==========
Bcselector
.. image:: https://raw.githubusercontent.com/Kaketo/bcselector/master/docs/img/logo_small.png
.. image:: https://img.shields.io/badge/python-3.7-blue.svg
:target: http://badge.fury.io/py/bcselector
.. image:: https://badge.fury.io/py/bcselector.svg
:target: https://badge.fury.io/py/bcselector
.. image:: https://travis-ci.com/Kaketo/bcselector.svg?branch=master
:target: https://travis-ci.com/Kaketo/bcselector
.. image:: https://codecov.io/gh/Kaketo/bcselector/branch/master/graph/badge.svg
:target: https://codecov.io/gh/Kaketo/bcselector
.. image:: https://img.shields.io/badge/License-MIT-yellow.svg
:target: https://opensource.org/licenses/MIT
What is it?
Feature selection is a crucial problem in many machine learning tasks. Usually the considered
variables are cheap to collect and store but in some situations the acquisition of feature values
can be problematic. For example, when predicting the occurrence of the disease we may consider
the results of some diagnostic tests which can be very expensive.
The existing feature selection methods usually ignore costs associated with the considered
features. The goal of cost- sensitive feature selection is to select a subset of features which allow
to predict the target variable (e.g. occurrence of the diseases) successfully within the assumed
budget.
The main purpose of this package is to provide filter methods of feature selection based
on information theory and to propose new variants of these methods considering feature costs.
Installation
bcselector can be installed from [PyPI] (https://pypi.org/project/bcselector)::
pip install bcselector
Quickstart
First of all we must have a dataset with classification target variable and a cost assigned to each feature.
Good sample data could be hepatitis <https://archive.ics.uci.edu/ml/citation_policy.html>_ from UCI repository [1].
Lets say that that we have dataset loaded to Python, we need to create Selector class and call fit method with proper arguments on it:
.. code-block:: python
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
from bcselector.variable_selection import FractionVariableSelector
from bcselector.datasets import load_sample
Arguments for feature selection
r - cost scaling parameter,
beta - kwarg for j_criterion_func,
model - model that is fitted on data.
r = 1
beta = 0.5
model = LogisticRegression(max_iter=1000)
Data
X,y,costs = load_sample()
Feature selection
fvs = FractionVariableSelector()
fvs.fit(data=X, target_variable=y, costs=costs, r=r, j_criterion_func='cife', beta=beta)
Now we can obtain feature selection results by calling simple getter:
.. code-block:: python
fvs.get_cost_results()
Or we can score and plot our results with any sklearn model and classification metric:
.. code-block:: python
fvs.score(model=model, scoring_function=roc_auc_score)
fvs.plot_scores(compare_no_cost_method=True, model=model, annotate=True)
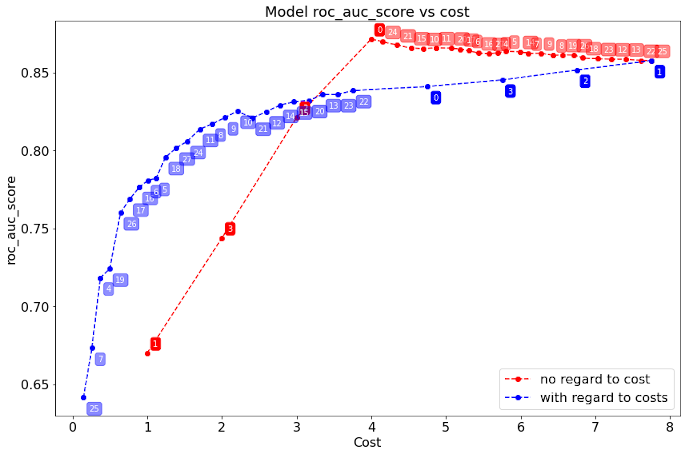
Which results in BC-plot:
.. image:: https://raw.githubusercontent.com/Kaketo/bcselector/master/docs/img/bc_plot.png
On OX axis we have accumulated cost and on OY axis we see test set score of currently selected set of features:
- Blue line is cost-sensitive method selected features order.
- Red line is NO-cost method selected features order.
- Blue vertical line is maximum budget avaliable (user parameter)
Small numbers above or below the curve are indexes of selected features. Therefore we can see that first variable selected by cost-sensitive method is on 14th column in dataset X.
Bibliography
- [1] Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Citations
TBD




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}