

Product
Introducing Rust Support in Socket
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
By Trevor Norris - Jul 31, 2025
Supply Chain Security
Vulnerability
Quality
Maintenance
License
LZ4 is a very fast compression and decompression algorithm. This nodejs module provides a Javascript implementation of the decoder as well as native bindings to the LZ4 functions. Nodejs Streams are also supported for compression and decompression.
NB. Version 0.2 does not support the legacy format, only the one as of "LZ4 Streaming Format 1.4". Use version 0.1 if required.
With NodeJS:
git clone https://github.com/pierrec/node-lz4.git
cd node-lz4
git submodule update --init --recursive
npm install
With NodeJS:
npm install lz4
Within the browser, using build/lz4.js:
<script type="text/javascript" src="/path/to/lz4.js"></script>
<script type="text/javascript">
// Nodejs-like Buffer built-in
var Buffer = require('buffer').Buffer
var LZ4 = require('lz4')
// Some data to be compressed
var data = 'Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.'
data += data
// LZ4 can only work on Buffers
var input = Buffer.from(data)
// Initialize the output buffer to its maximum length based on the input data
var output = Buffer.alloc( LZ4.encodeBound(input.length) )
// block compression (no archive format)
var compressedSize = LZ4.encodeBlock(input, output)
// remove unnecessary bytes
output = output.slice(0, compressedSize)
console.log( "compressed data", output )
// block decompression (no archive format)
var uncompressed = Buffer.alloc(input.length)
var uncompressedSize = LZ4.decodeBlock(output, uncompressed)
uncompressed = uncompressed.slice(0, uncompressedSize)
console.log( "uncompressed data", uncompressed )
</script>
From github cloning, after having made sure that node and node-gyp are properly installed:
npm i
node-gyp rebuild
See below for more LZ4 functions.
There are 2 ways to encode:
First, create an LZ4 encoding NodeJS stream with LZ4#createEncoderStream(options).
options (Object): LZ4 stream options (optional)
options.blockMaxSize (Number): chunk size to use (default=4Mb)options.highCompression (Boolean): use high compression (default=false)options.blockIndependence (Boolean): (default=true)options.blockChecksum (Boolean): add compressed blocks checksum (default=false)options.streamSize (Boolean): add full LZ4 stream size (default=false)options.streamChecksum (Boolean): add full LZ4 stream checksum (default=true)options.dict (Boolean): use dictionary (default=false)options.dictId (Integer): dictionary id (default=0)The stream can then encode any data piped to it. It will emit a data event on each encoded chunk, which can be saved into an output stream.
The following example shows how to encode a file test into test.lz4.
var fs = require('fs')
var lz4 = require('lz4')
var encoder = lz4.createEncoderStream()
var input = fs.createReadStream('test')
var output = fs.createWriteStream('test.lz4')
input.pipe(encoder).pipe(output)
Read the data into memory and feed it to LZ4#encode(input[, options]) to decode an LZ4 stream.
input (Buffer): data to encodeoptions (Object): LZ4 stream options (optional)
options.blockMaxSize (Number): chunk size to use (default=4Mb)options.highCompression (Boolean): use high compression (default=false)options.blockIndependence (Boolean): (default=true)options.blockChecksum (Boolean): add compressed blocks checksum (default=false)options.streamSize (Boolean): add full LZ4 stream size (default=false)options.streamChecksum (Boolean): add full LZ4 stream checksum (default=true)options.dict (Boolean): use dictionary (default=false)options.dictId (Integer): dictionary id (default=0)var fs = require('fs')
var lz4 = require('lz4')
var input = fs.readFileSync('test')
var output = lz4.encode(input)
fs.writeFileSync('test.lz4', output)
There are 2 ways to decode:
First, create an LZ4 decoding NodeJS stream with LZ4#createDecoderStream().
The stream can then decode any data piped to it. It will emit a data event on each decoded sequence, which can be saved into an output stream.
The following example shows how to decode an LZ4 compressed file test.lz4 into test.
var fs = require('fs')
var lz4 = require('lz4')
var decoder = lz4.createDecoderStream()
var input = fs.createReadStream('test.lz4')
var output = fs.createWriteStream('test')
input.pipe(decoder).pipe(output)
Read the data into memory and feed it to LZ4#decode(input) to produce an LZ4 stream.
input (Buffer): data to decodevar fs = require('fs')
var lz4 = require('lz4')
var input = fs.readFileSync('test.lz4')
var output = lz4.decode(input)
fs.writeFileSync('test', output)
In some cases, it is useful to be able to manipulate an LZ4 block instead of an LZ4 stream. The functions to decode and encode are therefore exposed as:
LZ4#decodeBlock(input, output[, startIdx, endIdx]) (Number) >=0: uncompressed size, <0: error at offset
input (Buffer): data block to decodeoutput (Buffer): decoded data blockstartIdx (Number): input buffer start index (optional, default=0)endIdx (Number): input buffer end index (optional, default=startIdx + input.length)LZ4#encodeBound(inputSize) (Number): maximum size for a compressed block
inputSize (Number) size of the input, 0 if too large
This is required to size the buffer for a block encoded dataLZ4#encodeBlock(input, output[, startIdx, endIdx]) (Number) >0: compressed size, =0: not compressible
input (Buffer): data block to encodeoutput (Buffer): encoded data blockstartIdx (Number): output buffer start index (optional, default=0)endIdx (Number): output buffer end index (optional, default=startIdx + output.length)LZ4#encodeBlockHC(input, output) (Number) >0: compressed size, =0: not compressible
input (Buffer): data block to encode with high compressionoutput (Buffer): encoded data blockBlocks do not have any magic number and are provided as is. It is useful to store somewhere the size of the original input for decoding. LZ4#encodeBlockHC() is not available as pure Javascript.
blockIndependence property only supported for trueMIT
FAQs
LZ4 streaming compression and decompression
The npm package lz4 receives a total of 113,608 weekly downloads. As such, lz4 popularity was classified as popular.
We found that lz4 demonstrated a not healthy version release cadence and project activity because the last version was released a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Socket now supports Rust and Cargo, offering package search for all users and experimental SBOM generation for enterprise projects.
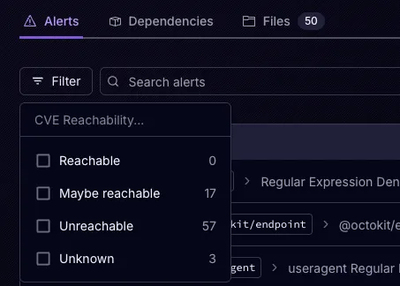
Product
Socket’s precomputed reachability slashes false positives by flagging up to 80% of vulnerabilities as irrelevant, with no setup and instant results.

Product
Socket is launching experimental protection for Chrome extensions, scanning for malware and risky permissions to prevent silent supply chain attacks.