Product
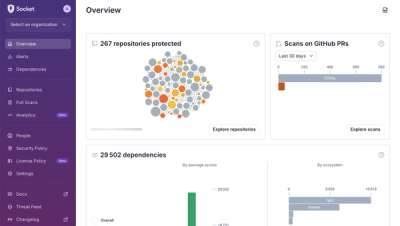
A New Overview in our Dashboard
We redesigned Socket's first logged-in page to display rich and insightful visualizations about your repositories protected against supply chain threats.
By André Staltz - Apr 29, 2025
Crawler is a web spider written with Nodejs. It gives you the full power of jQuery on the server to parse a big number of pages as they are downloaded, asynchronously



![]()
Most powerful, popular and production crawling/scraping package for Node, happy hacking :). Now we are looking for a logo design, which need your help!
Features:
Here is the CHANGELOG
$ npm install crawler
var Crawler = require("crawler");
var c = new Crawler({
maxConnections : 10,
// This will be called for each crawled page
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
// $ is Cheerio by default
//a lean implementation of core jQuery designed specifically for the server
console.log($("title").text());
}
done();
}
});
// Queue just one URL, with default callback
c.queue('http://www.amazon.com');
// Queue a list of URLs
c.queue(['http://www.google.com/','http://www.yahoo.com']);
// Queue URLs with custom callbacks & parameters
c.queue([{
uri: 'http://parishackers.org/',
jQuery: false,
// The global callback won't be called
callback: function (error, res, done) {
if(error){
console.log(error);
}else{
console.log('Grabbed', res.body.length, 'bytes');
}
done();
}
}]);
// Queue some HTML code directly without grabbing (mostly for tests)
c.queue([{
html: '<p>This is a <strong>test</strong></p>'
}]);
Use rateLimit to slow down when you are visiting web sites.
var crawler = require("crawler");
var c = new Crawler({
rateLimit: 1000, // `maxConnections` will be forced to 1
callback: function(err, res, done){
console.log(res.$("title").text());
done();
}
});
c.queue(tasks);//between two tasks, minimum time gap is 1000 (ms)
You can pass these options to the Crawler() constructor if you want them to be global or as items in the queue() calls if you want them to be specific to that item (overwriting global options)
This options list is a strict superset of mikeal's request options and will be directly passed to the request() method.
Basic request options:
uri: String The url you want to crawl.timeout : Number In milliseconds (Default 15000).Callbacks:
callback(error, res, done): Function that will be called after a request was completed
error: Errorres: http.IncomingMessage A response of standard IncomingMessage includes $ and options
res.statusCode: Number HTTP status code. E.G.200res.body: Buffer | String HTTP response content which could be a html page, plain text or xml document e.g.res.headers: Object HTTP response headersres.request: Request An instance of Mikeal's Request instead of http.ClientRequest
res.options: Options of this task$: jQuery Selector A selector for html or xml document.done: Function It must be called when you've done your work in callback.Schedule options:
maxConnections: Number Size of the worker pool (Default 10).rateLimit: Number Number of milliseconds to delay between each requests (Default 0).priorityRange: Number Range of acceptable priorities starting from 0 (Default 10).priority: Number Priority of this request (Default 5).Retry options:
retries: Number Number of retries if the request fails (Default 3),retryTimeout: Number Number of milliseconds to wait before retrying (Default 10000),Server-side DOM options:
jQuery: Boolean|String|Object Use cheerio with default configurations to inject document if true or "cheerio". Or use customized cheerio if an object with Parser options. Disable injecting jQuery selector if false. If you have memory leak issue in your project, use "whacko", an alternative parser,to avoid that. (Default true)Charset encoding:
forceUTF8: Boolean If true crawler will get charset from HTTP headers or meta tag in html and convert it to UTF8 if necessary. Never worry about encoding anymore! (Default true),incomingEncoding: String With forceUTF8: true to set encoding manually (Default null) so that crawler will not have to detect charset by itself. For example, incomingEncoding : 'windows-1255'. See all supported encodingsCache:
skipDuplicates: Boolean If true skips URIs that were already crawled, without even calling callback() (Default false). This is not recommended, it's better to handle outside Crawler use seenreqOther:
rotateUA: Boolean If true, userAgent should be an array and rotate it (Default false)
userAgent: String|Array, If rotateUA is false, but userAgent is an array, crawler will use the first one.
referer: String If truthy sets the HTTP referer header
options OptionsEmitted when a task is being added to scheduler.
crawler.on('schedule',function(options){
options.proxy = "http://proxy:port";
});
Emitted when limiter has been changed.
options OptionsEmitted when crawler is ready to send a request.
If you are going to modify options at last stage before requesting, just listen on it.
crawler.on('request',function(options){
options.qs.timestamp = new Date().getTime();
});
Emitted when queue is empty.
crawler.on('drain',function(){
// For example, release a connection to database.
db.end();// close connection to MySQL
});
Enqueue a task and wait for it to be executed.
Size of queue, read-only
Control rate limit for with limiter. All tasks submit to a limiter will abide the rateLimit and maxConnections restrictions of the limiter. rateLimit is the minimum time gap between two tasks. maxConnections is the maximum number of tasks that can be running at the same time. Limiters are independent of each other. One common use case is setting different limiters for different proxies. One thing is worth noticing, when rateLimit is set to a non-zero value, maxConnections will be forced to 1.
var crawler = require('crawler');
var c = new Crawler({
rateLimit: 2000,
maxConnections: 1,
callback: function(error, res, done) {
if(error) {
console.log(error)
} else {
var $ = res.$;
console.log($('title').text())
}
done();
}
})
// if you want to crawl some website with 2000ms gap between requests
c.queue('http://www.somewebsite.com/page/1')
c.queue('http://www.somewebsite.com/page/2')
c.queue('http://www.somewebsite.com/page/3')
// if you want to crawl some website using proxy with 2000ms gap between requests for each proxy
c.queue({
uri:'http://www.somewebsite.com/page/1',
limiter:'proxy_1',
proxy:'proxy_1'
})
c.queue({
uri:'http://www.somewebsite.com/page/2',
limiter:'proxy_2',
proxy:'proxy_2'
})
c.queue({
uri:'http://www.somewebsite.com/page/3',
limiter:'proxy_3',
proxy:'proxy_3'
})
c.queue({
uri:'http://www.somewebsite.com/page/4',
limiter:'proxy_1',
proxy:'proxy_1'
})
Crawler by default use Cheerio instead of JSDOM. JSDOM is more robust, if you want to use JSDOM you will have to require it require('jsdom') in your own script before passing it to crawler.
jQuery: true //(default)
//OR
jQuery: 'cheerio'
//OR
jQuery: {
name: 'cheerio',
options: {
normalizeWhitespace: true,
xmlMode: true
}
}
These parsing options are taken directly from htmlparser2, therefore any options that can be used in htmlparser2 are valid in cheerio as well. The default options are:
{
normalizeWhitespace: false,
xmlMode: false,
decodeEntities: true
}
For a full list of options and their effects, see this and htmlparser2's options. source
In order to work with JSDOM you will have to install it in your project folder npm install jsdom, and pass it to crawler.
var jsdom = require('jsdom');
var Crawler = require('crawler');
var c = new Crawler({
jQuery: jsdom
});
crawler use a local httpbin for testing purpose. You can install httpbin as a library from PyPI and run it as a WSGI app. For example, using Gunicorn:
$ pip install httpbin
# launch httpbin as a daemon with 6 worker on localhost
$ gunicorn httpbin:app -b 127.0.0.1:8000 -w 6 --daemon
# Finally
$ npm install && npm test
After installing Docker, you can run:
# Builds the local test environment
$ docker build -t node-crawler .
# Runs tests
$ docker run node-crawler sh -c "gunicorn httpbin:app -b 127.0.0.1:8000 -w 6 --daemon && cd /usr/local/lib/node_modules/crawler && npm install && npm test"
# You can also ssh into the container for easier debugging
$ docker run -i -t node-crawler bash
FAQs
Crawler is a ready-to-use web spider that works with proxies, asynchrony, rate limit, configurable request pools, jQuery, and HTTP/2 support.
The npm package crawler receives a total of 3,286 weekly downloads. As such, crawler popularity was classified as popular.
We found that crawler demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
We redesigned Socket's first logged-in page to display rich and insightful visualizations about your repositories protected against supply chain threats.

Product
Automatically fix and test dependency updates with socket fix—a new CLI tool that turns CVE alerts into safe, automated upgrades.

Security News
CISA denies CVE funding issues amid backlash over a new CVE foundation formed by board members, raising concerns about transparency and program governance.