of strokes, e.g. the 門 component in the traditional character 開 was deleted to form the simplified character 开.unknown: the purpose of this component is not clear.images: SVG images of historical forms of the character, e.g. in oracle bone script, bronze script, or seal script.getGloss(word, pinyin?)Returns a single, short definition for a word.
> getGloss("香蕉")
"banana"
The optional pinyin argument can be used to disambiguate characters with multiple pronunciations (多音字).
> getGloss("发", "fā")
"to issue"
> getGloss("发", "fà")
"hair"
search(term, limit?)Does a text search to find dictionary entries matching the search term (such as an English word or pinyin). The search results will be sorted based on relevance and the frequency in books and movies.
> search("hello")
[
{
simp: '喂',
trad: '喂',
definitions: ['hello (when answering the phone)'],
pinyin: 'wéi',
// ...
},
{
simp: '你好',
trad: '你好',
definitions: ['hello', 'hi'],
pinyin: 'nǐhǎo',
// ...
},
// ...
]
The optional limit argument can be used to limit the number of search results returned.
allEntriesList of all the dictionary entries in the lexicon.
FAQs
Chinese lexicon containing definitions, character origins, and statistics
The npm package chinese-lexicon receives a total of 8 weekly downloads. As such, chinese-lexicon popularity was classified as not popular.
We found that chinese-lexicon demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.