
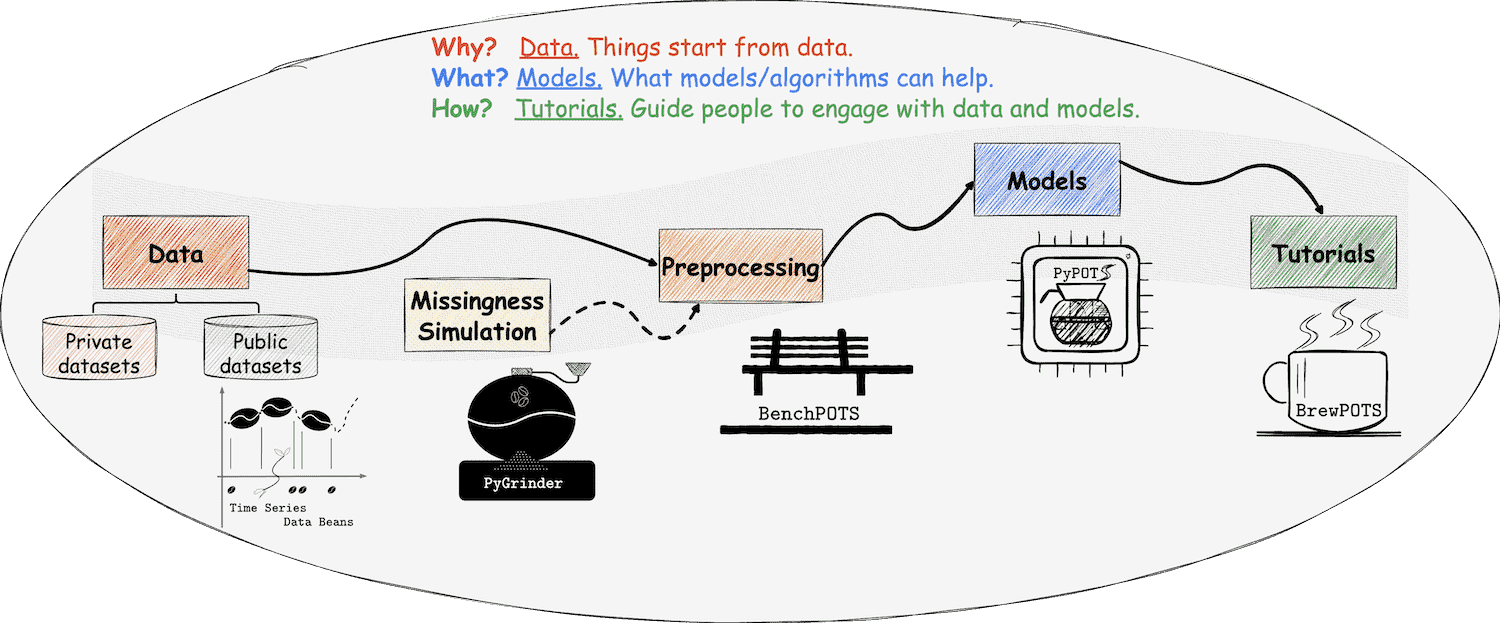
Welcome to BenchPOTS
a Python toolbox for benchmarking ML on POTS (Partially-Observed Time Series)













To evaluate the performance of algorithms on POTS datasets, a benchmarking toolkit is necessary, hence the ecosystem library BenchPOTS is developed.
BenchPOTS provides the standard and unified preprocessing pipelines of a variety of POTS datasets.
It supports a variety of evaluation tasks to help users understand the performance of different algorithms.
❖ Usage Examples
[!IMPORTANT]
BenchPOTS is available on both  and
and  ❗️
❗️
Install via pip:
pip install benchpots
or install from source code:
pip install https://github.com/WenjieDu/BenchPOTS/archive/main.zip
or install via conda:
conda install benchpots -c conda-forge
import benchpots
benchpots.datasets.preprocess_physionet2012(subset="all", rate=0.1)
❖ Citing BenchPOTS/PyPOTS
The paper introducing PyPOTS is available on arXiv,
A short version of it is accepted by the 9th SIGKDD international workshop on Mining and Learning from Time Series (MiLeTS'23)).
Additionally, PyPOTS has been included as a PyTorch Ecosystem project.
We are pursuing to publish it in prestigious academic venues, e.g. JMLR (track for
Machine Learning Open Source Software). If you use PyPOTS in your work,
please cite it as below and 🌟star this repository to make others notice this library. 🤗
There are scientific research projects using PyPOTS and referencing in their papers.
Here is an incomplete list of them.
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
journal={arXiv preprint arXiv:2305.18811},
year={2023},
}
or
Wenjie Du.
PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series.
arXiv, abs/2305.18811, 2023.
🏠 Visits




