
Product
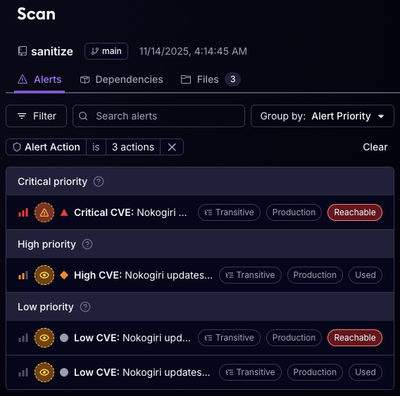
Reachability for Ruby Now in Beta
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
By Oskar Haarklou Veileborg - Nov 17, 2025
chatnoir-api
Advanced tools







 chatnoir-api
chatnoir-apiSimple, type-safe access to the ChatNoir search API.
Working with PyTerrier? Check out the chatnoir-pyterrier package.
Install the package from PyPI:
pip install chatnoir-api
The ChatNoir API offers two main features: search with BM25F and retrieving document contents.
You can use our Python client to search for documents.
The results object is an iterable wrapper of the search results which handles pagination for you.
List-style indexing is supported to access individual results or sub-lists of results:
from chatnoir_api.v1 import search
results = search("python library", api_key="<YOUR_API_KEY>")
top10_results = results[:10]
print(top10_results)
result_1234 = results[1234]
print(result_1234)
To limit your search requests to a single index (e.g., ClueWeb22 category B), set the index parameter like this:
from chatnoir_api.v1 import search
results = search("python library", index="clueweb22/b", api_key="<YOUR_API_KEY>")
To search for phrases, use the search_phrases method in the same way as normal search:
from chatnoir_api.v1 import search_phrases
results = search_phrases("python library")
The public, shared, default API key comes with a limited request budget. To use the ChatNoir API more extensively, please request a dedicated API key.
Then, use the api_key parameter to add it to your requests like this:
results = search("python library", api_key="<YOUR_API_KEY>")
Often the title and ID of a document is not enough to effectively re-rank a list of search results.
To retrieve the full content or plain text for a given document you can use the html_contents helper function.
The html_contents function expects a ChatNoir-internal UUID, shorthand UUID, or a TREC ID and the index from which to retrieve the document.
You can retrieve a document by its TREC ID like this:
from chatnoir_api import cache_contents, Index
contents = cache_contents(
"clueweb09-en0051-90-00849",
index="clueweb09",
)
print(contents)
plain_contents = cache_contents(
"clueweb09-en0051-90-00849",
index="clueweb09",
plain=True,
)
print(plain_contents)
For newer ChatNoir versions, you can also retrieve a document by its ChatNoir-internal short UUID like this:
from chatnoir_api import cache_contents, Index, ShortUUID
contents = cache_contents(
ShortUUID("MzOlTIayX9ub7c13GLPr_g"),
index="clueweb22/b",
)
print(contents)
plain_contents = cache_contents(
ShortUUID("MzOlTIayX9ub7c13GLPr_g"),
index="clueweb22/b",
plain=True,
)
print(plain_contents)
Head over to the ChatNoir ir_datasets indexer to learn more on how new ir_datasets-compatible datasets are indexed into ChatNoir.
If you use this package, please cite the paper from the ChatNoir authors. You can use the following BibTeX information for citation:
@InProceedings{bevendorff:2018,
address = {Berlin Heidelberg New York},
author = {Janek Bevendorff and Benno Stein and Matthias Hagen and Martin Potthast},
booktitle = {Advances in Information Retrieval. 40th European Conference on IR Research (ECIR 2018)},
editor = {Leif Azzopardi and Allan Hanbury and Gabriella Pasi and Benjamin Piwowarski},
month = mar,
publisher = {Springer},
series = {Lecture Notes in Computer Science},
site = {Grenoble, France},
title = {{Elastic ChatNoir: Search Engine for the ClueWeb and the Common Crawl}},
year = 2018
}
@InProceedings{merker:2025a,
address = {Cham, Switzerland},
author = {Jan Heinrich Merker and Janek Bevendorff and Maik Fr{\"o}be and Tim Hagen and Harrisen Scells and Matti Wiegmann and Benno Stein and Matthias Hagen and Martin Potthast},
booktitle = {Advances in Information Retrieval. 47th European Conference on IR Research (ECIR 2025)},
doi = {10.1007/978-3-031-88720-8_17},
editor = {Claudia Hauff and Craig Macdonal and Dietmar Jannach and Gabriella Kazai and Franco Maria Nardini and Fabio Pinelli and Fabrizio Silvestri and Nicola Tonellotto},
month = apr,
pages = {96--104},
publisher = {Springer Nature},
series = {Lecture Notes in Computer Science},
site = {Lucca, Italy},
title = {{Web-scale Retrieval Experimentation with chatnoir-pyterrier}},
volume = 15576,
year = 2025
}
To build this package and contribute to its development you need to install the build, and setuptools and wheel packages:
pip install build setuptools wheel
(On most systems, these packages are already pre-installed.)
Install package and test dependencies:
pip install -e .[tests]
Configure the API keys for testing:
export CHATNOIR_API_KEY="<API_KEY>"
export CHATNOIR_API_KEY_CHAT="<API_KEY>"
Verify your changes against the test suite to verify.
ruff check . # Code format and LINT
mypy . # Static typing
bandit -c pyproject.toml -r . # Security
pytest . # Unit tests
Please also add tests for your newly developed code.
Wheels for this package can be built with:
python -m build
If you hit any problems using this package, please file an issue. We're happy to help!
This repository is released under the MIT license.
FAQs
Simple, type-safe access to the ChatNoir search API.
We found that chatnoir-api demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Reachability analysis for Ruby is now in beta, helping teams identify which vulnerabilities are truly exploitable in their applications.
Research
/Security News
Malicious npm packages use Adspect cloaking and fake CAPTCHAs to fingerprint visitors and redirect victims to crypto-themed scam sites.

Security News
Recent coverage mislabels the latest TEA protocol spam as a worm. Here’s what’s actually happening.