
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025
chunk-text
Advanced tools
chunk/split a string by length without cutting/truncating words.
const out = chunk('hello world how are you?', 7);
/* ['hello', 'world', 'how are', 'you?'] */
$ npm install chunk-text
# yarn add chunk-text
All number values are parsed according to Number.parseInt.
const chunk = require('chunk-text');
Chunks the text string into an array of strings that each have a maximum length of chunkSize.
const out = chunk('hello world how are you?', 7);
/* ['hello', 'world', 'how are', 'you?'] */
If no space is detected before chunkSize is reached, then it will truncate the word to always
ensure the resulting text chunks have at maximum a length of chunkSize.
const out = chunk('hello world', 4);
/* ['hell', 'o', 'worl', 'd'] */
Chunks the text string into an array of strings that each have a maximum length of chunkSize, as determined by chunkOptions.charLengthMask.
The default behavior if chunkOptions.charLengthMask is excluded is equal to chunkOptions.charLengthMask=-1.
For single-byte characters, chunkOptions.charLengthMask never changes the results.
For multi-byte characters, chunkOptions.charLengthMask allows awareness of multi-byte glyphs according to the following table:
chunkOptions.charLengthMask | result |
|---|---|
| -1 | - same as default, same as chunkOptions.charLengthMask=1- each character counts as 1 towards length |
| 0 | - each character counts as the number of bytes it contains |
| >0 | - each character counts as the number of bytes it contains, up to a limit of chunkOptions.charLengthMask=N- a 7-byte ZWJ emoji such as runningPerson+ZWJ+femaleSymbol (🏃🏽♀️) counts as 2, when chunkOptions.charLengthMask=2 |
You can also substitute from the default chunkOptions.charLengthType property of length to TextEncoder.
This enables you to pass any object to chunkOptions.textEncoder which matches the signature, chunkOptions.textEncoder.encode(text).length
If your environment natively contains the TextEncoder prototype and chunkOptions.textEncoder isn't provided,
the module attempts new TextEncoder() in order to use this chunkOptions.charLengthType.
If
chunkOptions.charLengthType is set to TextEncoder.chunkOptions.textEncoder isn't provided.TextEncoder prototype isn't provided by the environment.Then
ReferenceError will occur.End If
// one woman runner emoji with a colour is seven bytes, or five characters
// RUNNER(2) + COLOUR(2) + ZJW + GENDER + VS15
// (actually encodes to 17)
const runner = '🏃🏽♀️';
const outDefault = chunk(runner+runner+runner, 4);
/* [ '🏃🏽♀️🏃🏽♀️🏃🏽♀️' ] */
const outZero = chunk(runner+runner+runner, 4, { charLengthMask: 0 });
/* [ '🏃🏽♀️', '🏃🏽♀️', '🏃🏽♀️' ] */
const outTwo = chunk(runner+runner+runner, 4, { charLengthMask: 2 });
/* [ '🏃🏽♀️🏃🏽♀️', '🏃🏽♀️' ] */
// FLAG + RAINBOW
// 2 each as length, 4 each as TextEncoder
// 4 as length, 8 as TextEncoder
// Node v14.5.0 does not provide TextEncoder natively.
const flags = '🏳️🌈🏳️🌈';
// \/ will fail if your environment doesn't already have TextEncoder prototype \/
chunk(flags, 8, { charLengthMask: 0, charLengthType: 'TextEncoder' });
// [ '🏳️🌈', '🏳️🌈' ]
// /\ will fail if your environment doesn't already have TextEncoder prototype /\
chunk(flags, 4, {
charLengthMask: 0,
charLengthType: 'TextEncoder',
textEncoder: new TextEncoder(),
})
// [ '🏳️🌈', '🏳️🌈' ]
chunk(flags, 999, {
charLengthMask: 0,
charLengthType: 'TextEncoder',
textEncoder: {
encode: () => ({ length: 999 }),
},
})
// [ '🏳️🌈', '🏳️🌈' ]
This library was created by Algolia to ease the optimizing of record payload sizes resulting in faster search responses from the API.
In general, there is always a unique large "content attribute" per record, and this packages will allow to chunk that content into small chunks of text.
The text chunks can then be distributed over multiple records.
Here is an example of how to split an existing record into several ones:
var chunk = require('chunk-text');
var record = {
post_id: 100,
content: 'A large chunk of text here'
};
var chunks = chunk(record.content, 600); // Limit the chunk size to a length of 600.
var records = [];
chunks.forEach(function(content) {
records.push(Object.assign({}, record, {content: content}));
});
FAQs
🔪 chunk/split a string by length without cutting/truncating words.
The npm package chunk-text receives a total of 2,404 weekly downloads. As such, chunk-text popularity was classified as popular.
We found that chunk-text demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 61 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
Product
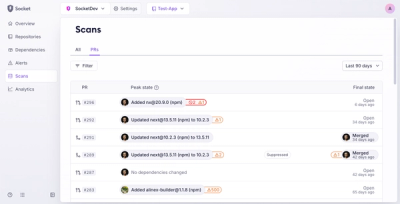
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
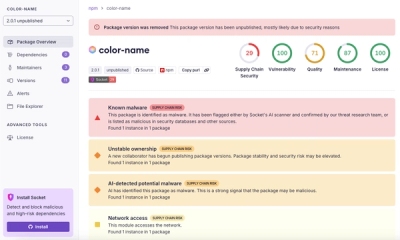
Research
/Security News
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.