
Product
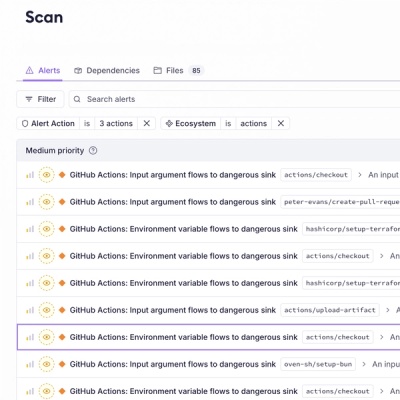
Introducing GitHub Actions Scanning Support
Detect malware, unsafe data flows, and license issues in GitHub Actions with Socket’s new workflow scanning support.
By Rakesh Chatrath, Greg Tystahl - Oct 23, 2025
static-sitemap-cli
Advanced tools
CLI to generate XML sitemaps for static sites from local filesystem

CLI to generate XML sitemaps for static sites from local filesystem.
Quick and easy CLI to generate XML or
TXT sitemaps by
searching your local filesystem for .html files. Automatically exclude files containing the
noindex meta. Can also be used as a Node module.
NOTE: This is the V2 branch. If you're looking for the older version, see the V1 branch. V2 contains breaking changes. Find out what changed on the releases page.
$ npm i -g static-sitemap-cli
$ sscli -b https://example.com -r public
This trawls the public/ directory for files matching **/*.html, then parses each file for the
noindex robots meta tag - excluding that file if the tag exists - and finally generates both
sitemap.xml and sitemap.txt into the public/ root.
See below for more usage examples.
Usage: sscli [options]
CLI to generate XML sitemaps for static sites from local filesystem
Options:
-b, --base <url> base URL (required)
-r, --root <dir> root working directory (default: ".")
-m, --match <glob...> globs to match (default: ["**/*.html"])
-i, --ignore <glob...> globs to ignore (default: ["404.html"])
-c, --changefreq <glob,changefreq...> comma-separated glob-changefreq pairs
-p, --priority <glob,priority...> comma-separated glob-priority pairs
--no-robots do not parse html files for noindex meta
--concurrent <max> concurrent number of html parsing ops (default: 32)
--no-clean do not use clean URLs
--slash add trailing slash to all URLs
-f, --format <format> sitemap format (choices: "xml", "txt", "both", default: "both")
-o, --stdout output sitemap to stdout instead
-v, --verbose be more verbose
-V, --version output the version number
-h, --help display help for command
By default, all matched .html files are piped through a fast
HTML parser to detect if the noindex
meta tag is
set - typically in the form of <meta name="robots" content="noindex" /> - in which case that file
is excluded from the generated sitemap. To disable this behaviour, pass option --no-robots.
For better performance, file reads are streamed in 1kb chunks, and parsing stops immediately when
either the noindex meta, or the </head> closing tag, is detected (the <body> is not parsed).
This operation is performed concurrently with an
async pool limit of 32. The limit can be tweaked using the
--concurrent option.
Hides the .html file extension in sitemaps like so:
./rootDir/index.html -> https://example.com/
./rootDor/foo/index.html -> https://example.com/foo
./rootDor/foo/bar.html -> https://example.com/foo/bar
Enabled by default; pass option --no-clean to disable.
Adds a trailing slash to all URLs like so:
./rootDir/index.html -> https://example.com/
./rootDir/foo/index.html -> https://example.com/foo/
./rootDir/foo/bar.html -> https://example.com/foo/bar/
Disabled by default; pass option --slash to enable.
NOTE: Cannot be used together with --no-clean. Also, trailing slashes are
always added to
root domains.
The -m and -i flags allow multiple entries. By default, they are set to the ["**/*.html"] and
["404.html"] respectively. Change the glob patterns to suit your use-case like so:
$ sscli ... -m '**/*.{html,jpg,png}' -i '404.html' 'ignore/**' 'this/other/specific/file.html'
The -c and -p flags allow multiple entries and accept glob-* pairs as input. A glob-* pair
is a comma-separated pair of <glob>,<value>. For example, a glob-changefreq pair may look like
this:
$ sscli ... -c '**,weekly' 'events/**,daily'
Latter entries override the former. In the above example, paths matching events/** have a daily
changefreq, while the rest are set to weekly.
Options can be passed through the sscli property in package.json, or through a .ssclirc JSON
file, or through other standard conventions.
$ sscli -b https://x.com -f txt -o
$ sscli -b https://x.com -r dist -f xml -o > www/sm.xml
$ sscli -b https://x.com/foo -r dist/foo -f xml -o > dist/sitemap.xml
$ sscli -b https://x.com -r dist -m '**/*.{jpg,jpeg,gif,png,bmp,webp,svg}' -f txt
static-sitemap-cli can also be used as a Node module.
import {
generateUrls,
generateXmlSitemap,
generateTxtSitemap
} from 'static-sitemap-cli'
const options = {
base: 'https://x.com',
root: 'path/to/root',
match: ['**/*html'],
ignore: ['404.html'],
changefreq: [],
priority: [],
robots: true,
concurrent: 32,
clean: true,
slash: false
}
generateUrls(options).then((urls) => {
const xmlString = generateXmlSitemap(urls)
const txtString = generateTxtSitemap(urls)
...
})
Using the XML sitemap generator by itself:
import { generateXmlSitemap } from 'static-sitemap-cli'
const urls = [
{ loc: 'https://x.com/', lastmod: '2022-02-22' },
{ loc: 'https://x.com/about', lastmod: '2022-02-22' },
...
]
const xml = generateXmlSitemap(urls)
Standard Github contribution workflow applies.
Test specs are at test/spec.js. To run the tests:
$ npm run test
ISC
Changes are logged in the releases page.
FAQs
CLI to generate XML sitemaps for static sites from local filesystem
We found that static-sitemap-cli demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Detect malware, unsafe data flows, and license issues in GitHub Actions with Socket’s new workflow scanning support.
Product
Add real-time Socket webhook events to your workflows to automatically receive pull request scan results and security alerts in real time.

Research
The Socket Threat Research Team uncovered malicious NuGet packages typosquatting the popular Nethereum project to steal wallet keys.