
Security News
MCP Steering Committee Launches Official MCP Registry in Preview
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
By Sarah Gooding - Sep 09, 2025
A Python library to extract data from Baidu Search Engine Results Pages (SERP) and output it as JSON objects.
pip install baidu-serp-api
from baidu_serp_api import BaiduPc, BaiduMobile
# Basic usage (default optimized for proxy rotation)
pc_serp = BaiduPc()
results = pc_serp.search('keyword', date_range='20240501,20240531', pn='2', proxies={'http': 'http://your-proxy-server:port'})
print(results)
m_serp = BaiduMobile()
results = m_serp.search('keyword', date_range='day', pn='2', proxies={'http': 'http://your-proxy-server:port'})
print(results)
# Filter the specified content. The following returned results do not contain 'recommend', 'last_page', 'match_count'
results = m_serp.search('关键词', exclude=['recommend', 'last_page', 'match_count'])
# Single connection mode (default, suitable for proxy rotation and scraping)
pc = BaiduPc(connection_mode='single')
# Connection pool mode (suitable for fixed proxy or high-performance scenarios)
pc = BaiduPc(connection_mode='pooled')
# Custom mode (fully customizable parameters)
pc = BaiduPc(
connection_mode='custom',
connect_timeout=5,
read_timeout=15,
pool_connections=5,
pool_maxsize=20,
keep_alive=True
)
# Get performance data
results = pc.search('keyword', include_performance=True)
if results['code'] == 200:
performance = results['data']['performance']
print(f"Response time: {performance['response_time']}s")
print(f"Status code: {performance['status_code']}")
# Manual resource management
pc = BaiduPc()
try:
results = pc.search('keyword')
finally:
pc.close() # Manually release resources
# Recommended: Use context manager
with BaiduPc() as pc:
results = pc.search('keyword')
# Automatically release resources
keyword: The search keyword.date_range (optional): Search for results within the specified date range. the format should be a time range string like '20240501,20240531', representing searching results between May 1, 2024, and May 31, 2024.pn (optional): Search for results on the specified page.proxies (optional): Use proxies for searching.exclude (optional): Exclude specified fields, e.g., ['recommend', 'last_page'].include_performance (optional): Whether to include performance data, default False.connection_mode: Connection mode, options:
'single' (default): Single connection mode, suitable for proxy rotation'pooled': Connection pool mode, suitable for high-performance scenarios'custom': Custom mode, use custom parametersconnect_timeout: Connection timeout in seconds, default 5read_timeout: Read timeout in seconds, default 10max_retries: Maximum retry count, default 0pool_connections: Number of connection pools, default 1pool_maxsize: Maximum connections per pool, default 1keep_alive: Whether to enable keep-alive, default FalseKey Request Parameters:
rsv_pq: Random query parameter (64-bit hex)rsv_t: Random timestamp hashoq: Original query (same as search keyword)Cookie Parameters (automatically generated):
BAIDUID: Unique browser identifier (32-char hex)H_PS_645EC: Synchronized with rsv_t parameterH_PS_PSSID: Session ID with multiple numeric segmentsBAIDUID_BFESS: Same as BAIDUID for securityKey Request Parameters:
rsv_iqid: Random identifier (19 digits)rsv_t: Random timestamp hashsugid: Suggestion ID (14 digits)rqid: Request ID (same as rsv_iqid)inputT: Input timestampCookie Parameters (automatically generated):
BAIDUID: Synchronized with internal parametersH_WISE_SIDS: Mobile-specific session with 80 numeric segmentsrsv_i: Complex encoded string (64 chars)__bsi: Special session ID formatFC_MODEL: Feature model parametersAll parameters are automatically generated and synchronized to ensure realistic browser behavior.
{'code': 200, 'msg': 'ok', 'data': {...}}: Successful response
results: Search results listrecommend: Basic recommendation keywords (may be empty array)ext_recommend: Extended recommendation keywords (mobile only, may be empty array)last_page: Indicates whether it's the last pagematch_count: Number of matching resultsperformance (optional): Performance data, contains response_time and status_code{'code': 404, 'msg': '未找到相关结果'}: No relevant results found{'code': 405, 'msg': '无搜索结果'}: No search results{'code': 500, 'msg': '请求异常'}: General network request exception{'code': 501, 'msg': '百度安全验证'}: Baidu security verification required{'code': 502, 'msg': '响应提前结束'}: Response data incomplete{'code': 503, 'msg': '连接超时'}: Connection timeout{'code': 504, 'msg': '读取超时'}: Read timeout{'code': 505-510}: Proxy-related errors (connection reset, auth failure, etc.){'code': 511-513}: SSL-related errors (certificate verification, handshake failure, etc.){'code': 514-519}: Connection errors (connection refused, DNS resolution failure, etc.){'code': 520-523}: HTTP errors (403 forbidden, 429 rate limit, server error, etc.)# Recommended configuration: default single mode is already optimized
with BaiduPc() as pc: # Automatically uses single connection to avoid connection reuse issues
for proxy in proxy_list:
results = pc.search('keyword', proxies=proxy)
# Process results...
# Use pooled mode for better performance
with BaiduPc(connection_mode='pooled') as pc:
results = pc.search('keyword', proxies=fixed_proxy)
# Connection pool automatically manages connection reuse
def robust_search(keyword, max_retries=3):
for attempt in range(max_retries):
with BaiduPc() as pc:
results = pc.search(keyword, include_performance=True)
if results['code'] == 200:
return results
elif results['code'] in [503, 504]: # Timeout errors
continue # Retry
elif results['code'] in [505, 506, 514, 515]: # Connection issues
continue # Retry
else:
break # Don't retry other errors
return results
Mobile version supports two types of recommendations:
recommend: Basic recommendation keywords extracted directly from search results pageext_recommend: Extended recommendation keywords obtained through additional API callHow to get extended recommendations:
# Get all recommendations (including extended recommendations)
results = m_serp.search('keyword', exclude=[])
# Get only basic recommendations (default behavior)
results = m_serp.search('keyword') # equivalent to exclude=['ext_recommend']
# Get no recommendations
results = m_serp.search('keyword', exclude=['recommend']) # automatically excludes ext_recommend
Notes:
This project is intended for educational purposes only and must not be used for commercial purposes or for large-scale scraping of Baidu data. This project is licensed under the GPLv3 open-source license. If other projects utilize the content of this project, they must be open-sourced and acknowledge the source. Additionally, the author of this project shall not be held responsible for any legal risks resulting from misuse. Violators will bear the consequences at their own risk.
FAQs
A library to extract data from Baidu SERP and output it as JSON objects
We found that baidu-serp-api demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 1 open source maintainer collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Security News
The MCP Steering Committee has launched the official MCP Registry in preview, a central hub for discovering and publishing MCP servers.
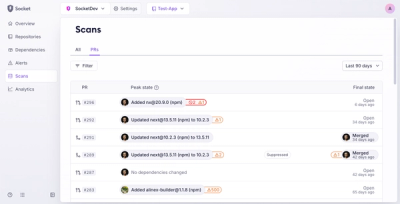
Product
Socket’s new Pull Request Stories give security teams clear visibility into dependency risks and outcomes across scanned pull requests.
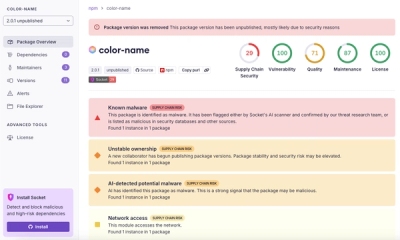
Research
/Security News
npm author Qix’s account was compromised, with malicious versions of popular packages like chalk-template, color-convert, and strip-ansi published.